编译:javac MyFirst.java
运行:java MyFirst
在指定目录下执行java编译clas文件:https://www.runoob.com/java/env-classpath.html
eg:java -classpath C:javaDemoClasses HelloWorld
Java程序执行流程:
1、编写源代码文件(.java)
2、用编译器运行源代码。编译器会检查错误,如果有错就要改正才能产生正确的输出。编译器会产生字节码(.class)。
任何支持java的装置都能把它转译成可执行的内容。编译后的字节码与平台无关。
3、Java虚拟机JVM读取和执行字节码。
变量必须先声明并初始化以后使用。
Java中的integer和boolean不相容,integer不能作为条件表达式
每行代码以分好结束.
一个Java程序至少要有一个类和一个main函数(在该类中定义)
二进制浮点数移码表示法:
整数部分和指数部分都是二进制,整数部分是小数点移动后的,指数部分是小数点移动位数的二进制表示。
正数和负数二进制小数点左移,指数均是正数;小数点右移,指数均是负数。
eg:
-0.0010011=-0.10011×2^-10
-110001101=-0.110001101×2^1001
负数的二进制表示法:补码表示法
负数二进制补码转十进制:符号位为1则表示负数,所有位取反再加1,最后在前面加上负号。
负数取模方法:
负数参与的取模运算规则:先忽略负号,按照正数运算之后,被取模的数是正数结果就取正,反之取负。
(注:(-2)%5中被取模数是-2;-2%5中被取模数是2前面是负号)
运算符优先级问题:
x,y,z分别为5,6,7 计算z + = -- y * z++ ;// x = 5,y = 5,z = 42
z = z + -- y * z++ ——》 42 = 7 + 5 * 7 从左到右入栈,入的是值(入)
逻辑运算符的短路原则:
int x=1,y=1,z=1;
if(x--==1 && y++==1 || z++==1) // || 短路运算后面的不执行了!
System.out.println(“x=”+x+”,y=”+y+”,z=”+z);// 0 , 2, 1
条件运算符的右结合性:
右结合性:a > b ? a : i > j ? i : j 相当于 a > b ? a : ( i > j ? i : j )
运算符优先级:
括号 > 自增自减 > ~ ! > 算数运算符 > 位移运算 > 关系运算 > 逻辑运算 > 条件运算 > 赋值运算
System.out.println(1+2+”java”+3+4);//3java34
比较字符串是否相等必须使用equals方法!不能使用== "1".equals(cmd) 比cmd.equals("1") 要好。




Java编译器不允许类型不同变量间的赋,除外明确指定强制类型转换。eg:不能将int类型赋值给byte,即使不会发生溢出。
===============================》 Java对象相关的理解:
1、Java对象存放在可回收垃圾的堆中:

2、对象引用的概念:
Dog myDog = new Dog(); //变量myDog只是指向一个临时对象的引用,myDog所占空间并不是对象的实际空间.
引用变量的大小,与虚拟机JVM的实现有关。对于任意一个JVM来说,所有的引用大小都一样,但不同虚拟机间的引用大小可能不同。
Java中的引用变量不能像C那样参与+-等运算。
对象引用可以指向null,但这会导致引用之前指向的对象无法获取,最终因引用计数为0而被垃圾回收器GC收集。
数组类型是一种对象。(可以测试下不同数量的数组名的size,验证数组不是对象引用;测试下Dog[] pets,数组pets的元素是对象引用,比较不同对象数组元素的size)
eg:
1 Books[] myBooks = new Books[3]; 2 myBooks[0] = new Books(); //注意这句不能少,上面只是创建myBooks对象,但并没有为每个元素创建对象(开辟空间). 3 myBooks[1] = new Books(); 4 myBooks[2] = new Books(); 5 myBooks[0].title = "Hello";
包导入:
类的成员变量是会默认初始化的,但所有的局部变量(包括普通方法、成员方法、代码块中定义的变量)均不会默认初始化,在使用局部变量前必须手动初始化否则会报错。
static 修饰的成员变量是类变量,即所有的对象实例均可访问和修改,在类对象实例间共享;局部变量和局部内部类是不允许有访问修饰符和static修饰的。
一个类定义了构造方法,系统就不会为其定义默认构造方法(此时需要手动定义默认构造函数即参数列表为空的构造函数,或在子类构造函数开头显示调用父类的有参构造函数);若此时在其子类的构造函数中没有显式调用父类定义的构造函数,将编译出错。若父类没有重载构造函数,子类的构造函数会自动调用父类的默认构造函数.
