1.机器学习分类
整体框架:



监督学习:对于有标签的数据进行学习,目的是能够正确判断无标签的数据。通俗的讲,老师教授学生知识,并告知学习过程中的对与错,让学生可以从所学知识的经验和技能中对没有学过的问题进行正确回答,这就是监督学习,用于预测数据的回归、分类标签的分类、顺序的排序等问题。
无监督学习:对于无标签的数据进行学习,目的是不仅能够解决有明确答案的问题,也可以对没有明确答案的问题进行预测。通俗的讲,学生通过自学学习知识,达到可以正确回答有答案的问题,也可以对无答案的问题进行预测归类。常用于聚类、异常检测等。
强化学习:学生学习知识时,没有老师对其进行对与错的判定,需要学生根据自己所拥有的信息自己判定对于错,如果能够判定出来,则为有监督学习;如果判定不出来对与错,则为无监督学习。常用于机器人的自动控制、游戏的人工智能、市场战略的最优化等。
监督学习应用:手写文字识别、声音处理、图像处理、垃圾邮件分类与拦截、网页检索、基因诊断、股票预测......(回归、分类、排序)
无监督学习应用:人造卫星故障诊断、视频分析、社交网站解析、声音信号解析.....(聚类、异常检测)
强化学习应用:机器人的自动控制、计算机游戏中的人工智能、市场战略的最优化(回归、分类、聚类、降维)
2.机器学习方法
- 生成式分类
- 判别式分类
- 统计概率
- 朴素贝叶斯
生成式分类和判别式分类
已知模式x, 求分类类别y的条件概率\(p(y|x)\)最大的类别: $ \hat{y} = \underset{y}{\arg\max} p(y|x)$
条件概率改写为y的函数: \(p(y|x) = \frac{p(x,y)}{p(x)} \propto p(x,y)\)
联合概率p(x,y)和后验概率p(y|x)成正比,故直接求联合概率最大值即可: \(\hat{y} = \underset{y}{\arg\max p(x,y)}\)
条件概率p(y|x)也称后验概率
联合概率p(x,y)也称数据生成概率
直接对后验概率\(p(y|x)\)学习的过程称为判别式分类
通过预测数据生成概率\(p(x,y)\)学习的过程称为生成式分类
数据生成概率\(p(x,y)\)已知时可推出后验概率: $ p(y|x) = \frac{p(x,y)}{p(x)} = \frac{p(x,y)}{\sum_y{p(x,y)}} $, 反之不可以.
统计概率和朴素贝叶斯
- 统计概率方法
已知样本\(D=\{(x_i,y_i)\}_{i=1}^{n}\), 求运用最大似然方法来求模式\(\theta\):
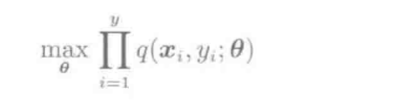
目标: 由训练集得到高精度的\(\theta\)
- 朴素贝叶斯方法
计算模式\(\theta\)的先验概率\(p(\theta)\),运用贝叶斯定理来求数据集D的后验概率\(p(\theta|D)\):
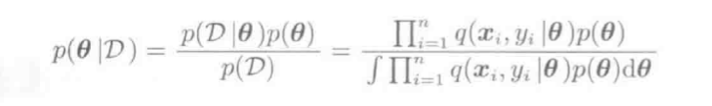
目标: 如何精确计算后验概率\(p(\theta)\)
3. 补充知识
强化学习(RL),监督学习(SL)和无监督学习(UL)的区别和联系:
下面这段话解释了得很清楚:

划重点:
- Supervised Learning: given data, predict labels
- Unsupervised Learning: given data, learn about that data
- Reinforcement learning: given data, choose action to maximize expected long-term reward
- RL更像控制系统家族里的,流着控制的血液,披着机器学习的外衣,需要data,training以此来支持决策。RL可以decision-making,不同于决策树之类的决策,是控制角度的决策,意味着就有失误,伴随着收益与惩罚(股票,博弈,游戏得分等等)。
细一点来说,RL与SL的区别有:
- 喂数据的方式不同:强化学习(RL)的数据是序列的、交互的、并且还是有反馈的(Reward)-【MDP]。这就导致了与监督学习(SL)在优化目标的表现形式的根本差异:RL是一个决策模型,SL更偏向模式挖掘,低阶的函数逼近与泛化。RL是agent自己去学习,SL是跟着programmer的idea在收敛。
- RL的target是估计得来的,符合bellman等式,SL的target是fixed label;RL可以融合SL来训练,RL还可以自己博弈来生成样本。[交互特性,也可以放到第一点中]
- RL可以进行lifelong形式的学习。RL有“生命”的【你可能也不知道你训练出来的模型到底能干什么】,SL没有。