项目内容:
本项目选择 淘宝商品类目:零食
数量:一共100页,4400个零食商品
筛选条件:天猫、销量从高到低、价格0元到200元以内

项目目的:
- 对商品标题进行文本分析以及词云可视化
- 商品价格分布情况分析
- 商品的销量分布情况分析
- 商品价格对销量的影响分析
- 商品价格对销售额的影响分析
- 不同省份或城市的商品数量分布
项目步骤:
- 数据采集模块:利用Python爬虫爬取淘宝网商品数据
- 数据预处理模块:对商品数据进行清洗和处理
- 数据分析模块:jieba分词、wordcloud可视化、数据分析及可视化
项目环境:
系统环境:win10 64位
工具:pycharm,chrome devTools,Anaconda
一、爬取数据
因为淘宝网是有反爬虫机制的,虽然我使用了多线程、修改headers参数,以及使用代理ip等,也考虑到我当前测试环境是使用校园网进行爬取淘宝商品信息的,学校只有一个公网ip,按照以往的经验,使用校园网做测试环境的话是不容易被封的,但仍然不能保证每次100%爬取,所以我增加了循环爬取,每次循环爬取未爬取成功的页面,直至所有的页面全部爬取成功。
淘宝商品页面上存储的商品数据是以Json格式存储的,在这里我选择用正则表达式进行解析:
代码如下:
import re import time import random import requests import pandas as pd from retrying import retry from concurrent.futures import ThreadPoolExecutor start = time.clock() # 开始计时 # 请求头池 user_agent = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; " ".NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR " "2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR " "3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; " ".NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR " "3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (" "Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 " "Safari/535.20", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 " "Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 " "LBBROWSER", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR " "3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 " "LBBROWSER", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR " "3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR " "3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR " "3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", "Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 " "Mobile/8C148 