
利用表格API进行实时报告
Apache Flink提供的Table API是一个统一的、关系型的API,用于批处理和流处理,即在无边界的、实时的流或有边界的、批处理的数据集上以相同的语义执行查询,并产生相同的结果。Flink中的Table API通常用于简化数据分析、数据管道化和ETL应用的定义。
你将建设什么?
在本教程中,您将学习如何构建一个实时的仪表盘,以按账户跟踪金融交易。该管道将从Kafka读取数据,并将结果写入MySQL,通过Grafana可视化。
先决条件
本演练假设你对Java或Scala有一定的熟悉,但即使你来自不同的编程语言,你也应该能够跟上。它还假设你熟悉基本的关系概念,如SELECT和GROUP BY子句。
救命,我被卡住了!
如果你遇到困难,请查看社区支持资源。特别是Apache Flink的用户邮件列表,一直是Apache项目中最活跃的一个,也是快速获得帮助的好方法。
如果在windows上运行docker,而你的数据生成器容器却无法启动,那么请确保你使用的shell是正确的。例如docker-entrypoint.sh for table-walkthrough_data-generator_1容器需要使用bash。如果不可用,它会抛出一个错误standard_init_linux.go:211: exec用户进程引起 "no such file or directory"。一个变通的方法是在docker-entrypoint.sh的第一行将shell切换为sh。
如何跟进
如果你想跟着走,你需要一台电脑与。
Java 8或11
Maven
Docker
所需的配置文件可在flink-playgrounds资源库中获得。下载后,在IDE中打开项目flink-playground/table-walkthrough,并导航到文件SpendReport。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE transactions (
" +
" account_id BIGINT,
" +
" amount BIGINT,
" +
" transaction_time TIMESTAMP(3),
" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND
" +
") WITH (
" +
" 'connector' = 'kafka',
" +
" 'topic' = 'transactions',
" +
" 'properties.bootstrap.servers' = 'kafka:9092',
" +
" 'format' = 'csv'
" +
")");
tEnv.executeSql("CREATE TABLE spend_report (
" +
" account_id BIGINT,
" +
" log_ts TIMESTAMP(3),
" +
" amount BIGINT
," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (
" +
" 'connector' = 'jdbc',
" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',
" +
" 'table-name' = 'spend_report',
" +
" 'driver' = 'com.mysql.jdbc.Driver',
" +
" 'username' = 'sql-demo',
" +
" 'password' = 'demo-sql'
" +
")");
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
拆解代码
执行环境
前两行设置了你的表环境(TableEnvironment)。表环境是你如何为你的Job设置属性,指定你是在写批处理还是流式应用,以及创建你的源。本演练创建了一个使用流式执行的标准表环境。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
注册表格
接下来,在当前目录中注册了表,您可以使用这些表连接到外部系统,以便读写批处理和流数据。表源提供对存储在外部系统中的数据的访问,如数据库、键值存储、消息队列或文件系统。表汇向外部存储系统发出一个表。根据源和汇的类型,它们支持不同的格式,如CSV、JSON、Avro或Parquet。
