注: 本文总结得内容来源比较杂, 主要方便个人对知识的深度理解, 基本上看<深度学习>这本书中遇到的线性代数方面比较模糊的概念都会随时掌握并补充到下文中.
1. 基础概念
标量(scalar)
一个标量就是一个单独的数,一般用小写的的变量名称表示。
向量(vector)
一个向量就是一列数,这些数是有序排列的:
矩阵(matrices)
矩阵是二维数组:
张量(tensor)
多维数组中元素分布在若干位坐标的规则网络中, 称之为张量. 几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解的话,我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是**
二阶张量。
张量在深度学习中是一个很重要的概念,因为它是一个深度学习框架中的一个核心组件,后续的所有运算和优化算法几乎都是基于张量进行的。
2. 矩阵相关
转置(transpose)
主对角线: 矩阵从左上角到右下角的对角线称为主对角线.矩阵的转置是指以主对角线为轴的镜像.
令矩阵\(\mathbf{A}\)的转置表示为\(\mathbf{A}^T\), 则定义如下:
Tips:
向量是单列矩阵, 向量的转置是单行矩阵. 标量可看做单元素矩阵, 因此标量的转置是它本身: \(a=a^T\).
矩阵加法和广播:
矩阵加法定义: \(\mathbf{C}=\mathbf{A}+\mathbf{B}\)
在深度学习中, 允许矩阵和向量相加, 产生一个新的矩阵, 简写为:\(\mathbf{C}=\mathbf{A}+\mathbf{b}\), 表示向量\(\mathbf{b}\)和矩阵\(\mathbf{A}\)的每一行都相加. 这种隐式地幅值向量\(\mathbf{b}\)到很多位置的方式成为广播.
矩阵乘法
分配律: \(\mathbf{A(B+C)}\)
结合律: \(\mathbf{A(BC)=(AB)C}\)
矩阵乘积不满足交换律: \(\mathbf{AB\neq{BA}}\)
向量点积满足交换律: \(\mathbf{x^Ty=y^Tx}\)
乘积的转置: \(\mathbf{(AB)^T=B^TA^T}\)
单位矩阵
主对角线元素都是1, 其余位置所有元素都是0的矩阵:
我们将n维向量不变的单位矩阵即为\(\mathbf{I_n}\):
逆矩阵
矩阵逆是强大的工具, 对于大多数矩阵, 都可以通过矩阵逆解析求\(\mathbf{Ax=b}\)的解.
矩阵\(\mathbf{A}\)的矩阵逆记作: \(\mathbf{A^{-1}}\), 矩阵逆满足如下条件:
矩阵特征值
设A是n阶方阵,如果存在数\(\lambda\)和非零n维列向量\(\vec x\),使得 \(A\vec x=\lambda \vec x\) 成立,则称\(\lambda\) 是矩阵A的一个特征值, \(\vec x\)称为矩阵A的特征向量.
\(Ax=λx\)也可以写成: \((A-λE)X=0\), 这是n个未知数n个方程的齐次线性方程组,它有非零解的充分必要条件是系数行列式\(|A-λE|=0\):

\(|A-λE|=0\)是一个n次代数方程,称为A的特征方程, |λE-A|=0的根称为A的特征根(或特征值)
以A的特征值\(λ_0\)代入\((λE-A)X=θ\),得方程组(\(λ_0E-A)X=θ\),是一个齐次方程组,称为A的关于\(λ_0\)的特征方程组.
因为\(|λ_0E-A|=0\),\((λ_0E-A)X=θ\)必存在非零解\(X^{(0)}\),\(X^{(0)}\)称为A的属于\(λ_0\)的特征向量。
举例, 求矩阵\(\begin{pmatrix} 1 & -3 & 3 \\ 3 & -5 & 3 \\6 & -6 & 4 \end{pmatrix}\)的特征值与特征向量.
解:


特征向量的性质:

奇异矩阵
矩阵X只有是方阵, 若列向量线性相关, 则成该方阵X是奇异的.