Safari/6533.18.5", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre", "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 " "Safari/537.36", ] # 代理ip池 proxies = ['http://125.71.212.25:9000', 'http://202.109.157.47:9000', 'http://47.94.169.110:80', 'http://111.40.84.73:9999', 'http://114.245.221.21:8060', 'http://117.131.235.198:8060'] # plist 为1-100页的URL的编号num plist = [] for i in range(1, 101): j = 44 * (i - 1) plist.append(j) listno = plist datatmsp = pd.DataFrame(columns=[]) while True: @retry(stop_max_attempt_number=8) def network_programming(num): url = 'https://s.taobao.com/search?q=%E9%9B%B6%E9%A3%9F&imgfile=&js=1&stats_click=search_radio_tmall%3A1' '&initiative_id=staobaoz_20190508&tab=mall&ie=utf8&sort=sale-desc&filter=reserve_price%5B%2C200%5D' '&bcoffset=0&p4ppushleft=%2C44&s=' + str(num) random_user_agent = random.choice(user_agent) # 从user_agent池中随机生成headers random_proxies = random.choice(proxies) # 从代理ip池中随机生成proxies web = requests.get(url, headers={'user-agent': random_user_agent}, proxies={'http': random_proxies}) web.encoding = 'utf-8' return web # 多线程 def multithreading(): number = listno # 每次爬取未成功爬取的页 event = [] with ThreadPoolExecutor(max_workers=10) as executor: for result in executor.map(network_programming, number, chunksize=10): event.append(result) return event headers = {"User-Agent": "Mozilla/5.0 (WindowsNT 10.0; WOW64);Chrome/55.0.2883.87 Safari/537.36"} listpg = [] event = multithreading() for i in event: json = re.findall('"auctions":(.*?),"recommendAuctions"', i.text) if len(json): table = pd.read_json(json[0]) datatmsp = pd.concat([datatmsp, table], axis=0, ignore_index=True) pg = re.findall('"pageNum":(.*?),"p4pbottom_up"', i.text)[0] # 记入每一次成功爬取的页码 listpg.append(pg) # 将爬取成功的页码转为url中的num值 lists = [] for a in listpg: b = 44 * (int(a) - 1) lists.append(b) listn = listno listno = [] for p in listn: if p not in lists: listno.append(p) # 当未爬取页数未0时,终止循环 if len(listno) == 0: break datatmsp.to_excel('datatmsp.xls', index=False) end = time.clock() print("爬取完成 用时:", end - start, 's')
