load 和 loads (反序列化)
load:针对文件句柄,将json格式的字符转换为dict,从文件中读取 (将string转换为dict)
a_json = json.load(open('demo.json','r'))
loads:针对内存对象,将string转换为dict (将string转换为dict)
a = json.loads('{'a':'1111','b':'2222'}')
dump 和 dumps(序列化)
dump:将dict类型转换为json字符串格式,写入到文件 (易存储)
a_dict = {'a':'1111','b':'2222'}
json.dump(a_dict, open('demo.json', 'w')
dumps:将dict转换为string (易传输)
a_dict = {'a':'1111','b':'2222'}
a_str = json.dumps(a_dict)
总结:
根据序列化和反序列的特性
loads: 是将string转换为dict
dumps: 是将dict转换为string
load: 是将里json格式字符串转化为dict,读取文件
dump: 是将dict类型转换为json格式字符串,存入文件
实践
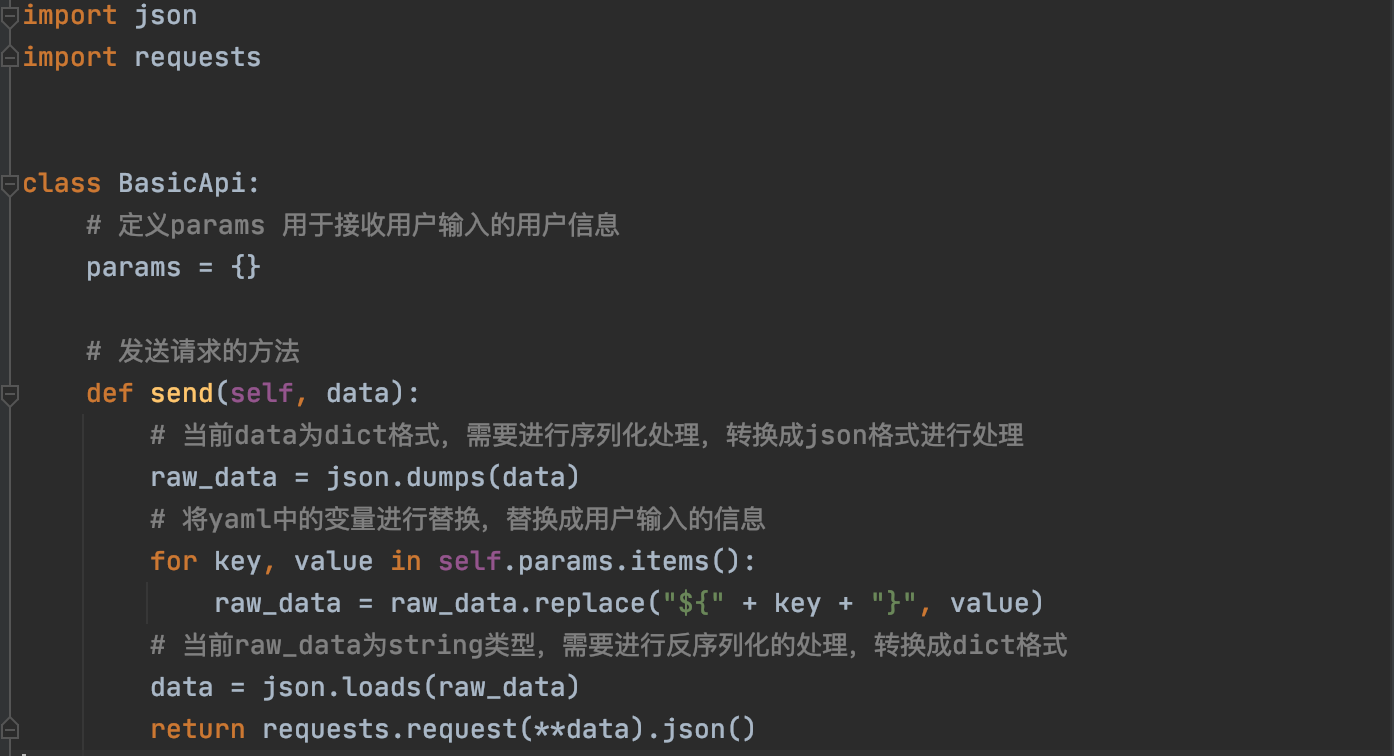
原文:https://www.cnblogs.com/bigtreei/p/10466518.html