使用方法
使用方法
或|,点.,加+,乘*,在字符串中出现时,如果这个字符串需要被split,则split时候,需要在前面加两个反斜杠。
与&,在split时候,不需要转义。
一.java split
1. java split简单用法
//一般分隔符 " " String a="hello world ni hao"; String[] array1=a.split(" "); System.out.println(array1[0]); System.out.println(array1.length);
2.字符串末尾分隔符不能识别
1)字符串末尾的分隔符不能被识别
String a="hello,world,ni,hao,,,,,"; String[] array1=a.split(","); System.out.println(array1[0]); System.out.println(array1.length);
====结果====
hello
4
2).最后两个字符中间有空格
//字符串末尾的分隔符不能被识别 String a="hello,world,ni,hao,,,, ,"; String[] array1=a.split(","); System.out.println(array1[0]); System.out.println(array1.length);
====结果====
hello 8
3).中间的字符中间有空格
//字符串末尾的分隔符不能被识别 String a="hello,world,ni,hao,, ,,,"; String[] array1=a.split(","); System.out.println(array1[0]); System.out.println(array1.length); ====结果==== hello 6
请注意此时的split()方法并不会识别末尾的字符,并分割,当要分割的字符串末尾数据为空时,应注意避免使用此方法,
split()方法可以把字符串直接分割为数组此方法有两个重载。
一是:split(regex),参数为要分隔的字符串或者正则表达式。
二是:ss.split(regex, limit)。此方法可以的第二个参数一般不太常用,
这两个方法api给的解释是:limit 参数控制模式应用的次数,因此影响所得数组的长度。
如果该限制 n 大于 0,则模式将被最多应用 n - 1 次,数组的长度将不会大于 n,而且数组的最后一项将包含所有超出最后匹配的定界符的输入。
如果 n 为非正,那么模式将被应用尽可能多的次数,而且数组可以是任何长度。
如果 n 为 0,那么模式将被应用尽可能多的次数,数组可以是任何长度,并且结尾空字符串将被丢弃。
4)-1和5等效
String a="hello,world,ni,hao,"; //String[] array1=a.split(",",-1); String[] array1=a.split(",",5); System.out.println(array1[0]); System.out.println(array1.length);
====结果
hello
5
3 特殊符号的分割
String a="hello|world|ni|hao"; String[] array1=a.split("|"); System.out.println(array1[0]); System.out.println(array1.length);
h
18
上面中竖线时特殊符号,应用右双斜杠转译后再分割 ,如下:
String a="hello|world|ni|hao|"; String[] array1=a.split("\|",-1); System.out.println(array1[0]); System.out.println(array1.length);
hello
5
4 自定义split()方法,java中原生的split方法分割较长字符串时是比较低效的,需要自己重写split()方法,我自己写的分割方法如下(利用indexof)
public static String[] newsplit(String strInfo, String strSplit) { // 第1步计算数组大小 int size = 0; int index = 0; do { size++; index++; index = strInfo.indexOf(strSplit, index); } while (index != -1); String[] arrRtn = new String[size]; // 返回数组 // ------------------------------------------------------- // 第2步给数组赋值 int startIndex = 0; int endIndex = 0; for (int i = 0; i < size; i++) { endIndex = strInfo.indexOf(strSplit, startIndex); if (endIndex == -1) { arrRtn[i] = strInfo.substring(startIndex); } else { arrRtn[i] = strInfo.substring(startIndex, endIndex); } startIndex = endIndex + 1; } return arrRtn; }
且此方法不需要转译特殊字符,因为原生split方法同样识别正则表达式,所以不是识别特殊字符
二.org.apache.commons.lang3.StringUtils;
当你需要更高效的split方法时,StringUtils.split(str,"") 方法同样可用,比原生的split高效,该方法来自 apache-common的jar包,我用的是