爬取到商品数据我是先以Excel文件的xls格式保存存储到本地上,方便调试,以下图1.1是已经爬取到的数据。

图1.1 商品数据
二、数据清洗、预处理
从本地导入上一步爬取到商品数据:
import pandas as pd datatmsp = pd.read_excel('datatmsp.xls')
查看数据维度:
datatmsp.shape
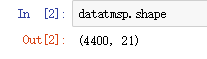
图2.1
通过数据维度可以知道已成功爬取了100页共4400个商品数据,而每个商品数据共有21个字段。
接下来对数据缺失值进行分析,代码如下:
# 数据缺失值分析 # 需要模块 missingno库 pip install missingno import missingno as msno msno.bar(datatmsp.sample(len(datatmsp)), figsize=(10, 4))
运行代码后,发现pid字段和risk字段数据完全缺失,如图所示:
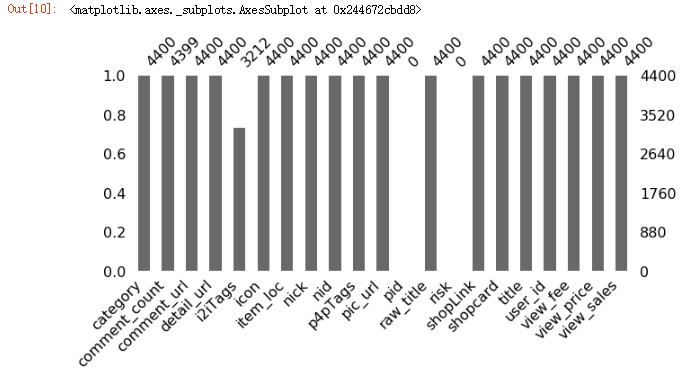
图2.2 数据维度图
将缺失值过半的列以及重复的行的商品数据将被删除,代码如下:
# 删除缺失值过半的列 half_count = len(datatmsp)/2 datatmsp = datatmsp.dropna(thresh=half_count, axis=1) # 删除重复行 datatmsp = datatmsp.drop_duplicates()
datatmsp.shape()
数据清洗后数据维度降到只有4389个商品数据,一共19个字段,删除后的数据维度:


图2.3 清洗后的数据维度图
此时数据已经清洗好了,接下来把淘宝商品数据存进mysql数据库中,因为我用的是私人云服务器上的mysql,在这里就不写连接参数,所以下面代码中连接数据库中的参数读者参考自己的实际情况进行修改哈。
import pymysql from sqlalchemy import create_engine # 与mysql服务器建立起连接 engine = create_engine('mysql+pymysql://{数据库用户名}:{密码}@{ip地址或主机名}:{端口}/{表名}') con = engine.connect() # 将清洗好的商品数据存进mysql datatmsp.to_sql(name='snacks', con=con, if_exists='append', index=False)
数据成功导入mysql:
图2.4 淘宝商品表
根据此次项目需求,本文只需要取item_loc,raw_title,view_price,view_sales这四列的数据,主要是对商品标题、区域、价格、销量四个维度进行分析,代码如下:
# 取出商品标题、区域、价格、销量四个维度的数据 data = datatmsp[['item_loc', 'raw_title', 'view_price', 'view_sales']] data.head()
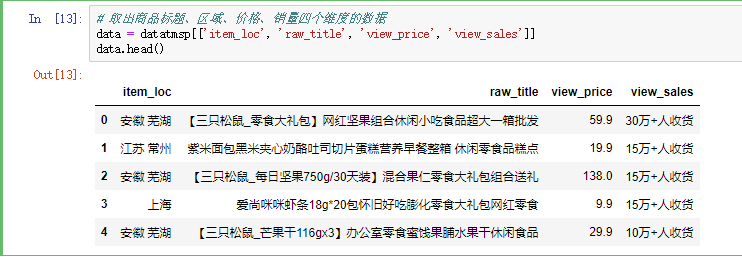
图2.5
接下来,对商品数据进行分析前的预处理,代码如下:
# 对商品所在地item_loc列中的省份和城市进行拆分,生成province列 data['province'] = data.item_loc.apply(lambda x: x.split()[0]) # 因为直辖市的省份和城市相同,在这里根据字符长度进行判断 data['city'] = data.item_loc.apply(lambda x: x.split()[0] if len(x) < 4 else x.split()[1]) # 提取商品销售量view_sales列中的数组,得到sales列 def dealSales(x): x = x.split('人')[0] if '万' in x: if '.' in x: x = x.replace('.', '').replace('万', '000') else: x = x.replace('万', '0000') return x.replace('+', '') data['sales'] = data.view_sales.apply(lambda x: dealSales(x)) # 将sales列的数据类型改为int类型 data['sales'] = data.sales.astype('int') # 用province,city替换category,且转换成与category相同的类型 list_col = ['province', 'city'] for i in list_col: data[i] = data[i].astype('category') # 删除不用的列 data = data.drop(['item_loc', 'view_sales'], axis=1)
查看预处理后的前十行数据:
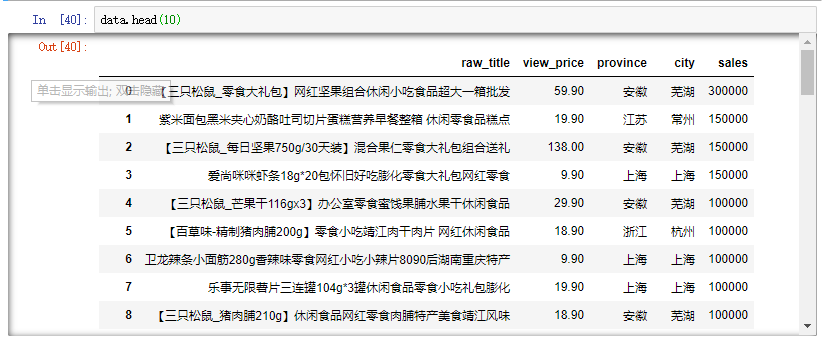
图2.6 数据
三、数据挖掘与分析
3.1 对商品标题进行文本分析
使用jieba分词器,对raw_title列每一个商品标题进行分词,通过停用表StopWords对标题进行去除停用词。因为下面要统计每个词语的个数,所以 为了准确性,在这里对过滤后的数据 title_clean 中的每个list的元素进行去重,即每个标题被分割后的词语唯一。代码如下:
# 将所有商品标题转换为list title = data.raw_title.values.tolist() # 对每个标题进行分词,使用jieba分词 import jieba title_s = [] for line in title: title_cut = jieba.lcut(line) title_s.append(title_cut) # 导入停用此表 stopwords = [line.strip() for line in open('StopWords.txt', 'r', encoding='utf-8').readlines()] # 剔除停用词 title_clean = [] for line in title_s: line_clean = [] for word in line: if word not in stopwords: line_clean.append(word) title_clean.append(line_clean) # 进行去重 title_clean_dist = [] for line in title_clean: line_dist = [] for word in line: if word not in line_dist: line_dist.append(word) title_clean_dist.append(line_dist) # 将 title_clean_dist 转化为一个list allwords_clean_dist = [] for line in title_clean_dist: for word in line: allwords_clean_dist.append(word) # 把列表 allwords_clean_dist 转为数据框 df_allwords_clean_dist = pd.DataFrame({ 'allwords':allwords_clean_dist }) # 对过滤_去重的词语 进行分类汇总 word_count = df_allwords_clean_dist.allwords.value_counts().reset_index() word_count.columns = ['word', 'count']
接下来需要对已分词好的数据进行词云可视化,代码如下:
from wordcloud import WordCloud import matplotlib.pyplot as plt from scipy.misc import imread plt.figure(figsize=(20,10)) # 读取图片 pic = imread("猫.png") w_c = WordCloud(font_path="simhei.ttf", background_color="white", mask=pic, max_font_size=100, margin=1) wc = w_c.fit_words({ x[0]:x[1] for x in word_count.head(100).values }) plt.imshow(wc, interpolation='bilinear') plt.axis("off") plt.show()

分析结论:
- 组合、整装商品占比很高;
-
特产、零食、休闲、小吃等字眼的商品占比较高;
- 从品牌上看:三只松鼠、百草味、良品铺子等网红零食品牌为多。
3.2 不同商品关键字word对应的sales之和的统计分析:
假如所爬取到的商品标题中含有“糖果”一词的销量之和,也就是说求出具有“糖果”关键字的商品销量之和。代码如下:
import numpy as np # 重新更新索引,之前去重的时候没有更新数据data的索引,导致部分行缺失值 data = data.reset_index(drop=True) # 不同关键词word对应的sales之和的统计分析 w_s_sum = [] for w in word_count.word: i = 0 s_list = [] for t in title_clean_dist: if w in t: s_list.append(data.sales[i]); i+=1 w_s_sum.append(sum(s_list)) # list求和 df_w_s_sum = pd.DataFrame({'w_s_sum':w_s_sum}) # 把 word_count 与对应的 df_w_s_sum 合并为一个表: df_word_sum = pd.concat([word_count, df_w_s_sum], axis=1, ignore_index=True) df_word_sum.columns = ['word', 'count', 'w_s_sum'] #添加列名
然后对df_word_sum中的word和w_s_sum两列进行可视化,本文将取销量排名前30的词语进行绘图:
df_word_sum.sort_values('w_s_sum', inplace=True, ascending=True) # 升序 df_w_s = df_word_sum.tail(30) # 取最大的30行数据 import matplotlib from matplotlib import pyplot as plt font = {'family' : 'SimHei'} # 设置字体 matplotlib.rc('font', **font) index = np.arange(df_w_s.word.size) plt.figure(figsize=(10,20)) plt.barh(index, df_w_s.w_s_sum, color='blue', align='center', alpha=0.8) plt.yticks(index, df_w_s.word, fontsize=15) #添加数据标签 for y, x in zip(index, df_w_s.w_s_sum): plt.text(x, y, '%.0f' %x , ha='left', va='center', fontsize=15) plt.show()
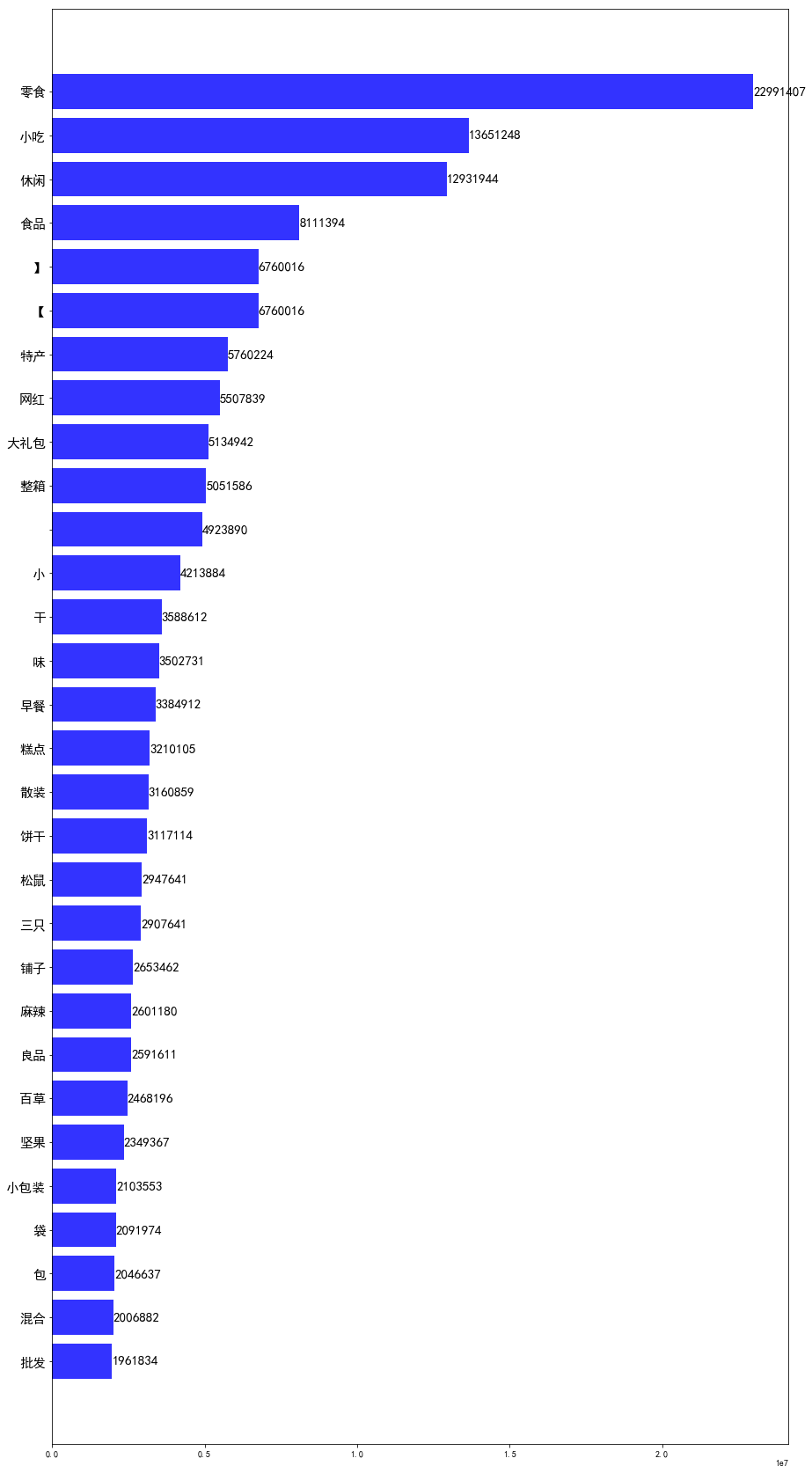
由图表可知:
1. 休闲零食小吃之类的销量最高;
2. 组合、整装商品占比很高;
3. 从关键字可以看出销量榜上以网红品牌为主。