如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
子类的所有构造方法内部, 第一行会(隐式)自动先调用父类的无参构造函数super();
如果子类构造方法第一行显式调用了父类构造方法,系统就不再调用无参的super()了。
一个源文件中包含多个类:
类、变量、函数的访问权限:(注意private不能用于修饰外部类和接口,因为接口需要继承)
|
同一个类 |
同一个包 |
不同包的子类 |
不同包非子类 |
|
|
private |
* |
|||
|
默认(friendly) |
* |
* |
||
|
protected |
* |
* |
* |
|
|
public |
* |
* |
* |
* |
注:
使用默认访问修饰符声明的变量和方法,对同一个包内的类是可见的。接口里的变量都隐式声明为 public static final,而接口里的方法默认情况下访问权限为 public。
protected 可以修饰数据成员、构造方法、方法成员,不能修饰类(内部类除外)。接口及接口的成员变量和成员方法不能声明为 protected。
但是位于与父类不同包中的一个子类,能够使用其父类中protected成员的途径只能是,使用子类(或者是子类的子类)的引用。子类和父类在同一个包中则没有这个限制。这样就保证了其他包中的类只能访问它们所继承的部分成员。即在同一个包中,子类可以通过父类的引用来使用父类的protected变量/方法。
protected修饰符详解:https://juejin.im/post/5a1fdfad5188253e2470c20d
非访问修饰符:为了实现一些其他的功能,Java 也提供了许多非访问修饰符。
static 修饰符,用来修饰类方法和类变量。
final 修饰符,用来修饰类、方法和变量,final 修饰的类不能够被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
abstract 修饰符,用来创建抽象类和抽象方法。
synchronized 和 volatile 修饰符,主要用于线程的编程。
注:类中的 final 方法可以被子类继承,但是不能被子类修改。声明 final 方法的主要目的是防止该方法的内容被修改。
抽象类:
抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充。
一个类不能同时被 abstract 和 final 修饰。如果一个类包含抽象方法,那么该类一定要声明为抽象类,否则将出现编译错误。
抽象类可以包含抽象方法和非抽象方法。
抽象方法不能被声明成 final 和 static。
任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。
如果一个类包含若干个抽象方法,那么该类必须声明为抽象类。抽象类可以不包含抽象方法
synchronized 修饰符
synchronized 关键字声明的方法同一时间只能被一个线程访问。synchronized 修饰符可以应用于四个访问修饰符。
transient 修饰符
序列化的对象包含被 transient 修饰的实例变量时,java 虚拟机(JVM)跳过该特定的变量。
该修饰符包含在定义变量的语句中,用来预处理类和变量的数据类型。
当对象被序列化时(写入字节序列到目标文件)时,transient阻止实例中那些用此关键字声明的变量持久化;当对象被反序列化时(从源文件读取字节序列进行重构),这样的实例变量值不会被持久化和恢复。
1 import java.io.FileInputStream; 2 import java.io.FileNotFoundException; 3 import java.io.FileOutputStream; 4 import java.io.IOException; 5 import java.io.ObjectInputStream; 6 import java.io.ObjectOutputStream; 7 import java.io.Serializable; 8 9 //定义一个需要序列化的类 10 class People implements Serializable{ 11 String name; //姓名 12 transient Integer age; //年龄 13 public People(String name,int age){ 14 this.name = name; 15 this.age = age; 16 } 17 public String toString(){ 18 return "姓名 = "+name+" ,年龄 = "+age; 19 } 20 21 } 22 23 public class TransientPeople { 24 public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException { 25 People a = new People("李雷",30); 26 System.out.println(a); //打印对象的值 27 ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("d://people.txt")); 28 os.writeObject(a);//写入文件(序列化) 29 os.close(); 30 ObjectInputStream is = new ObjectInputStream(new FileInputStream("d://people.txt")); 31 a = (People)is.readObject();//将文件数据转换为对象(反序列化) 32 System.out.println(a); // 年龄 数据未定义 33 is.close(); 34 } 35 }
运行结果如下:
姓名 = 李雷 ,年龄 = 30姓名 = 李雷 ,年龄 = null
volatile 修饰符
volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。一个 volatile 对象引用可能是 null。
1 public class MyRunnable implements Runnable 2 { 3 private volatile boolean active; 4 public void run() 5 { 6 active = true; 7 while (active) // 第一行 8 { 9 // 代码 10 } 11 } 12 public void stop() 13 { 14 active = false; // 第二行 15 } 16 }
通常情况下,在一个线程调用 run() 方法(在 Runnable 开启的线程),在另一个线程调用 stop() 方法。 如果 第一行 中缓冲区的 active 值被使用,那么在 第二行 的 active 值为 false 时循环不会停止。
但是以上代码中我们使用了 volatile 修饰 active,所以该循环会停止。
final以及final static修饰的变量的初始化方式:https://www.runoob.com/java/java-modifier-types.html
final 的作用随着所修饰的类型而不同:
1、final 修饰类中的属性或者变量
无论属性是基本类型还是引用类型,final 所起的作用都是变量里面存放的"值"不能变。
这个值,对于基本类型来说,变量里面放的就是实实在在的值,如 1,"abc" 等。
而引用类型变量里面放的是个地址,所以用 final 修饰引用类型变量指的是它里面的地址不能变,并不是说这个地址所指向的对象或数组的内容不可以变,这个一定要注意。
例如:类中有一个属性是 final Person p=new Person("name"); 那么你不能对 p 进行重新赋值,但是可以改变 p 里面属性的值 p.setName('newName');
final 修饰属性,声明变量时可以不赋值,而且一旦赋值就不能被修改了。对 final 属性可以在三个地方赋值:声明时、初始化块中、构造方法中,总之一定要赋值。
2、final修饰类中的方法
作用:可以被继承,但继承后不能被重写。
3、final修饰类
作用:类不可以被继承。
Java中this和supre的使用详解:https://www.runoob.com/w3cnote/the-different-this-super.html
package 的作用就是 c++ 的 namespace 的作用,防止名字相同的类产生冲突。Java 编译器在编译时,直接根据 package 指定的信息直接将生成的 class 文件生成到对应目录下。如 package aaa.bbb.ccc 编译器就将该 .java 文件下的各个类生成到 ./aaa/bbb/ccc/ 这个目录。
import 是为了简化使用 package 之后的实例化的代码。假设 ./aaa/bbb/ccc/ 下的 A 类,假如没有 import,实例化A类为:new aaa.bbb.ccc.A(),使用 import aaa.bbb.ccc.A 后,就可以直接使用 new A() 了,也就是编译器匹配并扩展了 aaa.bbb.ccc. 这串字符串。
为什么JAVA文件中只能含有一个Public类?
