郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NeurIPS 2020
Abstract
在强化学习(RL)中有效利用以前收集的大型数据集是大规模现实世界应用程序的关键挑战。离线RL算法承诺从先前收集的静态数据集中学习有效的策略,而无需进一步交互。然而,在实践中,离线RL提出了一个重大挑战,标准的离线RL方法可能会由于数据集和学习策略之间的分布变化引起的价值高估而失败,特别是在对复杂多模态数据分布进行训练时。在本文中,我们提出了保守Q学习(CQL),旨在通过学习保守Q函数来解决这些限制,使得在该Q函数下的策略期望价值的下限为其真实值。我们从理论上表明,CQL对当前策略的价值产生了下限,并且可以将其纳入具有理论改进保证的策略学习过程中。在实践中,CQL用一个简单的Q值正则化器增强了标准Bellman误差目标,该正则化器可以直接在现有的深度Q学习和actor-critic实现之上实现。在离散和连续控制域上,我们表明CQL大大优于现有的离线RL方法,通常学到的策略可以获得2-5倍的最终回报,尤其是在从复杂多模态数据分布中学习时。
1 Introduction
强化学习(RL)的最新进展,尤其是与富有表现力的深度网络函数逼近器相结合时,已经在从机器人[31]到策略游戏[4]和推荐系统[37]的领域产生了可喜的成果。然而,将RL应用于现实世界的问题始终带来实际挑战:与在监督学习中取得成功的各种数据驱动方法[24, 11]相比,RL被经典地视为一个主动学习过程,其中每次训练运行需要与环境进行主动交互。与现实世界的交互可能既昂贵又危险,并且可以在线收集的数据量大大低于监督学习中使用的离线数据集[10],只需收集一次。离线RL,也称为批处理RL,提供了一种有吸引力的替代方案[12, 17, 32, 3, 29, 57, 36]。离线RL算法从以前收集的大型数据集中学习,无需交互。原则上,这可以利用大型数据集,但在实践中,完全离线的RL方法会带来重大的技术困难,这是由于收集数据的策略和学习的策略之间的分布转移造成的。这使得目前的结果未能完全实现这些方法的承诺。
在离线设置中直接利用现有的基于价值的异策RL算法通常会导致性能不佳,这是由于分布外动作[32, 17]的bootstrapping和过拟合[15, 32, 3]的问题。这通常表现为错误的乐观价值函数估计。如果我们可以学习价值函数的保守估计,它为真实值提供了一个下限,那么这个高估问题就可以得到解决。事实上,由于策略评估和改进通常只使用策略的价值,我们可以学习一个不那么保守的下界Q函数,这样只有策略下的Q函数的期望值是下界的,而不是逐点下限。我们提出了一种通过对标准基于价值的RL算法进行简单修改来学习这种保守Q函数的新方法。我们的方法背后的关键思想是在状态动作元组上适当选择分布下最小化值,然后通过在数据分布上加入最大化项来进一步收紧该界限。