3.3 商品的价格分布情况分析:
本文中限定所爬取的零食单品的销售价格区间在0-200元,在这里我们结合自身产品情况对商品的价格分布情况分析,代码如下:
plt.figure(figsize=(7,5))
plt.hist(data['view_price'], bins=15, color='blue')
plt.xlabel('价格', fontsize=25)
plt.ylabel('商品数量', fontsize=25)
plt.title('不同价格对应的商品数量分布', fontsize=17)
plt.show()

由图表可知:
1. 商品数量集中在0-50元之间,总体呈现先增后减;
2. 低价位商品居多,价格在12-25元之间的商品最多,次之0-12元,商品最少的在价格160-180元之间;
3.4 商品的销量分布情况分析:
为了商品的可视化效果更直观,在这里我们选择销量大于100的商品,代码如下:
data_s = data[data['sales'] > 100] print('销量100以上的商品占比:%.3f'%(len(data_s) / len(data))) plt.figure(figsize=(12,8)) plt.hist(data_s['sales'],bins=20, color='blue') # 分二十组 plt.xlabel('销量', fontsize=25) plt.ylabel('商品数量', fontsize=25) plt.title('不同销量对应的商品数量分布', fontsize=25) plt.show()

由图表可知:
1. 销量100以上的商品接近100%,其中销量100-18000之间的商品最多;
2. 销量在18000以上的,商品的数量下降的很厉害,低销量商品居多。
3. 销量在60000以上的商品很少。
3.5 商品价格对销量的影响分析
在这里我们结合自身产品情况对商品价格在0-200元之间对销量的影响分析:
flg, ax = plt.subplots() ax.scatter(data['view_price'], data['sales'], color='blue') ax.set_xlabel('价格') ax.set_ylabel('销量') ax.set_title('商品价格对销量的影响') plt.show()
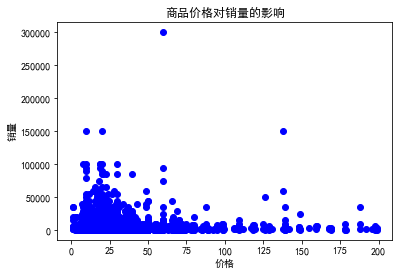
由图表可知:
1. 总体趋势:随着商品价格增多,其销量有所减少,商品价格对其销量有影响的;
2. 价格在0-50之间的商品销量比较集中,销量在100-100000之间,价格150-200元之间的商品多数销量偏少,少数相对较高。
3.6 商品价格对销售额的影响分析
代码如下:
data['GMV'] = data['price'] * data['sales'] import seaborn as sns sns.regplot(x='price', y='GMV', data=data, color='purple')
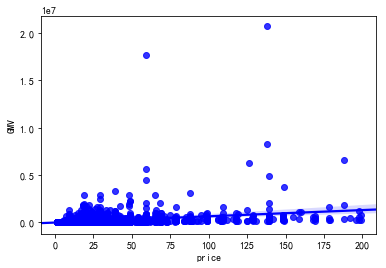
由图表可知:
1. 总体趋势:由线性回归拟合线可以看出,商品销售额随着价格增长呈现缓慢上升趋势;
2. 多数商品的价格偏高,销售额也偏低。
3.7 不同省份的商品数量分布:
代码如下:
plt.figure(figsize=(12,8)) data.province.value_counts().plot( kind='bar', color='purple') plt.xticks(rotation=0) plt.xlabel('省份') plt.ylabel('数量') plt.title('不同省份的商品数量分布') plt.show()
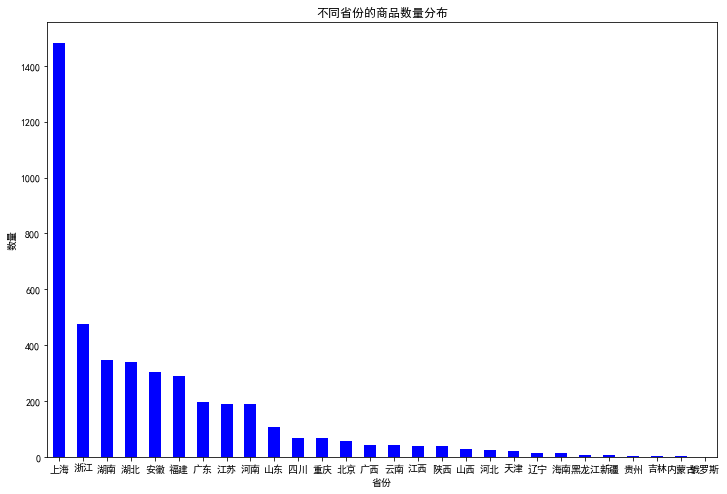
由图表可知:
1. 位于上海的商品最多,浙江次之,湖南第三,尤其是上海的商品数量远超过浙江、湖南、湖北等地,说明在零食这个子类目上,上海的店铺居多。
2. 总体趋势:商品店铺大部分位于沿海地区以及长江中下游。