java 程序是从一个 public 类的 main 函数开始执行的,(其实是main线程),就像 C 程序 是从 main() 函数开始执行一样。 只能有一个 public 类是为了给类装载器提供方便。 一个 public 类只能定义在以它的类名为文件名的文件中。
每个编译单元(文件)都只有一个 public 类。因为每个编译单元都只能有一个公共接口,用 public 类来表现。该接口可以按照要求包含众多的支持包访问权限的类。如果有一个以上的 public 类,编译器就会报错。 并且 public类的名称必须与文件名相同(严格区分大小写)。 当然一个编译单元内也可以没有 public 类。
Java中常量用final修饰. Java中各种类型所占字节数固定。局部变量是在栈中存放,常量和静态变量是在内存静态存储区域存放,对象(包括成员变量)均是在堆中存放。静态方法只能访问静态变量,因为静态方位独立于对象,对象创建前已有静态方法。静态变量是可以改变的,但一般将静态变量以public static final type varname的形式定义成常量.
Java中其他类型和字符串类型的相互转换:https://www.runoob.com/java/java-basic-datatypes.html
Java允许隐式自动类型转换(低范围到大范围);但大范围类型到小范围类型必须显式强制类型转换。
原始类型:boolean,char,byte,short,int,long,float,double。
包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double。
所有的包装类(Integer、Long、Byte、Double、Float、Short)都是抽象类 Number 的子类。
这种由编译器特别支持的包装称为装箱,所以当内置数据类型被当作对象使用的时候,编译器会把内置类型装箱为包装类。相似的,编译器也可以把一个对象拆箱为内置类型。Number 类属于 java.lang 包。
int arr = new Integer(10);
Integer arr1 = arr;
String类型是不可改变的常量(即不可改变某个字符),所有的String修改方法均会返回一个新的String对象,源对象不会变。
1 public final class String 2 implements java.io.Serializable, Comparable<String>, CharSequence { 3 /** The value is used for character storage. */ 4 private final char value[]; 5 }
字符串实际上就是一个 char 数组,并且内部就是封装了一个 char 数组。并且这里 char 数组是被 final 修饰的。并且 String 中的所有的方法,都是对于 char 数组的改变,只要是对它的改变,方法内部都是返回一个新的 String 实例。
1 String s = "Google"; 2 System.out.println("s = " + s); 3 s = "Runoob"; 4 System.out.println("s = " + s);
输出结果为:Runoob
从结果上看是改变了,但为什么门说String对象是不可变的呢?原因在于实例中的 s 只是一个 String 对象的引用,并不是对象本身,当执行 s = "Runoob"; 创建了一个新的对象 "Runoob",而原来的 "Google" 还存在于内存中。
String a = "a";String b = "b";String c = a + b;
相当于:
String c = new StringBuffer().append(a).append(b).toString();
对于字符串的加运算,当编译成 class 文件时,会自动编译为 StringBuffer 来进行字符串的连接操作。
同时对于字符串常量池:当一个字符串是一个字面量时,它会被放到一个常量池中,等待复用。
1 String a = "saff"; 2 String b = "saff"; 3 String c = new String("saff"); 4 System.out.println(a.equal(b)); // true 5 System.out.println(a.equal(c)); // true
这个就是字符串的常量池。
面试题二:
1 String s1="a"+"b"+"c"; 2 String s2="abc"; 3 System.out.println(s1==s2); 4 System.out.println(s1.equals(s2)); 5 java 中常量优化机制,编译时 s1 已经成为 abc 在常量池中查找创建,s2 不需要再创建。
面试题三:
1 String s1="ab"; 2 String s2="abc"; 3 String s3=s1+"c"; 4 System.out.println(s3==s2); // false 5 System.out.println(s3.equals(s2)); // true 先在常量池中创建 ab ,地址指向 s1, 再创建 abc ,指向 s2。对于 s3,先创建StringBuilder(或 StringBuffer)对象,通过 append 连接得到 abc ,再调用 toString() 转换得到的地址指向 s3。故 (s3==s2) 为 false。
Java:String、StringBuffer 和 StringBuilder 的区别:
String:字符串常量,字符串长度不可变。Java中String 是immutable(不可变)的。用于存放字符的数组被声明为final的,因此只能赋值一次,不可再更改。
StringBuffer:字符串变量(Synchronized,即线程安全)。如果要频繁对字符串内容进行修改,出于效率考虑最好使用 StringBuffer,如果想转成 String 类型,可以调用 StringBuffer 的 toString() 方法。Java.lang.StringBuffer 线程安全的可变字符序列。在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。可将字符串缓冲区安全地用于多个线程。
StringBuilder:字符串变量(非线程安全)。在内部 StringBuilder 对象被当作是一个包含字符序列的变长数组。
基本原则:
如果要操作少量的数据用 String ;
单线程操作大量数据用StringBuilder ;
多线程操作大量数据,用StringBuffer。
当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类。
