浏览器在构造DOM树的同时也在构造着另一棵树-Render Tree,与DOM树相对应暂且叫它Render树吧,我们知道DOM树为javascript提供了一些列的访问接口(DOM API),但这棵树是不对外的。它的主要作用就是把HTML按照一定的布局与样式显示出来,用到了CSS的相关知识。从MVC的角度来说,可以将render树看成是V,dom树看成是M,C则是具体的调度者,比HTMLDocumentParser等。
新概念Render树
每一个Render树的节点称之为renderer或者render object,查看WEBKIT的源代码我们可以发现Renderer一个基础的类定义,这个类是所有renderer对象的基类。

class RenderObject{ virtual void layout(); virtual void paint(PaintInfo); virtual void rect repaintRect(); Node* node; //the DOM node RenderStyle* style; // the computed style RenderLayer* containgLayer; //the containing z-index layer }
从中我们可以发现renderer包含了一个dom对象以及为其计算好的样式规则,提供了布局以及显示方法。具体效果图如下:(firefox的Frames对应renderers,content对应dom)
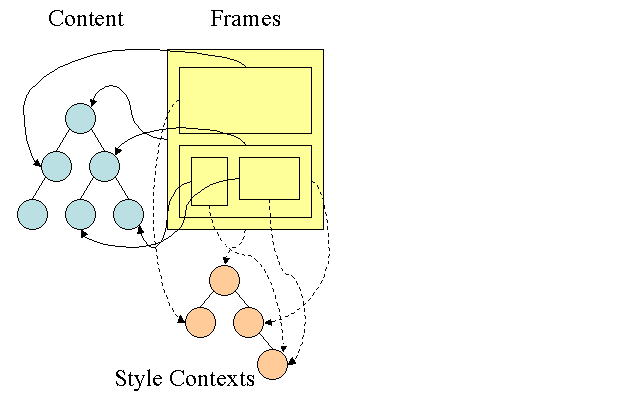
具体显示的时候,每一个renderer体现了一个矩形区块的东西,即我们常说的CSS盒子模型的概念,它本身包含了一些几何学相关的属性,如宽度width,高度height,位置position等。每一个renderer还有一个很重要的属性,就是如何显示它,display。我们知道元素的display有很多种,常见的就有none,inline,block,inline-block....,不同的display它们之间到底有啥不同呢?我们看一下代码:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style) { Document* doc = node->document(); RenderArena* arena = doc->renderArena(); ... RenderObject* o = 0; switch (style->display()) { case NONE: break; case INLINE: o = new (arena) RenderInline(node); break; case BLOCK: o = new (arena) RenderBlock(node); break; case INLINE_BLOCK: o = new (arena) RenderBlock(node); break; case LIST_ITEM: o = new (arena) RenderListItem(node); break; ... } return o; }
更详细的可见WEBKIT源码了,上面只是列出了片段。
DOM树与Render树
可以这么说,没有DOM树就没有Render树,但是它们之间可不是简单的一对一的关系。我们已经知道了render树是用于显示的,那不可见的元素当然不会在这棵树中出现了,譬如<header>,您还能想到哪些呢?除此之外,diplay等于none的也不会被显示在这棵树里头,但是visibility等于hidden的元素是会显示在这棵树里头的,可以自己想一下为什么。说了这么多render树,我们还没见一下它的真容呢,它到底会是个什么模样呢?我们看一下图。
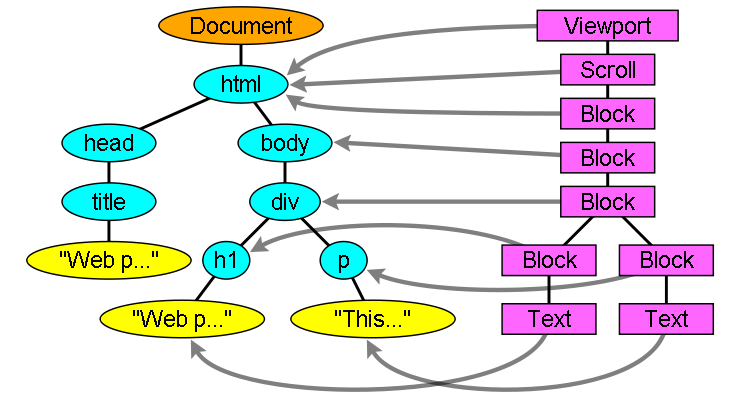
与DOM对象类型很丰富啊,什么head,title,div,而Render树相对来说就比较单一了,毕竟它的职责就是为了以后的显示渲染用嘛。从上图我们还可以看出,有些DOM元素没有对应的renderer,而有些DOM元素却对应了好几个renderer,对应多个renderer的情况是普遍存在的,就是为了解决一个renderer描述不清楚如何显示出来的问题,譬如select元素,我们就需要三个renderer,one for the display area, one for the drop down list box and one for the button。
上图中还有一种关系未可看出,即renderer与dom元素的位置也可能是不一样的。说的就是那些添加了float:ETC或者position:absolute的元素,因为它们脱离了正常的文档流顺序,构造Render树的时候会针对它们实际的位置进行构造。
DOM树可能会被我们随时更新,不仅限于解析阶段,譬如$elment.append啦或者$elment.addClass啦,我们看到页面立即进行了显示刷新,浏览器针对这种情况进行了相关处理。Dom树的根节点我们知道是doument,Render树的根节点不同浏览器可能有不同的叫法,webkit叫它RenderView,firefox叫它ViewPortFrame。
