有状态的流处理
什么是状态?
虽然数据流中的许多操作一次只看一个单独的事件(例如事件解析器),但有些操作会记住多个事件的信息(例如窗口操作符)。这些操作被称为有状态操作。
一些有状态操作的例子。
- 当一个应用程序搜索某些事件模式时,状态将存储到目前为止遇到的事件序列。
- 当按分钟/小时/天聚合事件时,状态会保存待聚合的事件。
- 当在数据点流上训练机器学习模型时,状态会保存模型参数的当前版本。
- 当需要管理历史数据时,状态可以有效访问过去发生的事件。
Flink需要了解状态,以便使用检查点和保存点使其具有容错性。
关于状态的知识还允许重新缩放Flink应用,这意味着Flink负责在并行实例之间重新分配状态。
可查询状态允许你在运行时从Flink外部访问状态。
在处理状态时,阅读一下Flink的状态后端可能也很有用。Flink提供了不同的状态后端,指定了状态的存储方式和位置。
键值状态
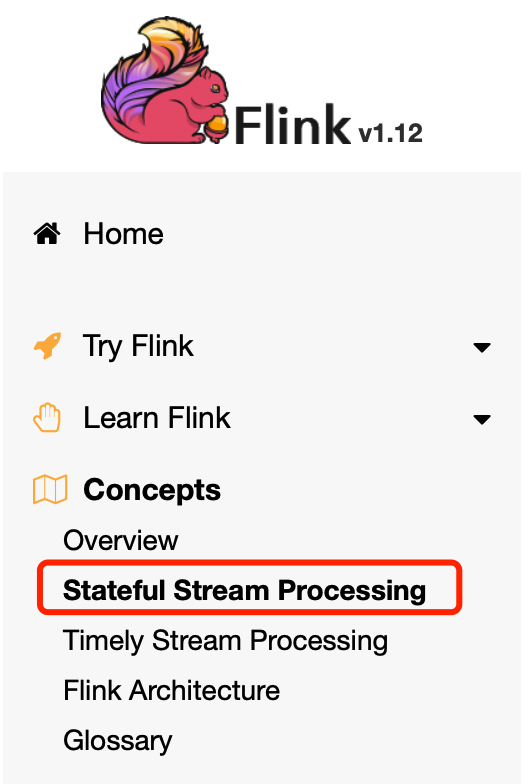
键值状态被维护在可以被认为是一个嵌入式键/值存储中。该状态严格地与有状态操作者读取的流一起被分割和分配。因此,对密钥/值状态的访问只有在密钥化的流上,即在密钥化/分区数据交换之后才有可能,并且仅限于与当前事件的密钥相关联的值。将流和状态的键对齐,可以确保所有的状态更新都是本地操作,保证了一致性,而没有事务开销。这种对齐方式还允许Flink透明地重新分配状态和调整流分区。
Keyed State被进一步组织成所谓的Key Groups。Key Groups是Flink可以重新分配Keyed State的原子单位;Key Groups的数量正好与定义的最大并行度相同。在执行过程中,键控操作符的每个并行实例都与一个或多个Key Groups的键一起工作。
状态持久性
Flink使用流重放和检查点的组合来实现容错。一个检查点标记了每个输入流中的一个特定点以及每个操作者的相应状态。通过恢复运算符的状态,从检查点开始重放记录,可以从检查点恢复流数据流,同时保持一致性(精确的一次处理语义)。
检查点间隔是用恢复时间(需要重放的记录数量)来交换执行过程中容错的开销的一种手段。
容错机制不断地绘制分布式流数据流的快照。对于状态较小的流媒体应用,这些快照非常轻量级,可以频繁地绘制,而不会对性能产生太大的影响。流应用的状态存储在一个可配置的地方,通常是在一个分布式文件系统中。
在程序失败的情况下(由于机器、网络或软件故障),Flink会停止分布式流数据流。然后系统会重新启动操作者,并将其重置到最新的成功检查点。输入流被重置到状态快照的点。作为重新启动的并行数据流的一部分处理的任何记录都保证不影响之前的检查点状态。
注释 默认情况下,检查点被禁用。有关如何启用和配置检查点的详细信息,请参见检查点。
注释 为了实现这种机制的完全保证,数据流源(如消息队列或broker)需要能够将数据流倒退到一个定义的最近点。Apache Kafka具有这种能力,Flink的Kafka连接器利用了这一点。参见数据源和汇的容错保证,了解更多关于Flink连接器提供的保证的信息。
注释 因为Flink的检查点是通过分布式快照实现的,所以我们互换使用快照和检查点这两个词。通常我们也使用术语快照来表示检查点或保存点。
检查点
Flink容错机制的核心部分是绘制分布式数据流和操作员状态的一致快照。这些快照作为一致的检查点,系统在发生故障时可以回退。Flink绘制这些快照的机制在 "Lightweight Asynchronous Snapshots for Distributed Dataflows "中描述。它的灵感来自于分布式快照的标准Chandy-Lamport算法,并专门为Flink的执行模型量身定做。