和 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
1 public class Test{ 2 public static void main(String args[]){ 3 StringBuffer sBuffer = new StringBuffer("菜鸟教程官网:"); 4 sBuffer.append("www"); 5 sBuffer.append(".runoob"); 6 sBuffer.append(".com"); 7 System.out.println(sBuffer); 8 } 9 }
对整数进行格式化:%[index$][标识][最小宽度]转换方式(1$表示第一个参数)
对浮点数进行格式化:%[index$][标识][最少宽度][.精度]转换方式
java中继承:只能继承一个类,但可以继承实现多个接口。
继承时子类重载的变量/方法的修饰符访问权限应不低于父类对应的:
父类中声明为 public 的方法在子类中也必须为 public。
父类中声明为 protected 的方法在子类中要么声明为 protected,要么声明为 public,不能声明为 private。
父类中声明为 private 的方法,不能够被继承。
对于父类中定义为private的变量,子类不能直接继承或访问,需要通过在构造函数中super调用父类的有参构造函数才能继承。
父类对象不允许转成子类对象,但子类对象可以自动转成父类对象;并且但父类对象的引用指向子类对象时,可以通过强制类型转换的方法将该引用转成子类对象。
Java子类重写继承的方法时,不可以降低方法的访问权限,子类继承父类的访问修饰符要比父类的更大,也就是更加开放。
假如父类是protected修饰的,其子类只能是protected或者是public,绝对不能是friendly(默认的访问范围)或者private,当然使用private就不是继承了。
还要注意的是,继承当中子类抛出的异常必须是父类抛出的异常的子异常,或者子类抛出的异常要比父类抛出的异常要少。
当执行重写方法时,运行时类型检查:
1 public class TestDog{ 2 public static void main(String args[]){ 3 Animal a = new Animal(); // Animal 对象 4 Animal b = new Dog(); // Dog 对象 5 a.move();// 执行 Animal 类的方法 6 b.move();//执行 Dog 类的方法 7 } 8 }
注:父类申明变量指向子类实例,该父类变量不能调用父类不存在的变量和方法,否则会编译错误。
虚函数概念:就是实现类对象的动态绑定,从而能调用子类自己重写的方法;Java中普通函数即是C++中的虚函数。详见:https://www.runoob.com/java/java-polymorphism.html
多态的实现方式:重写、重载、接口、抽象类和抽象方法。详见:https://www.runoob.com/java/java-polymorphism.html
在使用instanceof 判断对象类型时,子类对象是父类,但父类对象不是子类。并且在判断一个实例引用的类型时,使用的是实际类型,而不是声明的类型。
1 Vehicle v2 = new Car(); // v2 是 Car 类型 2 Vehicle v3 = new Vehicle(); 3 boolean result2 = v2 instanceof Car; // true 4 boolean result3 = v2 instanceof Vehicle; // true 5 boolean result4 = v3 instanceof Car; // false
下表中具有最高优先级的运算符在的表的最上面,最低优先级的在表的底部。
| 类别 | 操作符 | 关联性 |
|---|---|---|
| 后缀 | () [] . (点操作符) | 左到右 |
| 一元 | + + - !〜 | 从右到左 |
| 乘性 | * /% | 左到右 |
| 加性 | + - | 左到右 |
| 移位 | >> >>> << | 左到右 |
| 关系 | >> = << = | 左到右 |
| 相等 | == != | 左到右 |
| 按位与 | & | 左到右 |
| 按位异或 | ^ | 左到右 |
| 按位或 | | | 左到右 |
| 逻辑与 | && | 左到右 |
| 逻辑或 | | | | 左到右 |
| 条件 | ?: | 从右到左 |
| 赋值 | = + = - = * = / =%= >> = << =&= ^ = | = | 从右到左 |
| 逗号 | , | 左到右 |
Java除了支持普通类似C语言形式的for(int i; i<10; i++)循环,还支持增强版的for循环:
1 int [] numbers = {10, 20, 30, 40, 50}; 2 for(int x : numbers ) { //需要注意的是int 不能提到外面去声明. 普通的for循环可以。 3 // x 等于 30 时跳出循环 4 if( x == 30 ) { 5 break; 6 } 7 }
跳出多层循环的方法:使用标识符+break
1 public class Test { 2 public static void main(String []args) { 3 lable: 4 for(int i = 0; i < 10; i++){ 5 for(int j = 0; j < 10; j++){ 6 if(i * 10 + j > 29){ 7 break lable; 8 } 9 System.out.print("" + i + j +" "); 10 } 11 System.out.println(" -------------------------------------- "); 12 } 13 System.out.println("输出完毕!"); 14 } 15 }
多维数组定义时,必须确定高维上的长度,低维上的数组长度可以不同:(和C语言中有点不一样)
1 String s[][] = new String[2][]; 2 s[0] = new String[2]; 3 s[1] = new String[3]; 4 s[0][0] = new String("Good"); 5 s[0][1] = new String("Luck"); 6 s[1][0] = new String("to"); 7 s[1][1] = new String("you"); 8 s[1][2] = new String("!");
java.util.Arrays 类能方便地操作数组,它提供的所有方法都是静态的。即可以通过Arrays.sort(arr)的形式操作数组.