我们的主要贡献是一个算法框架,我们称之为保守Q学习(CQL),用于通过在训练期间对Q值进行正则化来学习价值函数的保守下限估计。我们对CQL的理论分析表明,只有策略下限Q函数的期望值才是真正的策略值,防止了可能出现的逐点下界Q函数的额外低估,这通常是在探索文献[48, 28]的相反背景下进行了探索。我们还通过经验证明了我们的Q函数估计误差方法的稳健性。我们的实用算法将这些保守估计用于策略评估和离线RL。CQL可以在许多标准的在线RL算法[21, 9]之上用不到 20 行代码来实现,只需将CQL正则化项添加到Q函数更新中即可。在我们的实验中,我们展示了CQL在具有复杂数据集组成的域中的离线RL的功效,在这些域中,通常已知先前的方法表现不佳[14]和具有高维视觉输入的域[5, 3]。在许多基准任务上,CQL的性能比以前的方法高出2-5倍,并且是唯一一种在从人类交互中收集的许多真实数据集上优于简单行为克隆的方法。
2 Preliminaries

3 The Conservative Q-Learning (CQL) Framework
在本节中,我们开发了一种保守Q学习(CQL)算法,使得学到的Q函数下策略的期望值下限为其真实值。Q值的下限可防止由于OOD动作和函数逼近误差[36, 32]而导致离线RL设置中常见的高估。我们使用术语CQL来泛指Q学习方法和actor-critic方法,尽管后者也使用显式策略。我们首先关注CQL中的策略评估步骤,它可以单独用作离线评估程序,也可以集成到完整的离线RL算法中,我们将在3.2节中讨论。
3.1 Conservative Off-Policy Evaluation



3.2 Conservative Q-Learning for Offline RL


当函数逼近或采样误差使OOD动作具有更高的学习Q值时,CQL备份预计会更稳健,因为使用更喜欢分布内动作的Q值更新策略。正如我们将在附录B中凭经验展示的那样,没有明确约束或规范Q函数的先前离线RL方法可能不具备这种鲁棒性。
总而言之,我们展示了CQL RL算法学习了足够大的下界Q值,这意味着最终策略至少达到了估计值。我们还表明,Q函数是差距扩大的,这意味着它应该只高估分布内和分布外动作之间的差距,从而防止OOD动作。
3.3 Safe Policy Improvement Guarantees
在第3.1节中,我们提出了Q函数训练的新目标,使得策略在生成的Q函数下的期望值的下限为策略的实际性能。在第3.2节中,我们使用学到的保守Q函数来改进策略。在本节中,我们展示了这个过程实际上优化了一个明确定义的目标,并为CQL提供了一个安全的策略改进结果,沿着Laroche et al. [35]的定理1和2。


总而言之,CQL优化了一个定义明确的、受惩罚的经验RL目标,并对行为策略进行了高置信度的安全策略改进。改进的程度受到较高采样误差的负面影响,随着观察到更多样本而衰减。
4 Practical Algorithm and Implementation Details

Implementation details. 我们的算法只需要在soft actor-critic (SAC)[21]的标准实现之上添加20行代码,用于连续控制实验,在QR-DQN [9]之上用于离散控制实验。权衡因子通过拉格朗日双梯度下降自动调整以实现连续控制,并固定在附录F中描述的离散控制的常数值。我们使用来自SAC的默认超参数,除了将策略的学习率选择为3e-5 (Q函数为3e-4或1e-4),如定理3.3所述。详细的细节在附录F中提供。