CSS的解析
CSS用到的所有词汇定义规范如下:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/ num [0-9]+|[0-9]*"."[0-9]+ nonascii [\200-\377] nmstart [_a-z]|{nonascii}|{escape} nmchar [_a-z0-9-]|{nonascii}|{escape} name {nmchar}+ ident {nmstart}{nmchar}* |
注:ident代表样式中的class,name代表样式中的id。
CSS用到的语法BNF格式的定义如下:
ruleset : selector [ ',' S* selector ]* '{' S* declaration [ ';' S* declaration ]* '}' S* ; selector : simple_selector [ combinator selector | S+ [ combinator selector ] ] ; simple_selector : element_name [ HASH | class | attrib | pseudo ]* | [ HASH | class | attrib | pseudo ]+ ; class : '.' IDENT ; element_name : IDENT | '*' ; attrib : '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S* [ IDENT | STRING ] S* ] ']' ; pseudo : ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ] ; |
样式计算
每个HTML元素上,我们可能定义了很多不同类型的样式,如字体啦,颜色啦,布局啦等等。即使元素上不被我们定义样式,浏览器或者用户个性设置也会为它默认创造一些样式。
样式计算一项极其复杂的过程,我们定义样式的时候可以采用类似类的定义方式为一批元素设置样式,但是解析构造renderer的时候,浏览器是为每一个构造样式定义的。我们可能定义了极其多的样式而且有各种不同的规则,那找到元素匹配的样式规则是挺困难的。浏览器有多重算法错误来实现计算工作,具体就不细分析了,一个元素最终经过计算可能匹配到了很多条样式规则,他们之间存在一定的优先顺序,从低到高有:
- 浏览器默认样式
- 用户个性化浏览器设置
- HTML开发者定义的一般样式
- HTML开发者定义的!important样式
- 用户个性化浏览器设置!important样式
更详细的优先计算公式
- count 1 if the declaration is from is a 'style' attribute rather than a rule with a selector, 0 otherwise (= a)
- count the number of ID attributes in the selector (= b)
- count the number of other attributes and pseudo-classes in the selector (= c)
- count the number of element names and pseudo-elements in the selector (= d)
具体可见http://www.w3.org/TR/CSS2/cascade.html#specificity
举例说明
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
布局
上面确定了renderer的样式规则后,然后就是重要的显示因素布局了。当renderer构造出来并添加到render树上之后,它并没有位置跟大小信息,为它确定这些信息的过程,我们就称之为布局。HTML采用了一种流式布局的布局模型,从上到下,从左到右顺序布局,布局的起点是从render树的根节点开始的,对应dom树的document节点,其初始位置为0,0,详细的布局过程为: 每个renderer的宽度由父节点的renderer确定。 父节点遍历子节点,确定子节点的位置(x,y),调用子节点的layout方法确定其高度。 父节点根据子节点的height,margin,padding确定自身的自身的高度。
为了避免因为局部小范围的DOM修改或者样式改变引起整个页面整体的布局重新构造,浏览器采用了一种dirty bit system的技术,使其尽可能的只改变元素本身或者包含的子元素的布局。当然有些情况无可避免的要重新构造整个页面的布局,如适合于整体的样式的改变影响了所有renderer,如body{font-size:111px} 字体大小发生了改变,还有一种情况就是浏览器窗口进行了调整,resize。
对于界面设计来说,一个页面最难搞的应该就是排版布局了,内容也比较多,我们下文进行说明