1.简介
为什么要对消费端进行限流?
其实很好理解,比如我们常能接触到的消费场景:春运期间12306火车票的抢购,双11期间的下单等。这些场景都有一个共同点就是都会导致短暂时间内请求数激增,如果我们的Consumer最多只支持每秒1000的QPS,而由于请求的激增导致每秒2000甚至更多的并发,此时已经远远超过了服务本身所能处理的阈值。如果不对消息进行限流,很可能会将服务拖垮,那将会是灾难性的。实际应用场景不止于这些,接下来通过RabbitMQ来讲解如果对消费端做限流措施。
2. 如何限流
2.1 引入所需依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit-test</artifactId>
<scope>test</scope>
</dependency>
2.1 application.yaml
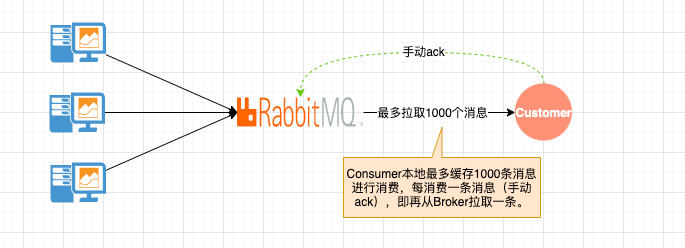
concurrency:并发量,即Consumer本地起concurrency个线程去消费。
prefetch:每个线程每次预取几条消息进行消费。
即:Consumer每次从Broker取concurrency * prefetch(unack个数)条消息缓存到本地进行消费。
如果设置unack个数为20,当消费(ack)了4条消息时服务宕机了,那么剩下的16条消息会重新回到Broker中,已确认的消息会从队列中移除掉。
spring:
rabbitmq:
host: localhost
port: 5672
# rabbit 默认的虚拟主机
virtual-host: /
# rabbit 用户名密码
username: admin
password: admin123
listener:
simple:
# manual 手动确认
acknowledge-mode: manual
# 消费者每次监听消费最小数量 (并发量)
concurrency: 3
# 消费者每次监听消费最大数量 (并发量)
max-concurrency: 10
# 消费者每次消费的数量(unack 次数:这里感觉用次数会更容易理解)
# 即:unacked 数量为 concurrency(最小并发数) * prefetch(可以不确认的次数) = 12(未被接收确认的数量)
prefetch: 4
2.2 声明一个简单队列
/**
* rabbit 快速开始
*
* @author ludangxin
* @date 2021/8/23
*/
@Configuration
public class RabbitSimpleConfig {
/**
* 设置一个简单的队列
*/
@Bean
public Queue queue() {
return new Queue("helloMQ");
}
}
2.3 producer
/**
* 生产者
*
* @author ludangxin
* @date 2021/8/23
*/
@Component
public class SimpleProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void send() {
String context = "helloMQ " + System.currentTimeMillis();
rabbitTemplate.convertAndSend("helloMQ", context);
}
}
2.4 consumer
/**
* 消费者
*
* @author ludangxin
* @date 2021/8/23
*/
@Slf4j
@Component
@RabbitListener(queues = {"helloMQ"})
public class SimpleConsumer {
@RabbitHandler
public void process(String hello) throws InterruptedException {
log.info("Message:{} ", hello);
// 设置睡眠时间,方便通过日志信息分析问题
Thread.sleep(3000);
}
}
2.5 测试代码
@Autowired
private SimpleProducer simpleSender;
@Test
public void hello() throws Exception {
for (int i = 0; i < 100; i++) {
simpleSender.send();
}
// 阻塞进程,使消费者能够正常监听消费。
System.in.read();
}
我们首先分析一下:
我们在测试的时候发送了100条消息,在项目配置的时候unack个数设置了3 * 4 = 12,也就是说我们一次只从Broker拉取12条信息进行消费。
当消费者进行消费的时候我们设置了3秒的延迟,还有很重要一点,我们在消费的时候没有进行ack。也就是说,当我们消费完12条信息后,并没有进行ack,会导致Consumer并不会从Broker继续拉取消息,另一方面也能说明,Consumer确实只从Broker拉取了12条消息。
输出日志如下,每三秒输出三条信息,输出完12条后再没有输出日志,证实了猜想。