1 public static int binarySearch(Object[] a, Object key) 2 public static boolean equals(long[] a, long[] a2) 3 public static void fill(int[] a, int val) 4 public static void sort(Object[] a)
switch 语句中的变量类型可以是: byte、short、int 或者 char。从 Java SE 7 开始,switch 支持字符串 String 类型了,同时 case 标签必须为字符串常量或字面量。
case 语句中的值的数据类型必须与变量的数据类型相同,而且只能是常量或者字面常量。
当变量的值与 case 语句的值相等时,那么 case 语句之后的语句开始执行,直到 break 语句出现才会跳出 switch 语句。default可以不要break.
注意 == 与 equals的区别:
== 它比较的是对象的地址
equals 比较的是对象的内容
eg:
1 Integer i = new Integer(100); 2 Integer j = new Integer(100); 3 System.out.print(i == j); //false。因为 new 生成的是两个对象,其内存地址不同。 4 eg: 5 Integer a=123; 6 Integer b=123; 7 System.out.println(a==b); // 输出 true。Java 会对 -128 ~ 127 的整数进行缓存,所以当定义两个变量初始化值位于 -128 ~ 127 之间时,两个变量使用了同一地址 8 eg: 9 a=1230; 10 b=1230; 11 System.out.println(a==b); // 输出 false。当两个 Integer 变量的数值超出 -128 ~ 127 范围时, 变量使用了不同地址 12 System.out.println(a.equals(b)); // 输出 true
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CPU的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会。
函数的可变参数:
typeName... parameterName
在方法声明中,在指定参数类型后加一个省略号(...) 。一个方法中只能指定一个可变参数,它必须是方法的最后一个参数。任何普通的参数必须在它之前声明。
1 void function(String... args); 2 void function(String [] args);
这两个方法的命名是相等的,不能作为方法的重载。可变参数,即可向函数传递 0 个或多个参数,如:
1 void function("Wallen","John","Smith"); 2 void function(new String [] {"Wallen","John","Smith"});
finalize() 方法:
Java 允许定义这样的方法,它在对象被垃圾收集器析构(回收)之前调用,这个方法叫做 finalize( ),它用来清除回收对象。
例如,你可以使用 finalize() 来确保一个对象打开的文件被关闭了。在 finalize() 方法里,你必须指定在对象销毁时候要执行的操作。
finalize() 一般格式是:
1 protected void finalize() 2 { 3 // 在这里终结代码 4 }
关键字 protected 是一个限定符,它确保 finalize() 方法不会被该类以外的代码调用。当然,Java 的内存回收可以由 JVM 来自动完成。如果你手动使用,则可以使用上面的方法。
利用Scanner类从输入流中读取数字:https://www.runoob.com/java/java-scanner-class.html
利用BufferedReader类从输入流中读取字符/字符串:https://www.runoob.com/java/java-files-io.html
Scanner和BufferedReader的区别:
BufferedReader 是支持同步的,而 Scanner 不支持。如果我们处理多线程程序,BufferedReader 应当使用。
BufferedReader 相对于 Scanner 有足够大的缓冲区内存。
Scanner 有很少的缓冲区(1KB 字符缓冲)相对于 BufferedReader(8KB字节缓冲),但是这是绰绰有余的。
BufferedReader 相对于 Scanner 来说要快一点,因为 Scanner 对输入数据进行类解析,而 BufferedReader 只是简单地读取字符序列。
文件的读写、目录的操作:https://www.runoob.com/java/java-files-io.html
运行时异常(非检查异常)和检查异常:https://blog.csdn.net/tanga842428/article/details/52751303