tEnv.executeSql("CREATE TABLE transactions (
" +
" account_id BIGINT,
" +
" amount BIGINT,
" +
" transaction_time TIMESTAMP(3),
" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND
" +
") WITH (
" +
" 'connector' = 'kafka',
" +
" 'topic' = 'transactions',
" +
" 'properties.bootstrap.servers' = 'kafka:9092',
" +
" 'format' = 'csv'
" +
")");
注册了两个表:一个是交易输入表,一个是消费报告输出表。交易(transaction)表让我们可以读取信用卡交易,其中包含账户ID(account_id)、时间戳(transaction_time)和美元金额(金额)。该表是在一个名为transaction的Kafka主题上的逻辑视图,包含CSV数据。
tEnv.executeSql("CREATE TABLE spend_report (
" +
" account_id BIGINT,
" +
" log_ts TIMESTAMP(3),
" +
" amount BIGINT
," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (
" +
" 'connector' = 'jdbc',
" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',
" +
" 'table-name' = 'spend_report',
" +
" 'driver' = 'com.mysql.jdbc.Driver',
" +
" 'username' = 'sql-demo',
" +
" 'password' = 'demo-sql'
" +
")");
第二张表spend_report,存储了最终的汇总结果。其底层存储是MySql数据库中的一张表。
查询
配置好环境和注册好表后,你就可以构建你的第一个应用程序了。从TableEnvironment中,你可以从一个输入表中读取它的行,然后使用executeInsert将这些结果写入一个输出表。报表函数是你实现业务逻辑的地方。它目前还没有被实现。
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
测试
该项目包含一个二次测试类SpendReportTest,用于验证报表的逻辑。它以批处理模式创建了一个表格环境。
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build(); TableEnvironment tEnv = TableEnvironment.create(settings);
Flink的独特属性之一是它在批处理和流式处理之间提供一致的语义。这意味着您可以在静态数据集上以批处理模式开发和测试应用程序,并以流式应用程序的形式部署到生产中。
尝试一
现在有了Job设置的骨架,你就可以添加一些业务逻辑了。目标是建立一个报告,显示每个账户在一天中每个小时的总支出。这意味着时间戳列需要从毫秒到小时的颗粒度进行舍入。
Flink支持用纯SQL或使用Table API开发关系型应用。Table API是一个受SQL启发的流畅的DSL,可以用Python、Java或Scala编写,并支持强大的IDE集成。就像SQL查询一样,Table程序可以选择所需的字段,并通过你的键进行分组。这些功能,加上内置的函数,如floor和sum,你可以写这个报告。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
用户自定义函数
Flink包含有限的内置函数,有时你需要用用户定义的函数来扩展它。如果地板不是预定义的,你可以自己实现它。