对角矩阵
对角矩阵是一个主对角线之外的元素皆为0的矩阵:
对角矩阵可以记作: \(A=diag(\lambda_1,\lambda_2,...,\lambda_n)\)
若n阶方阵A与对角矩阵相似,则称A为可对角化矩阵, 即, 对于n阶方阵A,若存在可逆矩阵P, 使其为对角阵,则称方阵A可对角化。
若矩阵可对角化,则可按下列步骤来实现:
(1) 求出的全部特征值;
(2)对每一个特征值,设其重数为k,则对应齐次方程组的基础解系由k个向量构成,即为对应的线性无关的特征向量;
(3)上面求出的特征向量恰好为矩阵的各个线性无关的特征向量。
推论:
- 若n阶矩阵A有n个相异的特征值,则A与对角矩阵相似。
- n阶矩阵A可对角化的充要条件是对应于A的每个特征值的线性无关的特征向量的个数恰好等于该特征值的重数。
判断两个矩阵是否相似的辅助方法(必要条件非充要条件):
- 判断特征值是否相等;
- 判断行列式是否相等
- 判断迹是否相等
- 判断秩是否相等
正交矩阵
如果\(AA^T=E\)(E为单位矩阵,\(A^T\)表示“矩阵A的转置矩阵”),则n阶实矩阵A称为正交矩阵。
如果A为正交阵, 则:
- \(A^T\)也是正交矩阵
- \(AA^T=A^TA=E\)
- A的各行是单位向量且两两正交
- A的各列是单位向量且两两正交
- \(|A|\) = 1或-1
- \(A^T=A^{-1}\)
问:
为什么实对称矩阵的相似对角化要用正交矩阵?
答: 对称矩阵也可以用一般的由特征向量组成的非奇异阵做对角化,只不过它有特殊的性质(对称),因此我们就可以考虑特殊的对角化,也就是正交相似对角化。这么做有好处:正交矩阵的逆矩阵很容易求,就是它的转置,不像一般的可逆阵需要半天才能求出来。你想想,如果是一个1000*1000的矩阵求逆,那要多长时间才能做完?但正交矩阵就太容易了,只要转置一下就行了。
相似矩阵
设A,B为n阶矩阵,如果有n阶可逆矩阵P存在,使得\(P^{-1}AP=B\), 则称矩阵A与B相似,记为\(A\sim B\)。
性质:
- 若A与对角矩阵相似,则称A为可对角化矩阵, 即:如果存在一个可逆矩阵 P 使得 \(P^{−1}AP\) 是对角矩阵,则它就被称为可对角化的。
- 相似矩阵具有相同的可逆性,当它们可逆时,则它们的逆矩阵也相似
- 若A~ B,则A与B两者的秩,行列式,迹,特征值,特征多项式,初等因子均相等
定理:
- n阶矩阵A与对角矩阵相似的充分必要条件为矩阵A有n个线性无关的特征向量。
实对称矩阵
对称矩阵转置后与原矩阵相等, 对称元素都相等,也就是\(A(x,y)=A(y,x)\), 因此不难看出其中一个必要条件是矩阵必须满足是n阶方阵.
实对称矩阵的特性:
- 实对称矩阵A的不同特征值对应的特征向量是正交的。
- 实对称矩阵A的特征值都是实数,特征向量都是实向量。
- n阶实对称矩阵A必可对角化,且相似对角阵上的元素即为矩阵本身特征值。
- 若实对称矩阵A具有k重特征值, 必有k个线性无关的特征向量。
实对称矩阵对角化为什么要做正交化单位化?


结论:如果不做正交单位话,我们一样可以通过U(把特征向量按照列写成的矩阵),把一个实对称矩阵对角化为以它的特征值为对角元的对角矩阵。
我们知道,对应一个特征值的特征向量乘以任何一个非零的系数,仍然还是对应着这个特征值的特征向量,如果一个特征值对应多个特征向量,那在它们张成的空间里找出同样数量的线性不相关的向量,也都是这个特征值的特征向量,所以说特征向量并不唯一,也就是说这里的U是不唯一的。
而对于一个实对称矩阵,它的属于不同特征值的特征向量天生就是正交的,这使得我们只要在每个特征值内部选取合适的互相正交的特征向量,就能保证所有的特征向量都正交。而我们刚刚说过,特征向量乘以一个系数,仍然还是特征向量。所以,对于实对称矩阵来说,我们完全可以在诸多的U中选出一个特殊的Q,让Q的每一个列向量都互相正交而且长度为1。这时我们就惊喜的发现,这样的相当于由一组标准正交基当做列向量组成的矩阵Q,正是一个正交矩阵。
于是,我们就清楚的知道了,对实对称矩阵对角化的时候,正交单位化不是必须的,只有当我们想在实对称矩阵的诸多U里选取一个正交矩阵Q时,才需要做。正交矩阵有很多很好的性质,于是乎想从U里找到一个Q也变得情有可原了不是?
