功效分析:可以帮助在给定置信度的情况下,判断检测到给定效应值时所需的样本量,也可以在给定置信水平的情况下,计算某样本量内可以检测到的给定效应值的概率
1.t检验
案例:使用手机和司机反应时间的实验
1 library(pwr) 2 # n表示样本大小 3 # d表示标准化均值之差 4 # sig.level表示显著性水平 5 # power为功效水平 6 # type指的是检验类型 7 # alternative指的是双侧检验还是单侧检验 8 pwr.t.test(d=.8,sig.level = .05,power = .9,type = 'two.sample',alternative = 'two.sided')

结论:每组需要34个样本(68)人才能保证有90%的把握检测到0.8效应值,并且最多5%会存在误差
2.方差分析
案例:对5组数据做方差分析,达到0.8的功效,效应值为0.25,选择0.5的显著水平.计算总体样本的大小
# k表示组的个数 # f表示效应值 pwr.anova.test(k=5,f=.25,sig.level = .05,power = .8)

结论:需要39*5,195受试者参与实验才能得出以上结果
3.相关性
案例:抑郁症和孤独的关系,零假设和研究假设为
H0:p<=0.25和H1:p>0.25
设定显著水平为0.05,耳光拒绝零假设,希望有90%的信息拒绝H0,需要多少测试者
1 # r表示效应值 2 pwr.r.test(r=.25,sig.level = .05,power = .90,alternative = 'greater')

结论:需要134名受试者参与实验
4.线性模型
案例:老板的领导风格对员工满意度的影响,薪水和小费能解释30%员工满意度方差,领导风格能解释35%的方差,
要达到90%置信度下,显著水平为0.05,需要多少受试者才能达到方差贡献率
f2 = (0.35-0.3)/(1-0.35)=0.0769
1 # u表示分子自由度 2 # v表示分母自由度 3 # f2表示效应值 4 pwr.f2.test(u=3,f2=0.0769,sig.level = .05,power = .90)

结论:v=总体样本-预测变量-1,所以N=v+7+1=187+7+1=193
5.比例检验
案例:某种药物有60%的治愈率,新药有65%的治愈率,现在有多少受试者才能体会到两种药物的差异
1 pwr.2p.test(h=ES.h(.65,.6),sig.level = .05,power = .9,alternative = 'greater')

结论:本案例中使用单边检验,得出需要1605名受试者才能得出两种药品的区别
6.卡方检验
卡方检验用来评价两个变量之间的关系,零假设是变量之间独立,拒绝零假设是变量不独立
案例:研究晋升和种族的关系:样本中70%是白人,10%黑人,20%西班牙裔,相比20%的黑人和50%的西班牙裔,60%的白人更容易获得晋升
1 prob <- matrix(c(.42,.28,.03,.07,.10,.10),byrow = T,nrow = 3) 2 # 计算双因素列连表中的备择假设的效应值 3 ES.w2(prob) 4 # w是效应值, 5 # df是自由度 6 pwr.chisq.test(w=0.1853198,df=2,sig.level = .05,power = .90)

结论:该实验需要369名测试者才能证明晋升和种族存在关联
7.在新的情况下选择合适的效应值
7.1单因素
1 es <- seq(.1,.5,.01) 2 nes <- length(es) 3 samsize <- NULL 4 for(i in 1:nes){ 5 result <- pwr.anova.test(k=5,f=es[i],sig.level = .05,power = .90) 6 samsize[i] <- ceiling(result$n) 7 } 8 plot(samsize,es,type='l',lwd='2',col='red', 9 ylab = 'Effect Size', 10 xlab = 'Sample Szie', 11 main = 'One way Anova with power=.90 and alpha=.05')
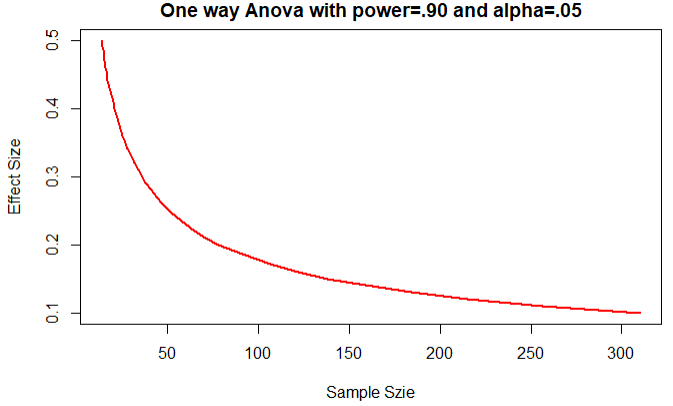
结论:赝本数量高于200时,在增加样本是效果不明显
7.2 绘制功效分析图
1 # 1.生成一系列相关系数和功效值 2 r <- seq(.1,.5,.01) 3 nr <- length(r) 4 5 p <- seq(.4,.9,.1) 6 np <- length(p) 7 8 # 2.获取样本大小 9 samsize <- array(numeric(nr*np),dim = c(nr,np)) 10 11 for(i in 1:np){ 12 for(j in 1:nr){ 13 result <- pwr.r.test(n=NULL,r=r[j],sig.level = .05,power = p[i],alternative = 'two.sided') 14 samsize[j,i] <- ceiling(result$n) 15 } 16 } 17 18 # 3.创建图形 19 xrange <- range(r) 20 yrange <- round(range(samsize)) 21 colors <- rainbow(length(p)) 22 plot(xrange,yrange,type='n', 23 xlab = 'Corrlation Coefficient', 24 ylab = 'Sample Size') 25 # 4.添加功效曲线 26 for(i in 1:np){ 27 lines(r,samsize[,i],type='l',lwd=2,col=colors[i]) 28 } 29 # 5.网格线 30 abline(v=0,h=seq(0,yrange[2],50),lty=2,col='grey89') 31 abline(h=0,v=seq(xrange[1],xrange[2],.02),lty=2,col='grey89') 32 # 6.标题和注释 33 title('Sample Size Estimation for Corrlation Sig=0.05') 34 legend('topright',title = 'Power',as.character(p),fill=colors)
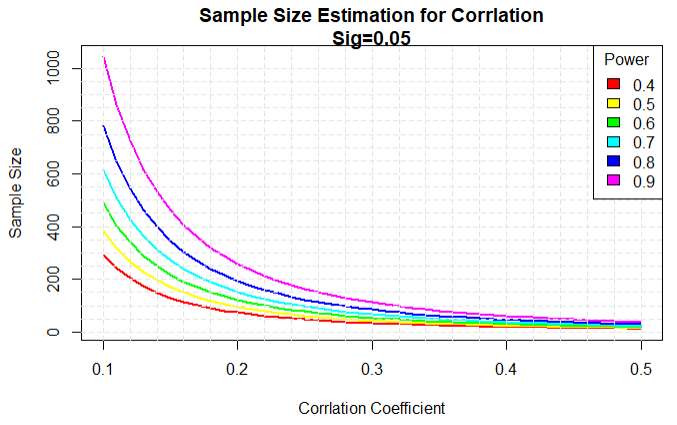
结论:在40%的置信度下,要检测到0.2的相关性需要约75个样本,在90%的置信度下,要检测到相同的相关性需要大约260个样本