5 Related Work
我们现在简要讨论离线RL和异策评估中的先前工作,将这些工作与我们的方法进行比较和对比。附录E中提供了有关相关工作的更多技术讨论。
Off-policy evaluation (OPE). 已经使用了几种不同的范式来执行异策评估。早期的工作[53, 51, 54]使用对蒙特卡洛回报的每个动作重要性抽样来获得OPE回报估计量。最近的方法[38, 19, 42, 64]通过某种形式的动态规划[36]直接估计状态分布重要性比来使用边缘化重要性采样,并且通常以偏差为代价表现出比每个动作重要性采样更小的方差。因为这些方法使用动态规划,所以它们可能会遭受OOD动作[36, 19, 22, 42]。相比之下,CQL中的正则化器由于其间隙扩大行为而明确解决了OOD动作的影响,并获得了保守的价值估计。
Offline RL. 如第2节所述,离线Q学习方法存在与OOD动作相关的问题。先前的工作试图通过将学习策略限制为"接近"行为策略来解决这个问题,例如通过KL散度[29, 62, 50, 57]、Wasserstein距离[62]或MMD [32],然后仅在Bellman备份中使用从该受约束策略中采样的动作或应用价值惩罚。SPIBB [35, 43]方法使用Q学习算法中的行为策略bootstrap,用于看不见的动作。这些方法中的大多数都需要对行为策略πβ(a|s) [17, 32, 62, 29, 57, 58]进行单独估计的模型,因此受限于它们准确估计未知行为策略的能力[44],这在从多个来源收集数据的环境中可能特别复杂[36]。相反,CQL不需要估计行为策略。先前的工作已经探索了某些形式的Q函数惩罚[25, 61],但仅限于带有演示的标准在线RL设置。Luo et al. [40]通过在状态空间上强制执行线性外推属性来学习保守外推的价值函数,并学习动态模型以获得达到目标的任务的策略。Kakade和Langford [30]提出了CPI算法,该算法保守地改进了在线RL中的策略。
离线RL的替代先前方法估计某种不确定性以确定Q值预测的可信度[32, 3, 36],通常使用在线RL [49, 28, 48, 7]探索中的不确定性估计技术。由于离线RL [36]中不确定性估计的高保真度要求,这些方法在离线RL [17, 32, 36]中通常表现不佳。稳健的MDP [26, 52, 59, 46]一直是离线RL的流行理论抽象,但在策略改进方面往往高度保守。我们预计CQL不会那么保守,因为CQL不会低估所有状态动作元组的Q值。高置信度策略改进的工作[60]为改进提供了安全保证,但往往是保守的。CQL备份的间隙扩展特性(如定理3.4所示)与增加间隙的Bellman备份算子[6, 39]如何对在线RL中的估计误差更稳健有关。
Theoretical results. 我们的理论结果(定理3.5、3.6)与先前关于安全策略改进的工作有关[35, 52],并与Laroche et al. [35]的定理1和2进行了直接比较,提出了类似的对地平线的二次依赖和对计数的反平方根依赖。我们的边界改进了Petrik et al. [52]的∞-范数边界。先前的分析还侧重于近似动态规划中的误差传播[13, 8, 63, 56, 32],并且通常根据捕获分布偏移影响的集中性系数获得界限。