3. 行列式计算

3. 线性相关
线性方程
线性组合
X \中各个列向量乘以对应的系数之和: $$\sum_{i}b_i x^{(i)}$$
生成空间
X中的原始向量线性组合后能抵达的点的集合. 确定上述方程是否有解相当于确定向量\(\vec{y}\) 是否在X 的列向量的生成子空间中.
矩阵X可逆时解为\(\vec b = X^{-1}\cdot y\) , 然而矩阵可逆是一个十分苛刻的条件,X 的列空间构成整个m维欧式空间\(R^m\), 若\(X\cdot \vec{b} = \vec{y}\)对于每一个y值最多有一个解, 则X矩阵至多有m个列向量.
因此, 矩阵X只有是方阵且所有列向量都是线性无关的时候才满足要求, 若列向量线性相关, 则成该方阵X是奇异的.
这里引出了线性模型的基本模型: $$X\cdot \vec{b} = \vec{y}$$
X可逆时 ,我们可以直接对两边求逆, 得到线性模型的唯一解:
然而,样本特征组成的矩阵X往往是不可逆的, 即X往往不是方阵, 或者是奇异的方阵.
正因为在现实世界里, 直接对矩阵求逆来得到唯一解 \(\vec{b}\) 几乎是不可能的, 所以我们才会退而求其次, 用最小化误差来逼近唯一解, 这叫做松弛求解.
求最小化误差的一般方法是求残差的平方和最小化, 这也就是所谓的线性最小二乘法.
4. 范数(norm)
在机器学习中, 通常用范数来衡量一个矩阵的大小, \(L^p\)范数公式: $$||x||_p = \left( \sum_i|x_i|^p \right)^\frac 1 p$$
注意抓重点: 范数在机器学习中是用来衡量一个向量的大小.
范数
是将向量映射到非负值的函数. 简单来讲, 向量\(\vec x\)的范数是原点到\(\vec x\)的距离. 这里之所以介绍范数, 是因为它涉及到机器学习中非常重要的正则化技术.
\(p = 2\)时, \(L^2\)称为欧几里得范数(Euclidean norm), 表示原点到向量\(\vec x\)的欧氏距离, \(L^2\)范数通常简写为\(||x||\) , 它非常频繁地出现在机器学习中. 此外, 平方\(L^2\)范数\(\left(||x||\right)^2\)也经常用来衡量向量的大小, 可以简单地用点积\(\left( \vec x \right)^\top \cdot \vec x\)计算.
\(L^2\)范数: $$||x||_2 = (\sum_i|x_i|2)\frac 1 2 $$
平方\(L^2\)范数: $$ ||x|| = \sum_i|x_i|^2$$
\(L^1\)范数: $$ ||x||1 = \sum_i|x_i| $$
Frobenius范数: $$||A||F=\sqrt{\sum{i,j}{A{i,j}}^{2}}$$
关于范数, 注意以下几点:
-
平方\(L^2\) 范数对\(\vec x\)各元素导数只和对应元素相关, 而\(L^2\)范数对个元素的导数和整个向量相关, 因此平方\(L^2\)范数计算更方便.
-
有时候平方\(L^2\)范数在原点附近增长缓慢, 在某些机器学习业务场景下, 区分元素值是否非零很重要, 此时更倾向于使用\(L^1\)范数.
-
\(L^1\)范数在各个位置斜率相同, 且数学形式较简单, 每当\(\vec x\)中某元素从0增加了\(\epsilon\) 时, 对应\(L^1\)范数也增加$\epsilon $, \(L^1\)范数通常被用在零和非零差异非常重要的机器学习问题中.
-
"\(L^0\)范数"通常用向量中非零元素个数来衡量向量大小, 但是这种说法不严谨, 因为从数学意义上讲,对向量缩放\(\alpha\)倍, 向量大小会变, 但是机器学习中, 非零元素数目不变, 这和向量运算的数学意义相悖.
