双链表
双端链表作为一种通用的数据结构,在Redis 内部使用得非常多:它既是Redis 列表结构的底
层实现之一,还被大量Redis 模块所使用,用于构建Redis 的其他功能。
应用
- 实现Redis 的列表类型;
双端链表还是Redis 列表类型的底层实现之一,当对列表类型的键进行操作——比如执行
RPUSH 、LPOP 或LLEN 等命令时,程序在底层操作的可能就是双端链表。
Redis 列表使用两种数据结构作为底层实现:
1. 双端链表
2. 压缩列表
因为双端链表占用的内存比压缩列表要多,所以当创建新的列表键时,列表会优先考虑使用压
缩列表作为底层实现,并且在有需要的时候,才从压缩列表实现转换到双端链表实现。
- Redis 自身功能的构建
除了实现列表类型以外,双端链表还被很多Redis 内部模块所应用:
- 事务模块使用双端链表来按顺序保存输入的命令;
- 服务器模块使用双端链表来保存多个客户端;
- 订阅/发送模块使用双端链表来保存订阅模式的多个客户端;
- 事件模块使用双端链表来保存时间事件(time event);
- 双端链表的实现
双端链表的实现由listNode 和list 两个数据结构构成,下图展示了由这两个结构组成的一
个双端链表实例:

迭代器
Redis 为双端链表实现了一个迭代器,这个迭代器可以从两个方向对双端链表进行迭代:
• 沿着节点的next 指针前进,从表头向表尾迭代;
• 沿着节点的prev 指针前进,从表尾向表头迭代;
typedef struct listIter {
// 下一节点
listNode *next;
// 迭代方向
int direction;
} listIter;
direction 记录迭代应该从那里开始:
• 如果值为adlist.h/AL_START_HEAD ,那么迭代器执行从表头到表尾的迭代;
• 如果值为adlist.h/AL_START_TAIL ,那么迭代器执行从表尾到表头的迭代;
字典
它是一种抽象数据结构,由一集键值对(key-value pairs)组成,各个键值对的键各不相同,程序可以将新的键值对添加到字典中,或者基于键进行查找、更新或删除等操作。
字典的应用
1. 实现数据库键空间(key space);
Redis 是一个键值对数据库,数据库中的键值对就由字典保存:每个数据库都有一个与之相对
应的字典,这个字典被称之为键空间(key space)。
当用户添加一个键值对到数据库时(不论键值对是什么类型),程序就将该键值对添加到键空
间;当用户从数据库中删除一个键值对时,程序就会将这个键值对从键空间中删除;等等。
2. 用作Hash 类型键的其中一种底层实现;
Redis 的Hash 类型键使用以下两种数据结构作为底层实现:
1. 字典;
2. 压缩列表;
因为压缩列表比字典更节省内存,所以程序在创建新Hash 键时,默认使用压缩列表作为底层
实现,当有需要时,程序才会将底层实现从压缩列表转换到字典。
Redis 选择了高效且实现简单的哈希表作为字典的底层实现。
字典的实现:
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
table 属性是一个数组,数组的每个元素都是一个指向dictEntry 结构的指针。
每个dictEntry 都保存着一个键值对,以及一个指向另一个dictEntry 结构的指针:
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
1.3. 字典15
Redis 设计与实现, 第一版
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 链往后继节点
struct dictEntry *next;
} dictEntry;


在上图的字典示例中,字典虽然创建了两个哈希表,但正在使用的只有0 号哈希表,这说明字典未进行rehash 状态。
碰撞的处理方法:
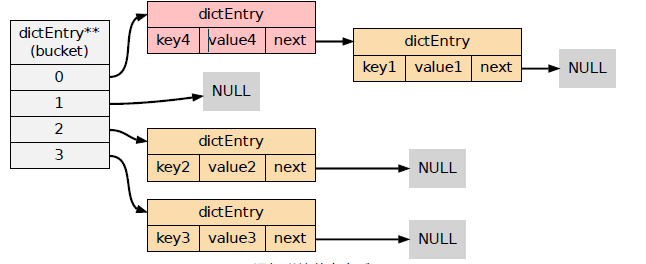
假设现在有三个借点的哈希表如下:

对于一个新的键值对key4 和value4 ,如果key4 的哈希值和key1 的哈希值相同,那么它们
将在哈希表的0 号索引上发生碰撞。通过将key4-value4 和key1-value1 两个键值对用链表连接起来,就可以解决碰撞的问题:
添加新键值对时触发了rehash 操作:
对于使用链地址法来解决碰撞问题的哈希表dictht 来说,哈希表的性能依赖于它的大小(size
属性)和它所保存的节点的数量(used 属性)之间的比率:
• 比率在1:1 时,哈希表的性能最好;
• 如果节点数量比哈希表的大小要大很多的话,那么哈希表就会退化成多个链表,哈希表
本身的性能优势就不再存在;

为了在字典的键值对不断增多的情况下保持良好的性能,字典需要对所使用的哈希表(ht[0])进行rehash 操作:在不修改任何键值对的情况下,对哈希表进行扩容,尽量将比率维持在1:1
左右。
dictAdd 在每次向字典添加新键值对之前,都会对哈希表ht[0] 进行检查,对于ht[0] 的
size 和used 属性,如果它们之间的比率ratio = used / size 满足以下任何一个条件的话,
rehash 过程就会被激活:
1. 自然rehash :ratio >= 1 ,且变量dict_can_resize 为真。
2. 强制rehash : ratio 大于变量dict_force_resize_ratio (目前版本中,
dict_force_resize_ratio 的值为5 )。
Note: 什么时候dict_can_resize 会为假?
一个数据库就是一个字典,数据库里的哈希类型键
也是一个字典,当Redis 使用子进程对数据库执行后台持久化任务时(比如执行BGSAVE
或BGREWRITEAOF 时), 为了最大化地利用系统的copy on write 机制, 程序会暂时将
dict_can_resize 设为假,避免执行自然rehash ,从而减少程序对内存的触碰(touch)。
当持久化任务完成之后,dict_can_resize 会重新被设为真。
字典的rehash 操作实际上就是执行以下任务:
1. 创建一个比ht[0]->table 更大的ht[1]->table ;
2. 将ht[0]->table 中的所有键值对迁移到ht[1]->table ;
3. 将原有ht[0] 的数据清空,并将ht[1] 替换为新的ht[0] ;
经过以上步骤之后,程序就在不改变原有键值对数据的基础上,增大了哈希表的大小。
渐进式rehash
渐进式rehash 主要由_dictRehashStep 和dictRehashMilliseconds 两个函数进行:
• _dictRehashStep 用于对数据库字典、以及哈希键的字典进行被动rehash ;
• dictRehashMilliseconds 则由Redis 服务器常规任务程序(server cron job)执行,用
于对数据库字典进行主动rehash ;
字典的收缩
收缩rehash 和上面展示的扩展rehash 的操作几乎一样,它执行以下步骤:
1. 创建一个比ht[0]->table 小的ht[1]->table ;
2. 将ht[0]->table 中的所有键值对迁移到ht[1]->table ;
3. 将原有ht[0] 的数据清空,并将ht[1] 替换为新的ht[0] ;
扩展rehash 和收缩rehash 执行完全相同的过程,一个rehash 是扩展还是收缩字典,关键在于
新分配的ht[1]->table 的大小:
字典的收缩规则由redis.c/htNeedsResize 函数定义:
/*
* 检查字典的使用率是否低于系统允许的最小比率
**
是的话返回1 ,否则返回0 。
*/
int htNeedsResize(dict *dict) {
long long size, used;
// 哈希表已用节点数量
size = dictSlots(dict);
// 哈希表大小
used = dictSize(dict);
// 当哈希表的大小大于DICT_HT_INITIAL_SIZE
// 并且字典的填充率低于REDIS_HT_MINFILL 时
// 返回1
return (size && used && size > DICT_HT_INITIAL_SIZE &&
(used*100/size < REDIS_HT_MINFILL));
}
在默认情况下,REDIS_HT_MINFILL 的值为10 ,也即是说,当字典的填充率低于10% 时,程
序就可以对这个字典进行收缩操作了。
字典的其他操作和字典的迭代.....(略)
跳跃表(很牛逼的一种表)....(略)
操作有ZADD ZRANGE等。