6 Experimental Evaluation
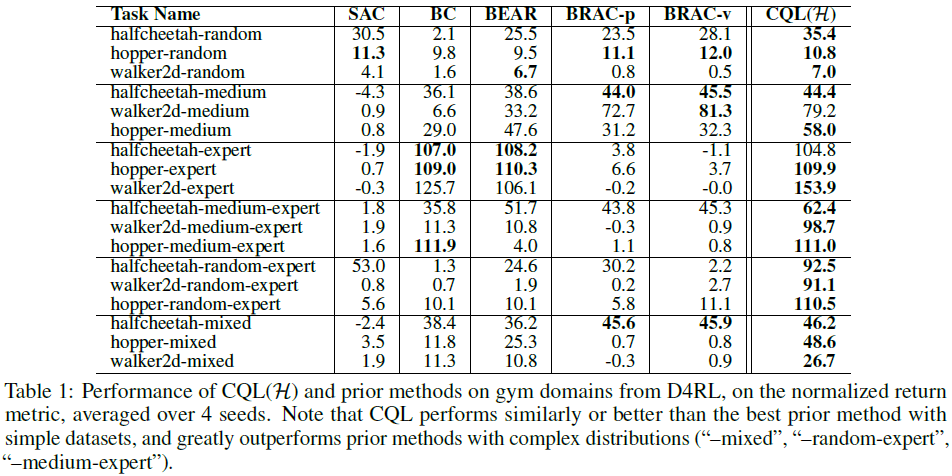
我们在一系列领域和数据集组合上将CQL与先前的离线RL方法进行比较,包括连续和离散的动作空间、不同维度的状态观察和高维图像输入。我们首先使用算法1中的CQL(H)在来自D4RL基准[14]的连续控制数据集上评估actor-critic CQL。我们比较了:使用策略约束的先前离线RL方法——BEAR [32]和BRAC [62];SAC [21],一种我们适应离线环境的异策actor-critic方法;和行为克隆(BC)。
Gym domains. gym领域的结果如表1所示。BEAR、BRAC、SAC和BC的结果基于Fu et al. [14]报告的数字。在从单个策略生成的数据集上,标记为"-random"、"-expert"和"-medium",CQL大致匹配或超过最好的先前方法,但差距很小。然而,在组合了多个策略("-mixed"、"-medium-expert"和"-random-expert")的数据集上,这些策略在实际数据集中更常见,CQL大大优于先前的方法,有时因为高达2-3倍。
Adroit tasks. D4RL中更复杂的Adroit [55]任务(如下图所示)需要使用来自人类演示的有限数据来控制24自由度机械手。就数据集组成和高维而言,这些任务比gym任务要困难得多。之前的离线RL方法通常很难在这些任务上学习有意义的行为,最强的基线是BC。如表2所示,CQL变体是唯一优于BC的方法,其得分是次佳离线RL方法的2-9倍。具有![]() (之前的策略)的CQL(ρ)在许多此类任务上优于CQL(H),因为更高的动作维度导致CQL(H)重要性权重的方差更高。两种变体都优于先前的方法。
(之前的策略)的CQL(ρ)在许多此类任务上优于CQL(H),因为更高的动作维度导致CQL(H)重要性权重的方差更高。两种变体都优于先前的方法。

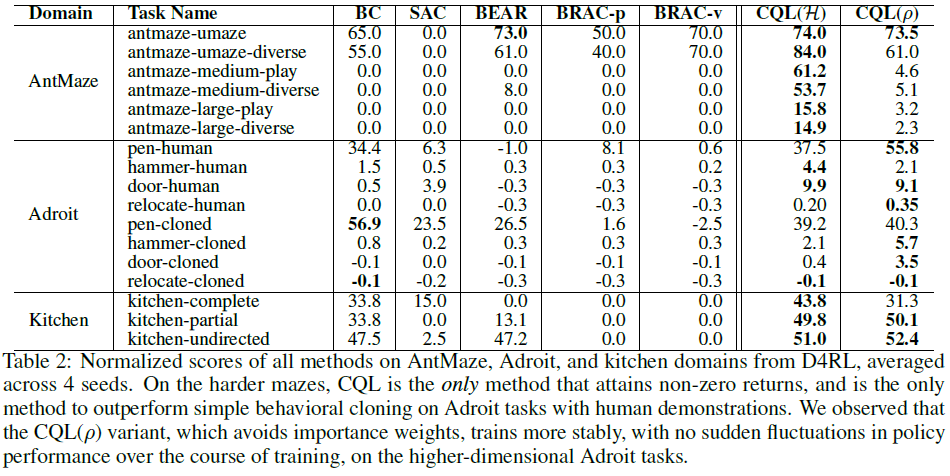
AntMaze. 这些D4RL任务需要组合次优轨迹的部分,以形成更优的策略来实现MuJoco Ant机器人的目标。先前的方法在更简单的U形迷宫上取得了一些进展,但只有CQL能够在更难的中型和大型迷宫上取得有意义的进展,大大优于先前的方法。
Kitchen tasks. 接下来,我们在D4RL [16]的Franka kitchen域[20]上评估CQL。目标是控制一个9-DoF机器人在单集中顺序操作多个对象(微波炉、水壶等)以达到所需的配置,每个达到目标配置的对象只有稀疏的0-1完成奖励。这些任务尤其具有挑战性,因为它们需要组成部分轨迹、精确的长视距操纵以及处理人工提供的远程操作数据。如表2所示,CQL在此设置中优于先前的方法,并且是唯一优于行为克隆的方法,在所有任务上的成功率均超过40%。
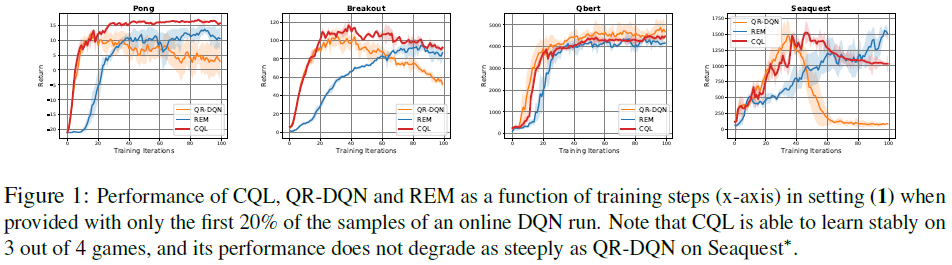
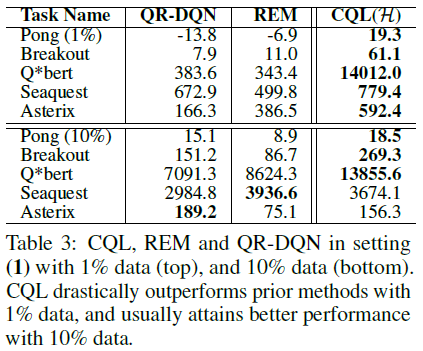