commons-lang3-3.0.1.jar的包,但要注意StringUtils.split()对于字符串开头和结尾的分割符不识别,会默认省去,
StringUtils.split(str, separatorChars, max)
max:最多分割的项数,对于字符串开头和结尾的分割符不识别,会默认省去
当max<=0时无效。当max>0时为最多的分割项数。
String string = "hello,world,ni,hao,"; String[] strings = StringUtils.split(string, ",",0); System.out.println(strings.length); for (String string2 : strings) { System.out.println(string2); }
String string = "hello,world,ni,hao,"; String[] strings = StringUtils.split(string, ",",4); System.out.println(strings.length); for (String string2 : strings) { System.out.println(string2); }
4
hello
world
ni
hao,
三 java.util.StringTokenizer;(不需要用转义字符)
虽然StringTokenizer用起来很方便,但它的功能却很有限。这个类只是简单地在输入字符串中查找分隔符,一旦找到了分隔符就分割字符串。它不会检查分隔符是否在子串之中这类条件,当输入字符串中出现两个连续的分隔符时,它也不会返回""(字符串长度为0)形式的标记。
对于字符串开头和结尾的分割符不识别,会默认省去(可以不用转义字符),多个连续分隔符,也不会处理,
例如
String str = "hello|world|ni|hao|||aa|"; StringTokenizer st = new StringTokenizer(str, "|"); while (st.hasMoreTokens()) { System.out.println("=== : "+st.nextToken()); }
=== : hello
=== : world
=== : ni
=== : hao
=== : aa
只有下边这种标准格式才能被正常解析:
String str="hello|world|ni|hao"; StringTokenizer st = new StringTokenizer(str, "|"); String[] strs =new String[st.countTokens()]; int count = 0; while (st.hasMoreTokens()) { strs[count++] =st.nextToken(); } for (String string : strs) { System.out.println(string); }
完美 解决办法 :
public static final int MAXRESULT = 11; public static final String DELIMIT ="|"; // convert line String to Device object public static String[] convertStringToDevice(String lineInfo){ StringTokenizer st = new StringTokenizer(lineInfo, DELIMIT,true); String[] infos = new String[MAXRESULT]; int i = 0; while (st.hasMoreTokens()) { String temp = st.nextToken(); if(temp == null ||"null".equals(temp)){ temp = ""; } if("|".equals(temp)){ if(i++>MAXRESULT){ throw new IllegalArgumentException("Input line has too many fields :" + lineInfo ); } continue; } infos[i] = temp; } return infos; }
StringTokenizer有两个常用的方法:
1.hasMoreElements()。这个方法和hasMoreTokens()方法的用法是一样的,只是StringTokenizer为了实现Enumeration接口而实现的方法,从StringTokenizer的声明可以看到:class StringTokenizer implements Enumeration<Object>。
2.nextElement()。这个方法和nextToken()方法的用法是一样的,返回此 StringTokenizer 的下一个标记。
StringTokenizer的三个构造方法:
1.StringTokenizer(String str)。默认以” f”(前有一个空格,引号不是)为分割符。
//源码: public StringTokenizer(String str) { this(str, ” f”, false); }
public static void main(String[] args) { StringTokenizer st = new StringTokenizer("www ooobj com"); while(st.hasMoreElements()){ System.out.println("Token:" + st.nextToken()); } }
2.StringTokenizer(String str, String delim)。指定delim为分割符,看第一个例子。