请记住,所有与检查点有关的事情都可以异步完成。检查点障碍不按锁步走,操作可以异步快照其状态。
自Flink 1.11以来,检查点可以在有或没有对齐的情况下进行。在本节中,我们先介绍对齐的检查点。
屏障
Flink的分布式快照中的一个核心元素是流壁垒。这些障碍被注入到数据流中,并作为数据流的一部分与记录一起流动。屏障永远不会超越记录,它们严格按照线路流动。屏障将数据流中的记录分为进入当前快照的记录集和进入下一个快照的记录。每个屏障都带有其记录被推到前面的快照的ID。屏障不会中断数据流的流动,因此非常轻量级。不同快照的多个屏障可以同时出现在流中,这意味着不同的快照可以同时发生。

流障碍是在流源处注入并行数据流。快照n的障碍被注入的点(我们称它为Sn)是源流中快照覆盖数据的位置。例如,在Apache Kafka中,这个位置将是分区中最后一条记录的偏移。这个位置Sn被报告给检查点协调器(Flink的JobManager)。
然后,障碍就会流向下游。当一个中间操作者从它的所有输入流中接收到一个快照n的障碍时,它就会向它的所有输出流中发出一个快照n的障碍。一旦一个汇操作者(流DAG的末端)从它的所有输入流中接收到屏障n,它就会向检查点协调器确认该快照n。在所有的汇确认了一个快照之后,它就被认为完成了。
一旦快照n完成后,作业再也不会向源头询问Sn之前的记录,因为此时这些记录(以及它们的子孙记录)将通过整个数据流拓扑。
接收多个输入流的操作员需要将输入流对准快照屏障。上图就说明了这一点。
一旦操作者从一个输入流中接收到快照屏障n,它就不能再处理该流的任何记录,直到它也从其他输入中接收到屏障n。否则,它就会把属于快照n的记录和属于快照n+1的记录混在一起。
一旦最后一个流收到了屏障n,操作者就会发出所有的待发记录,然后自己发出快照n的屏障。
它快照状态并恢复处理所有输入流的记录,在处理流的记录之前,先处理输入缓冲区的记录。
最后,操作者将状态异步写入状态后端。
需要注意的是,所有具有多个输入的操作者和洗牌后的操作者在消耗多个上游子任务的输出流时,都需要进行对齐。
快照操作符状态
当操作符包含任何形式的状态时,这个状态也必须是快照的一部分。
操作符在从输入流接收到所有快照障碍后,在向输出流发出障碍之前,在这个时间点快照其状态。这时,所有来自障碍之前的记录对状态的更新都已经进行了,而没有依赖于障碍之后的记录的更新。由于快照的状态可能很大,所以它被存储在一个可配置的状态后端。默认情况下,这是JobManager的内存,但对于生产使用,应该配置一个分布式的可靠存储(如HDFS)。状态存储完毕后,操作者确认检查点,向输出流发出快照屏障,然后继续进行。
现在产生的快照包含。
对于每个并行流数据源,当快照开始时,流中的偏移量/位置。
对于每个操作者,一个指向作为快照的一部分存储的状态的指针。

恢复
这种机制下的恢复是直接的。系统会重新部署整个分布式数据流,并给每个操作者提供快照的状态,作为检查点k的一部分。 来源被设置为从位置Sk开始读取数据流。例如在Apache Kafka中,这意味着告诉消费者从偏移量Sk开始获取。
如果状态是增量快照的,则运算符从最新的完整快照的状态开始,然后对该状态应用一系列增量快照更新。
更多信息请参见重启策略。
不对齐检查点
从Flink 1.11开始,检查点也可以在不对齐的情况下进行。基本思路是,只要飞行中的数据成为操作者状态的一部分,检查点就可以覆盖所有飞行中的数据。