import java.time.LocalDateTime; import java.time.temporal.ChronoUnit; import org.apache.flink.table.annotation.DataTypeHint; import org.apache.flink.table.functions.ScalarFunction; public class MyFloor extends ScalarFunction { public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval( @DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp) { return timestamp.truncatedTo(ChronoUnit.HOURS); } }
然后迅速将其集成到你的应用程序中。
public static Table report(Table transactions) { return transactions.select( $("account_id"), call(MyFloor.class, $("transaction_time")).as("log_ts"), $("amount")) .groupBy($("account_id"), $("log_ts")) .select( $("account_id"), $("log_ts"), $("amount").sum().as("amount")); }
这个查询会消耗事务表的所有记录,计算报表,并以高效、可扩展的方式输出结果。使用该实现运行测试将通过。
添加窗口
基于时间的数据分组是数据处理中的典型操作,尤其是在处理无限流时。基于时间的分组被称为窗口,Flink提供了灵活的窗口语义。最基本的窗口类型称为Tumble窗口,它有一个固定的大小,其桶不重叠。
public static Table report(Table transactions) { return transactions .window(Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts")) .groupBy($("account_id"), $("log_ts")) .select( $("account_id"), $("log_ts").start().as("log_ts"), $("amount").sum().as("amount")); }
这就定义了你的应用程序使用基于时间戳列的一小时翻滚窗口。因此,时间戳为2019-06-01 01:23:47的行被放在2019-06-01 01:00:00窗口中。
基于时间的聚合是独一无二的,因为在连续流应用中,时间与其他属性不同,一般是向前移动的。与 floor 和你的 UDF 不同,窗口函数是内在的,它允许运行时应用额外的优化。在批处理上下文中,窗口提供了一个方便的API,用于通过时间戳属性对记录进行分组。
用这个实现运行测试也会通过。
再一次,用流处理
就是这样,一个功能齐全、有状态的分布式流式应用! 查询持续消耗Kafka的事务流,计算每小时的花费,并在结果准备好后立即发出。由于输入是无限制的,所以查询一直在运行,直到手动停止。而且由于Job使用了基于时间窗口的聚合,所以当框架知道某个窗口不会再有记录到达时,Flink可以进行特定的优化,比如状态清理。
表游乐场是完全docker化的,可以作为流媒体应用在本地运行。该环境包含一个Kafka主题、一个连续数据生成器、MySql和Grafana。
从table-walkthrough文件夹内启动docker-compose脚本。
$ docker-compose build
$ docker-compose up -d你可以通过Flink控制台查看正在运行的作业信息。
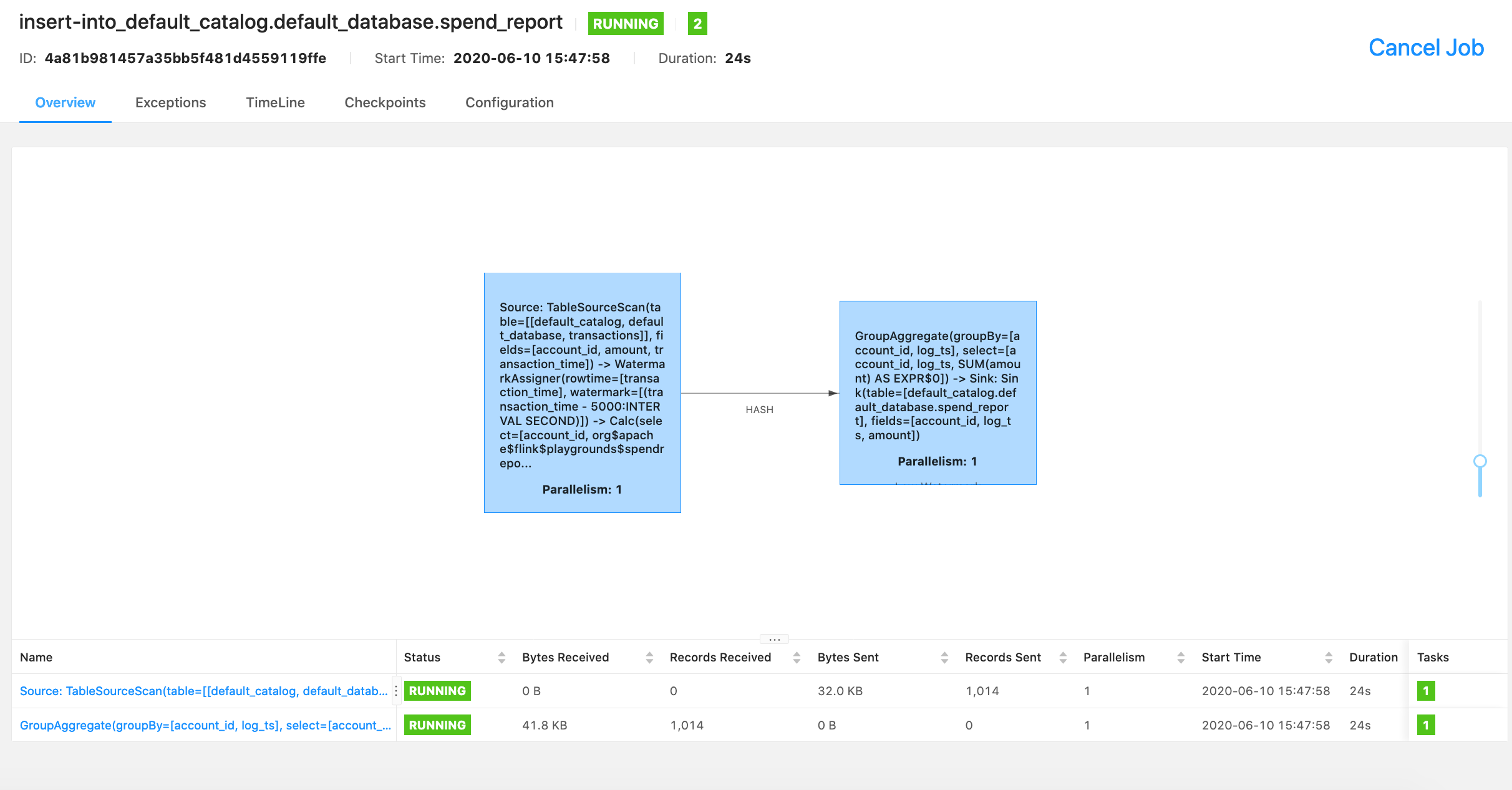
从MySQL内部探究结果。
$ docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql mysql> use sql-demo; Database changed mysql> select count(*) from spend_report; +----------+ | count(*) | +----------+ | 110 | +----------+
最后,去Grafana看看完全可视化的结果吧!