-
\(L^\infty\)范数称为最大范数(max norm), 表示最大幅值元素的绝对值: \(||x||\infty=\max_i{|x_i|}\)
-
Frobenius范数在机器学习中用来衡量矩阵大小.
-
两个点积可以用范数来表示: $\vec{x}^T \cdot \vec{y} = ||\vec{x}||_2||\vec{y}||_2cos\theta $
在机器学习中, \(L^2\)和\(L^1\)范数分别对应\(L^2\)和\(L^1\)正则化, 详情参考线性模型中的岭回归(Ridge Regression)和套索回归(Lasso).
5. 伪逆(Moore-Penrose)
非方阵方程,其逆矩阵没有意义. 假设要求解线性方程
等式两边左乘左逆\(\vec{B}\)后: $$x = \vec{B}y$$
是否存在唯一映射, 将\(\vec{A}\)映射到\(\vec{B}\)取决于问题形式:
- 若矩阵A行数大于列数, 则可能无解;
- 若矩阵A行数小于列数, 则可能有多个解.
伪逆可以解决上述问题. 矩阵A的伪逆定义为:
违逆计算的简化公式为:
其中, 矩阵U, D, V是矩阵A的奇异值分解后的特殊矩阵, 其中\(\vec{U}\)和\(\vec{V}\)都是正交矩阵, \(\vec{D}\)为对角矩阵(不一定是方阵). 对角矩阵D的伪逆\(\vec{D^+}\)是非零元素取倒数后再转置得到的.奇异值分解称为SVD(Singular Value Decomposition).
- 矩阵A的列数多于行数时, 可能有多个解. 伪逆求解线性方程是众多解法中的一种, 即: \(\vec{x} = \vec{A^+}\vec{y}\)是所有可行解中欧几里得距离最小的一个
- 矩阵A列数小于行数时, 可能没有解. 伪逆求解得到的x是\(\vec{A}x\)和\(\vec{y}\)的欧几里得距离\(||\vec{A}x-\vec{y}||_2^2\)最小的解, 这里又回到了求解线性问题的一般思路上: 线性最小二乘法.
6. 常用的距离
1、曼哈顿距离
也称为城市街区距离,数学定义如下:
曼哈顿距离的Python实现:
from numpy import *
vector1 = mat([1,2,3])
vector2 = mat([4,5,6])
print sum(abs(vector1-vector2))
2. 欧氏距离
前面提到过, 欧氏距离就是\(L_2\)范数, 定义如下:
欧氏距离的Python实现:
vector1 = np.mat([1,2,3])
vector2 = np.mat([4,5,6])
print np.sqrt((vector1-vector2)*(vector1-vector2).T)
3. 闵可夫斯基距离
上述两种距离的更一般形式, 完整的定义如下:
4. 切比雪夫距离
即前面提到过的无穷范数\(L^\infty\)范数, 数学表达式:
Python实现如下
from numpy import *
vector1 = mat([1,2,3])
vector2 = mat([4,5,6])
print sqrt(abs(vector1-vector2).max)
5. 夹角余弦
用来衡量两个向量方向的差异, 夹角余弦越大,表示两个向量的夹角越小
机器学习中用这一概念来衡量样本向量之间的差异,其数学表达式如下:
python实现:
from numpy import *
vector1 = mat([1,2,3])
vector2 = mat([4,5,6])
print dot(vector1,vector2)/(linalg.norm(vector1)*linalg.norm(vector2))
6. 汉明距离
表示两个字符串中不相同位数的数目, 例如:字符串‘1111’与‘1001’之间的汉明距离为2.
信息编码中一般应使得编码间的汉明距离尽可能的小.
python实现:
from numpy import *
matV = mat([1,1,1,1],[1,0,0,1])
smstr = nonzero(matV[0]-matV[1])
print smstr
7. 杰卡德距离
杰卡德相似系数: 两个集合A和B的交集元素在A和B的并集中所占的比例称为两个集合的杰卡德相似系数,用符号\(J(A,B)\)表示.
数学表达式:
杰卡德距离: 用杰卡德相似系数来描述, 用符号\(J_\sigma\)表示.