请注意,这种方法实际上更接近Chandy-Lamport算法 ,但Flink仍然在源中插入屏障,以避免超载检查点协调器。
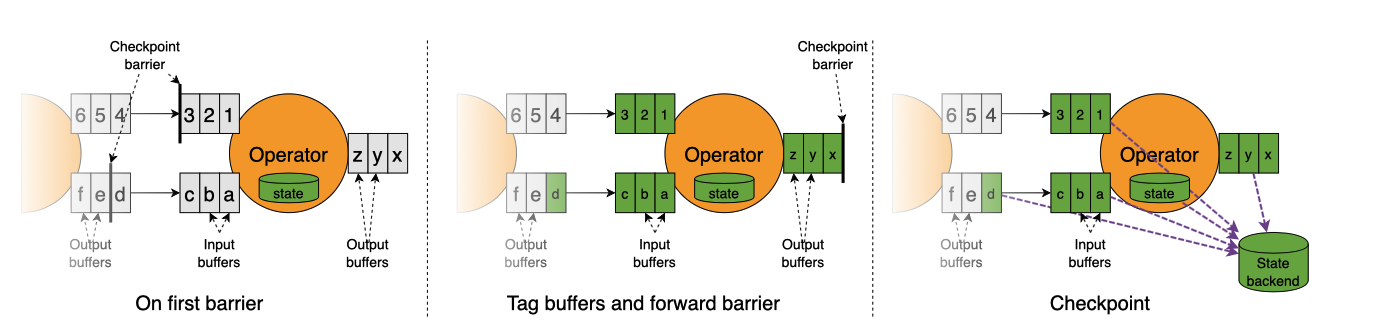
该图描述了一个操作者如何处理不对齐的检查点障碍。
- 操作员对输入缓冲区中存储的第一个障碍作出反应。
- 它立即将屏障转发给下游操作者,将其添加到输出缓冲区的末尾。
- 操作员将所有被超越的记录标记为异步存储,并创建自己状态的快照。
因此,操作者只短暂地停止对输入的处理以标记缓冲区,转发障碍,并创建其他状态的快照。
不对齐的检查点确保屏障以最快的速度到达汇流排。它特别适合于至少有一条缓慢移动的数据路径的应用,在这种应用中,对齐时间可能达到数小时。然而,由于它增加了额外的I/O压力,所以当状态后端的I/O是瓶颈时,它并没有帮助。关于其他的局限性,请参见运维中更深入的讨论。
请注意,保存点将始终保持对齐。
不对齐恢复
操作者首先恢复飞行中的数据,然后才开始处理来自上游操作者在不结盟检查点的任何数据。除此之外,它执行的步骤与恢复对齐检查点时相同。
状态后台
键/值索引的具体数据结构取决于所选择的状态后端。一种状态后端将数据存储在内存中的哈希图中,另一种状态后端使用RocksDB作为键/值存储。除了定义持有状态的数据结构外,状态后端还实现了对键/值状态进行时间点快照的逻辑,并将该快照作为检查点的一部分进行存储。状态后端可以在不改变应用逻辑的情况下进行配置。

保存点
所有使用检查点的程序都可以从保存点恢复执行。保存点允许在不丢失任何状态的情况下同时更新你的程序和Flink集群。
保存点是手动触发的检查点,它采取程序的快照并将其写入状态后端。它们依靠常规的检查点机制来实现。
保存点与检查点类似,只是它们是由用户触发的,并且在新的检查点完成后不会自动失效。
确切的一次与至少一次
对齐步骤可能会给流媒体程序增加延迟。通常,这种额外的延迟是在几毫秒的数量级,但我们已经看到一些异常值的延迟明显增加的情况。对于要求所有记录持续超低延迟(几毫秒)的应用,Flink有一个开关,可以在检查点期间跳过流对齐。只要操作者从每个输入中看到检查点障碍,检查点快照仍然会被绘制。
当跳过对齐时,操作者会继续处理所有的输入,甚至在检查点n的一些检查点障碍到达后也会继续处理。这样,操作者也会在检查点n的状态快照被采集之前处理属于检查点n+1的元素。在还原时,这些记录将作为重复发生,因为它们都包含在检查点n的状态快照中,并将在检查点n之后作为数据的一部分重放。
注意对齐只发生在有多个前辈的操作者(连接)以及有多个发送者的操作者(流重新分区/洗牌后)。正因为如此,即使在至少一次的模式下,只有尴尬的并行流操作(map()、flatMap()、filter()......)的数据流实际上也会给出精确的一次保证。
批量程序的状态和容错性
Flink执行批处理程序是流程序的一种特殊情况,其中流是有界的(元素数量有限)。一个DataSet在内部被当作一个数据流。因此,上述概念适用于批处理程序的方式与适用于流程序的方式相同,但有一些小的例外。
- 批处理程序的容错不使用检查点。恢复是通过完全重放流发生的。这是可能的,因为输入是有界的。这将成本更多地推向恢复,但使常规处理更便宜,因为它避免了检查点。
- DataSet API中的有状态操作使用简化的内存内/核心外数据结构,而不是键/值索引。
- DataSet API引入了特殊的同步(基于superstep的)迭代,只有在有界流上才能实现。详情请查看迭代文档。