1、检查性异常: 不处理编译不能通过
2、非检查性异常:不处理编译可以通过,如果有抛出直接抛到控制台
3、运行时异常: 就是非检查性异常
4、非运行时异常: 就是检查性异常
异常发生在程序运行时,语法错误在程序编译阶段会被检查。
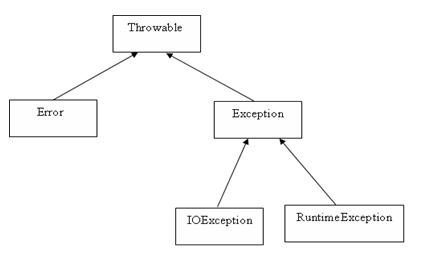
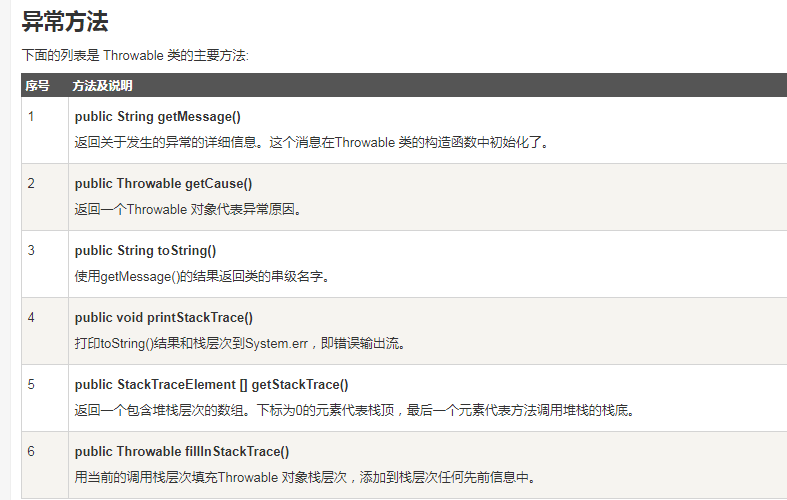
1.检查型异常(Checked Exception)
个人理解:所谓检查(Checked)是指编译器要检查这类异常,检查的目的一方面是因为该类异常的发生难以避免,另一方面就是让开发者去解决掉这类异常,所以称为必须处理(try ...catch)的异常。如果不处理这类异常,集成开发环境中的编译器一般会给出错误提示。
例如:一个读取文件的方法代码逻辑没有错误,但程序运行时可能会因为文件找不到而抛出FileNotFoundException,如果不处理这些异常,程序将来肯定会出错。所以编译器会提示你要去捕获并处理这种可能发生的异常,不处理就不能通过编译。

2.非检查型异常(Unchecked Exception)
个人理解:所谓非检查(Unchecked)是指编译器不会检查这类异常,不检查的则开发者在代码的编辑编译阶段就不是必须处理,这类异常一般可以避免,因此无需处理(try ...catch)。如果不处理这类异常,集成开发环境中的编译器也不会给出错误提示。
例如:你的程序逻辑本身有问题,比如数组越界、访问null对象,这种错误你自己是可以避免的。编译器不会强制你检查这种异常。

异常处理时,即使try语句块中有return语句,finally语句块仍然会执行,除非try语句块中有System.exit(0);
并且finally语句块中不应该有return语句,这样会导致try语句块或catch语句块中抛出的异常被忽略。
finally块的语句在try或catch中的return语句执行之后返回之前执行且finally里的修改语句可能影响也可能不影响try或catch中 return已经确定的返回值,
若finally里也有return语句则覆盖try或catch中的return语句直接返回;若没有return 语句则finally对返回值的修改,并不会影响前面return的值。
Java抽象类不允许实例化(编译不通过),但抽象类允许有方法实现,有抽象方法的类必须是抽象类。定义抽象类或抽象方法在public后加上abstract即可。类方法不能定义成抽象方法(即static和abstract不能一起用)
子类在重写父类的方法时,最好在方法头前加上@Override
接口只能包含抽象方法,不能有实现。
类继承使用extends,实现接口使用implements。
可以用抽象类或接口声明一个变量(绑定在一个实现抽象类或接口的对象),但不能实例化一个抽象类或接口对象。除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。
接口没有构造方法。接口中所有的方法必须是抽象方法。接口不能包含成员变量,除了 static 和 final 变量。
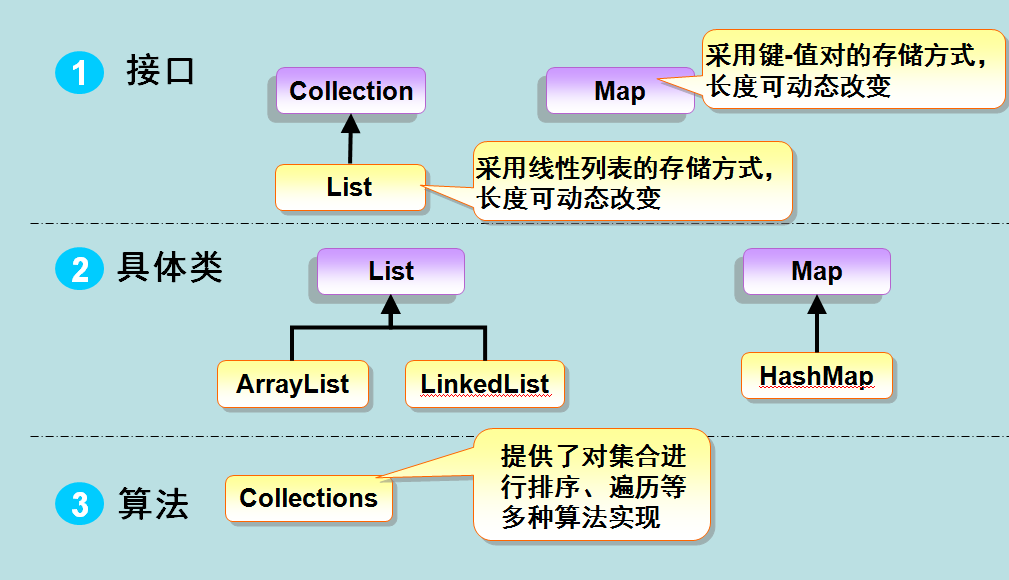
Java集合框架:https://www.runoob.com/java/java-collections.html(遍历集合的几种方式)
任何对象加入集合类后,自动转变为Object类型,所以在取出的时候,需要进行强制类型转换。
任何对象没有使用泛型之前会自动转换Object类型,使用泛型之后不用强制转换。
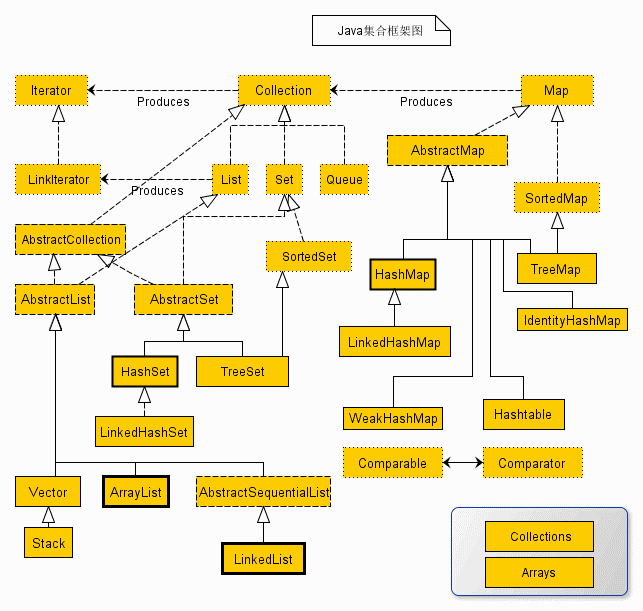
==================== 遍历 ArrayList
1 public class Test{ 2 public static void main(String[] args) { 3 List<String> list=new ArrayList<String>(); 4 list.add("Hello"); 5 list.add("World"); 6 list.add("HAHAHAHA"); 7 //第一种遍历方法使用 For-Each 遍历 List 8 for (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式 9 System.out.println(str); 10 } 11 12 //第二种遍历,把链表变为数组相关的内容进行遍历 13 String[] strArray=new String[list.size()]; 14 list.toArray(strArray); 15 for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式 16 { 17 System.out.println(strArray[i]); 18 } 19 20 //第三种遍历 使用迭代器进行相关遍历 21 Iterator<String> ite=list.iterator(); 22 while(ite.hasNext())//判断下一个元素之后有值 23 { 24 System.out.println(ite.next()); 25 } 26 } 27 }