数学表达式:
Python实现:
from numpy import *
import scipy.spatial.distance as dist
matV = mat([1,1,1,1],[1,0,0,1])
print dist.pdist(matV,'jaccard')
## 7. 特征分解
许多数学对象可以通过将它们分解成多个组成部分。特征分解是使用最广的矩阵分解之一,即将矩阵分解成一组特征向量和特征值。
方阵A的特征向量是指与A相乘后相当于对该向量进行缩放的非零向量\(\nu\):
标量\(\lambda\)被称为这个特征向量对应的特征值。
使用特征分解去分析矩阵A时,得到特征向量构成的矩阵V和特征值构成的向量\(\lambda\),我们可以重新将A的特征分解记作:
每个实对称矩阵都可以分解成实特征向量和实特征值: $ A=Q \Lambda Q^T\( \)Q$ 是\(A\)的特征向量组成的正交矩阵,\(Λ\) 是对角矩阵
任意一个实对称矩阵 A 都有特征分解,但是特征分解可能并不唯一.
矩阵是奇异的当且仅当含 有零特征值.
正定矩阵: 所有特征值都是正数的矩阵.
负定矩阵: 所有特征值都是负数的矩阵.
半正定矩阵: 所有特征值都是非负数的矩阵.
下图展示了特征值和特征向量的作用效果:
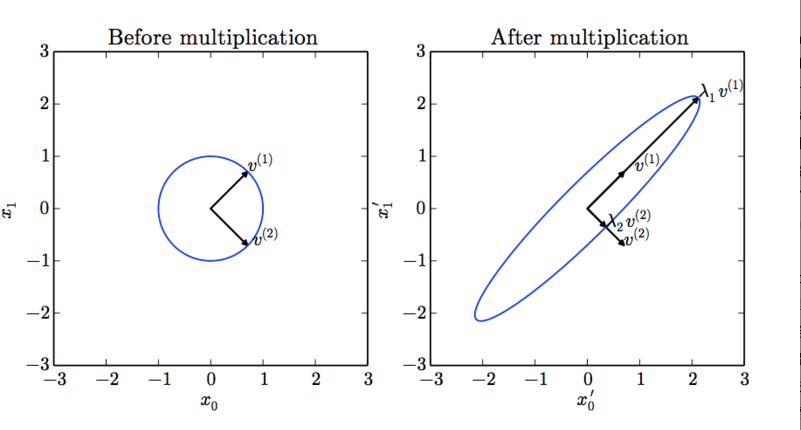
在上图中,矩阵 \(A\) 有两个标准正交的特征向量,对应特征值为\(λ_1\) 的 \(v^(1)\) 以及对应特征值为 \(λ2\) 的 \(v^(2)\)。(左) 我 们画出了所有的单位向量 \(u ∈ R2\) 的集合,构成一个单位圆。(右) 我们画出了所有的 \(Au\) 点的集 合。通过观察 \(A\) 拉伸单位圆的方式,我们可以看到它将 \(v^(i)\) 方向的空间拉伸了 \(λ_i\) 倍.
8. 奇异值分解(SVD)
除了特征分解,还有一种分解矩阵的方法,被称为奇异值分解(SVD)。将矩阵分解为奇异向量和奇异值。通过奇异分解,我们会得到一些类似于特征分解的信息。然而,奇异分解有更广泛的应用。
每个实数矩阵都有一个奇异值分解,但不一定都有特征分解。例如,非方阵的矩阵没有特征分解,这时我们只能使用奇异值分解。
奇异分解与特征分解类似,只不过这回我们将矩阵A分解成三个矩阵的乘积:
假设A是一个 \(m\times n\) 矩阵,那么U是一个 \(m\times m\) 矩阵,D是一个 $m\times n $矩阵,V是一个 $n\times n $ 矩阵。
这些矩阵每一个都拥有特殊的结构,其中U和V都是正交矩阵,D是对角矩阵(注意,D不一定是方阵)。对角矩阵D对角线上的元素被称为矩阵A的奇异值。矩阵U的列向量被称为左奇异向量,矩阵V 的列向量被称右奇异向量。
SVD最有用的一个性质可能是拓展矩阵求逆到非方矩阵上。另外,SVD可用于推荐系统中。