3.StringTokenizer(String str, String delim, boolean returnDelims)。returnDelims为true的话则delim分割符也被视为标记。
//实例: public static void main(String[] args) { StringTokenizer st = new StringTokenizer("www.ooobj.com", ".", true); while(st.hasMoreElements()){ System.out.println("Token:" + st.nextToken()); } } //输出: Token:www Token:. Token:ooobj Token:. Token:com
四.c3p0 jar 下的 com.mchange.v1.util.StringTokenizerUtils 可以不用转义字符,内部是对StringTokenizer封装;
源码
/* * Distributed as part of c3p0 v.0.9.1.2 * * Copyright (C) 2005 Machinery For Change, Inc. * * Author: Steve Waldman <swaldman@mchange.com> * * This library is free software; you can redistribute it and/or modify * it under the terms of the GNU Lesser General Public License version 2.1, as * published by the Free Software Foundation. * * This software is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU Lesser General Public License for more details. * * You should have received a copy of the GNU Lesser General Public License * along with this software; see the file LICENSE. If not, write to the * Free Software Foundation, Inc., 59 Temple Place, Suite 330, * Boston, MA 02111-1307, USA. */ package com.mchange.v1.util; import java.util.StringTokenizer; public final class StringTokenizerUtils { public static String[] tokenizeToArray(String str, String delim, boolean returntokens) { StringTokenizer st = new StringTokenizer(str, delim, returntokens); String[] strings = new String[st.countTokens()]; for (int i = 0; st.hasMoreTokens(); ++i) strings[i] = st.nextToken(); return strings; } public static String[] tokenizeToArray(String str, String delim) {return tokenizeToArray(str, delim, false);} public static String[] tokenizeToArray(String str) {return tokenizeToArray(str, " ");} }
用法
String str="hello|world|ni|hao|||"; String[] strs =StringTokenizerUtils.tokenizeToArray(str, "|"); System.out.println(strs.length); for (String string : strs) { System.out.println(string); }
4
hello
world
ni
hao
String str="hello|world|ni|hao|||"; String[] strs =StringTokenizerUtils.tokenizeToArray(str, "|",true); System.out.println(strs.length); for (String string : strs) { System.out.println(string); }
10 hello | world | ni | hao | | |
五.java.util.regex.Pattern;特殊符号需要使用转义字符
String str="hello|world|ni|hao|||"; Pattern pattern = Pattern.compile("\|"); String[] string = pattern.split(str); for (String string2 : string) { System.out.println(string2); }
六.使用substring