============================= 遍历 Map
1 public class Test{ 2 public static void main(String[] args) { 3 Map<String, String> map = new HashMap<String, String>(); 4 map.put("1", "value1"); 5 map.put("2", "value2"); 6 map.put("3", "value3"); 7 8 //第一种:普遍使用,二次取值 9 System.out.println("通过Map.keySet遍历key和value:"); 10 for (String key : map.keySet()) { //若不是泛型定义map,此句会编译不通过key是object类型需要强转 11 System.out.println("key= "+ key + " and value= " + map.get(key)); 12 } 13 14 //第二种 15 System.out.println("通过Map.entrySet使用iterator遍历key和value:"); 16 Iterator<Map.Entry<String, String>> it = map.entrySet().iterator(); 17 while (it.hasNext()) { 18 Map.Entry<String, String> entry = it.next(); 19 System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); 20 } 21 22 //第三种:推荐,尤其是容量大时 23 System.out.println("通过Map.entrySet遍历key和value"); 24 for (Map.Entry<String, String> entry : map.entrySet()) { 25 System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); 26 } 27 28 //第四种 29 System.out.println("通过Map.values()遍历所有的value,但不能遍历key"); 30 for (String v : map.values()) { 31 System.out.println("value= " + v); 32 } 33 } 34 }
泛型的概念:
eg:public static <T extends Comparable<T>> T maximum(T x, T y, T z){} //函数的返回类型和参数类型均为T
<T extends Comparable<T>>:表示类型T,extends表示继承,Comparable<T>表示泛型接口Comparable能比较T类型的变量。因此这里定义的类型T必须是实现了Comparable接口的类型,并且接口的参数是T的实例。
<T extends Comparable<? super T>>:表示类型 T 必须实现 Comparable 接口,并且这个接口的类型是 T 或 T 的任一父类。这样声明后,T 的实例之间,T 的实例和它的父类的实例之间,可以相互比较大小。例如,在实际调用时若使用的具体类是 Dog (假设 Dog 有一个父类 Animal),Dog 可以从 Animal 那里继承 Comparable<Animal> ,或者自己 implements Comparable<Dog> 。
注:?表示类型通配符,用于代替具体的类型参数,这里即T的任意父类或T本身。
因此有称extends表示类型上界,super表示类型下界,这种泛型参数称为有界泛型参数。泛型参数必须是引用类型,不能是原始类型(eg:int、float、char等)但可以是他们的包装类
接口Comparable声明了compareTo方法,返回int类型,负数表示<,0表示=,正数表示>
============= 泛型类的定义
1 public class Box<T> { 2 private T t; 3 public void add(T t) { 4 this.t = t; 5 } 6 7 public T get() { 8 return t; 9 } 10 11 public static void main(String[] args) { 12 Box<Integer> integerBox = new Box<Integer>(); 13 Box<String> stringBox = new Box<String>(); 14 15 integerBox.add(new Integer(10)); 16 stringBox.add(new String("菜鸟教程")); 17 18 System.out.printf("整型值为 :%d ", integerBox.get()); 19 System.out.printf("字符串为 :%s ", stringBox.get()); 20 } 21 }
