爬虫基础
爬虫相关概念简介
什么是爬虫
爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。
哪些语言可以实现爬虫
1.php:可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。
2.java:可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
3.c、c++:可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
4.python:可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
爬虫的分类:根据使用场景可以分为如下两类
1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
1)搜索引擎如何抓取互联网上的网站数据?
a)门户网站主动向搜索引擎公司提供其网站的url
b)搜索引擎公司与DNS服务商合作,获取网站的url
c)门户网站主动挂靠在一些知名网站的友情链接中
2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
robots.txt协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
反爬虫
门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
反反爬虫
爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
http和https协议
HTTP协议
1.官方概念:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。(虽然童鞋们将这条概念都看烂了,但是也没办法,毕竟这就是HTTP的权威官方的概念解释,要想彻底理解,请客观目移下侧......)
2.白话概念:
HTTP协议就是服务器(Server)和客户端(Client)之间进行数据交互(相互传输数据)的一种形式。我们可以将Server和Client进行拟人化,那么该协议就是Server和Client这两兄弟间指定的一种交互沟通方式。
3.HTTP工作原理:
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发
送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
4.HTTP四点注意事项:
- HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5.HTTP之URL:
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
6.HTTP之Request:
常见的请求头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问
User-Agent:请求载体的身份标识
报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
7.HTTP之Response:
 常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
HTTPS协议
1.官方概念:
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
2.白话概念:
加密安全版的HTTP协议。
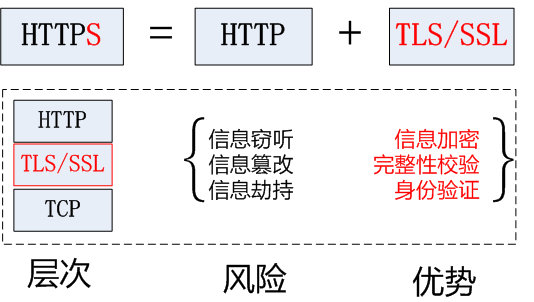 3.HTTPS采用的加密技术
3.HTTPS采用的加密技术
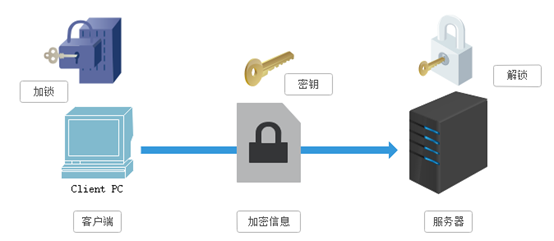 3.1 SSL加密技术
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客 户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密, 接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个), 密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持 ,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:
3.1 SSL加密技术
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客 户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密, 接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个), 密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持 ,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:
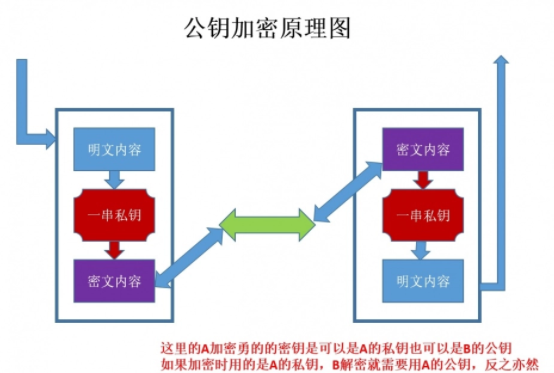
3.2 非对称秘钥加密技术
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密 的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密 钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就 不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因 为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。
但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而 不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率 问题而影响通信速度
4.https的证书机制
 服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数
字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数
字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。