String str = "hello|world|ni|hao"; int len = str.lastIndexOf("|"); int k = 0,count = 0; for (int i = 0; i <= len; i++) { if("|".equals(str.substring(i,i+1))){ if(count ==0){ System.out.println(str.substring(0,i)); }else{ System.out.println(str.substring(k+1,i)); if(i == len){ System.out.println(str.substring(len+1,str.length())); } } k=i; count++; } }
hello
world
ni
hao
七.通过charAt和substring这两个方法实现字符串分割
public static String[] splitByCharAt(String str, char regx) { //字符串截取的开始位置 int begin = 0; //截取分割得到的字符串 String splitStr = ""; ArrayList<String> result = new ArrayList<String>(); int length = str.length(); //计数器 int i = 0; for (i = 0; i < length;i++ ) { if (str.charAt(i) == regx) { splitStr = str.substring(begin, i); result.add(splitStr); str = str.substring(i + 1, length); length = str.length(); i = 0; } } if (!StringUtil.isBlank(str)) { result.add(str); } String[] strs = new String[result.size()]; return result.toArray(strs); }
一.subString、split、stringTokenizer三种截取字符串方法的性能比较
改变目标数据长度修改getOriginStr的len参数即可。
5组测试数据结果如下图:

下面这张图对比了下,split耗时为substring和StringTokenizer耗时的倍数:
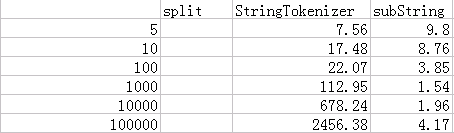
好吧,我又花了点儿时间,做了几张图表来分析这3中方式的性能。
首先来一张柱状图对比一下这5组数据截取所花费的时间:
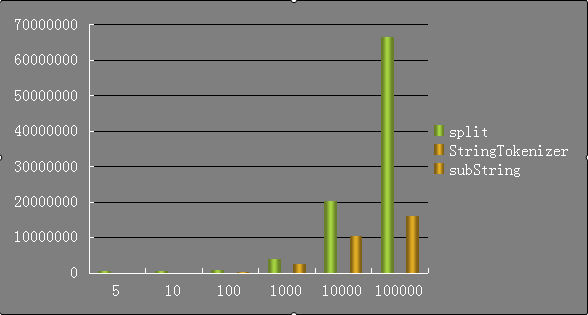
从上图可以看出StringTokenizer的性能实在是太好了(对比另两种),几乎在图表中看不见它的身影。遥遥领先。substring花费的时间始终比split要少,但是耗时也在随着数据量的增加而增加。
下面3张折线图可以很明显看出split、substring、StringTokenizer3中实现随着数据量增加,耗时的趋势。
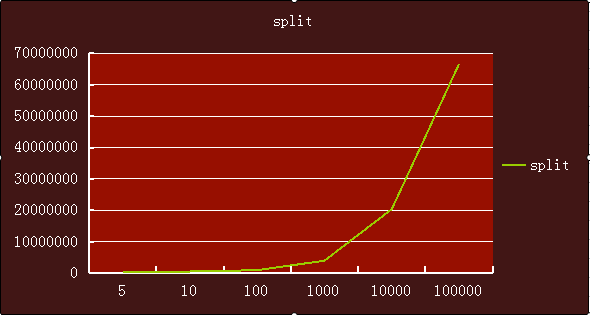
split是变化最大的,也就是数据量越大,截取所需要的时间增长越快。
substring则比split要平稳一点点,但是也在增长。
使用String的两个方法—indexOf()和subString(),subString()是采用了时间换取空间技术,因此它的执行效率相对会很快,只要处理好内存溢出问题,但可大胆使用。而indexOf()函数是一个执行速度非常快的方法,
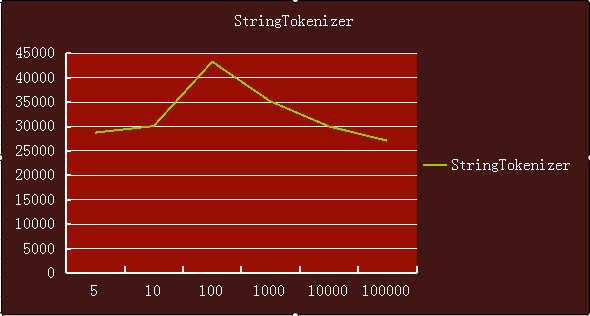
StringTokenizer则是表现最优秀的,基本上平稳,始终保持在5000ns一下。
结论
最终,StringTokenizer在截取字符串中效率最高,不论数据量大小,几乎持平。substring则要次之,数据量增加耗时也要随之增加。split则是表现最差劲的。
究其原因,split的实现方式是采用正则表达式实现,所以其性能会比较低。至于正则表达式为何低,还未去验证。split源码如下:
public String[] split(String regex, int limit) { return Pattern.compile(regex).split(this, limit); }
二.综合比较
使用jdk的split切分字符串
192 168 20 121 花费时间1086171
使用common的split切分字符串
192 168 20 121 花费时间9583620
使用StringTokenizer的切分字符串
192 168 20 121 花费时间184380
使用jdk的pattern切分字符串
192 168 20 121 花费时间222654
使用jdk的substring切分字符串
192 168 20 121 花费时间157562
虽然每次打印的时间不太相同,但是基本相差不大。
通过以上分析得知使用substring和StringTokenizer的效率相对较高,其它相对较差。
为什么StringTokenizer的性能相对好些呢?通过分析发现
StringTokener.hasMoreElement和String.split(String.split是用正则表达式匹配,所以不使用KMP字符串匹配算法)用的都是按顺序遍历的算法,时间复杂度O(m*n),较高。
不过StringTokener是一边按顺序遍历,一边返回每个分组;而Spring.split是全部分组完成,再返回字符串数组。这个区别不大,但是如果我们不需要全部都分组,只需要某个分组的字符串,那么StringTokener性能会好点。
apacheJakatar的StringUtils一样用了KMP算法(按序查找字符串,时间是O(m+n)),按理说效率应该最高,但是为啥性能会比较差呢,需要进一步研究。不过有一个优点是如果使用一些转义字符
如“.”、“|”等不需要加"\",如果使用jdk的split必须加转义。