============ 泛型通配符
1 public static void getUperNumber(List<? extends Number> data) { //表示Number的任意子类 2 System.out.println("data :" + data.get(0)); 3 } <? extends T>表示该通配符所代表的类型是T类型的子类。 <? super T>表示该通配符所代表的类型是T类型的父类。
============= 泛型只在编译时进行类型检查
1 import java.util.*; 2 public class Main 3 { 4 public static void main(String[] args) 5 { 6 List<Integer> list = new ArrayList<>(); 7 list.add(12); 8 // list.add("a"); //这里直接添加会报错 9 Class<? extends List> clazz = list.getClass(); 10 try{ 11 Method add = clazz.getDeclaredMethod("add", Object.class); 12 add.invoke(list, "kl"); //但是通过反射添加,是可以的 13 } 14 catch (Exception e){ 15 } 16 System.out.println(list); 17 } 18 }
readOject反序列化方法返回的是object类型,需要转成合适类型的引用。
一个类的对象要想序列化成功,必须满足两个条件:
该类必须实现 java.io.Serializable 对象。
该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
通常情况下,用transient和static修饰的变量是不能被序列化的,但是通过在序列化的类中写writeObject(ObjectOutputStream stream)和readObject(ObjectInputStream stream)方法,可以实现序列化。
有人说static的变量为什么不能序列化,因为static的变量可能被改变。
static final的常量可以被序列化。
java多线程能提高CPU的利用效率体现在:
磁盘IO是比较耗时的操作,且与CPU计算是相互独立的,而CPU计算时间往往较短;因此可以在某个线程在读写IO时,利用CPU来跑另一个线程的计算。
守护线程是服务于用户线程的, 当所有用户线程执行完时,守护线程即使未执行完也会随着JVM的推出而终止.
java常用功能函数的使用:https://www.runoob.com/java/java-examples.html
java 正则表达式区分大小写:https://www.cnblogs.com/cRaZy-TyKeIo/p/3454458.html
java中Object转String(避免null导致的空指针异常):https://www.cnblogs.com/wuxiang12580/p/10370127.html
synchronized 详解:
1、对于静态方法,由于此时对象还未生成,所以只能采用类锁;
2、只要采用类锁,就会拦截所有线程,只能让一个线程访问。
3、对于对象锁(this),如果是同一个实例,就会按顺序访问,但是如果是不同实例,就可以同时访问。
4、如果对象锁跟访问的对象没有关系,那么就会都同时访问。
ExecutorService与线程池ThreadPoolExecutor:
线程池--拒绝策略RejectedExecutionHandler:
线程局部变量ThreadLocal:
ThreadLocal提供了线程的局部变量,每个线程都可以通过
set()和get()来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离。往ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的。
ThreadLocal设计的目的就是为了能够在当前线程中有属于自己的变量,并不是为了解决并发或者共享变量的问题。
java并发编程:
接口的默认修饰符:
Java的interface中,成员变量的默认修饰符为:public static final
public static final String name = "张三"; 等价于 String name = "张三";
方法的默认修饰符是:public abstract
public abstract List<String> getUserNames(Long companyId); 等价于 List<String> getUserNames(Long companyId);
接口只是对一类事物属性和行为的更高次抽象;对修改关闭,对扩展开放,可以说是java中开闭原则的一种体现吧。