Offline RL on Atari games. 最后,我们在基于图像的离线Atari游戏中评估了CQL(算法1)的离散动作Q学习变体[5]。我们在Agarwal et al. [3]详细评估的五项Atari任务(Pong、Breakout、Qbert、Seaquest和Asterix)上将CQL与REM [3]和QRDQN [9]进行了比较,使用作者发布的数据集。
遵循Agarwal et al. [3]的评估协议,我们对两种类型的数据集进行了评估,这两种数据集都是由[3]发布的DQN-replay数据集生成的:(1) 由在线DQN智能体观察到的前20%样本组成的数据集 (2) 数据集仅包含在线DQN智能体观察到的所有样本的1%和10%([3]中的图6和7)。在设置(1)中,如图1所示,CQL通常实现与QR-DQN和REM相似或更好的性能。当仅使用1%或10%的数据时,在设置(2)(表3)中,CQL大大优于REM和QR-DQN,尤其是在更难的1%条件下,实现了最好的36倍和6倍的回报分别在Q*bert和Breakout上的先验方法。
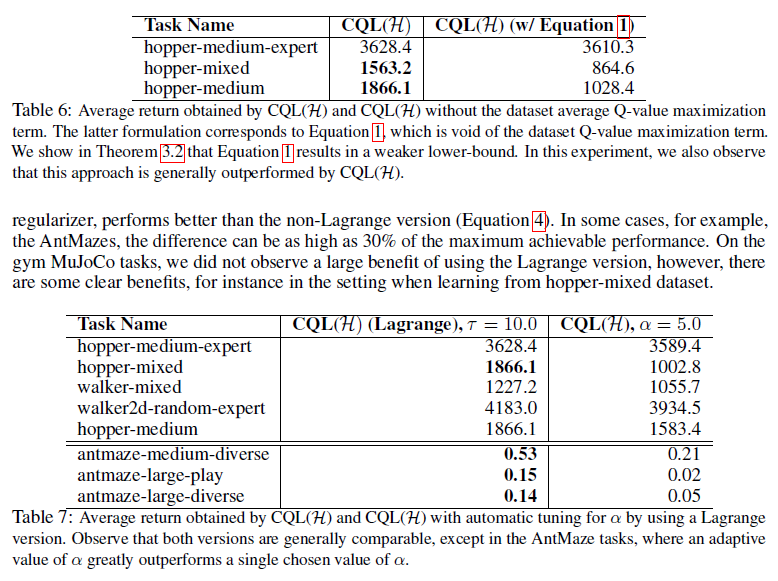
Analysis of CQL. 最后,我们进行实证评估以验证CQL确实降低了价值函数,从而实证验证了定理3.2,附录D.1。为此,我们估计了CQL预测的学习策略的平均值,![]() ,并在表4中报告了与策略 k 的实际折扣回报的差异。我们还估计这些基线值,包括在具有不同集合大小的Q函数的集合[21, 18]下的最小预测Q值,这是防止Q值过高[18, 21, 23]和BEAR [32]的标准技术,一种策略约束方法。结果表明,CQL学习了所有三个任务的下限,而基线容易被高估。我们还评估了使用公式1的CQL变体,并观察到与CQL(H)相比,结果值更低(即低估了真实值)。根据定理3.2,这提供了经验证据,表明CQL(H)比等式1中的逐点界限更严格。
,并在表4中报告了与策略 k 的实际折扣回报的差异。我们还估计这些基线值,包括在具有不同集合大小的Q函数的集合[21, 18]下的最小预测Q值,这是防止Q值过高[18, 21, 23]和BEAR [32]的标准技术,一种策略约束方法。结果表明,CQL学习了所有三个任务的下限,而基线容易被高估。我们还评估了使用公式1的CQL变体,并观察到与CQL(H)相比,结果值更低(即低估了真实值)。根据定理3.2,这提供了经验证据,表明CQL(H)比等式1中的逐点界限更严格。
我们还提供了一项实证分析,以表明定理3.4,即CQL是差距扩大,在附录B中在实践中成立,并在附录G中对CQL中使用的各种设计选择进行了消融研究。

7 Discussion
我们提出了保守Q学习(CQL),这是一种用于离线RL的算法框架,可以学习策略价值的下限。根据经验,我们证明了CQL在广泛的离线RL基准任务上优于先前的离线RL方法,包括复杂的控制任务和具有原始图像观察的任务。在许多情况下,CQL的性能大大优于性能最佳的先前方法,超过其最终回报2-5倍。CQL的简单性和有效性使其成为解决各种现实世界离线RL问题的有希望的选择。然而,仍然存在许多挑战。虽然我们证明CQL在表格、线性和非线性函数逼近情况的子集中学习Q函数的下界,但对具有深度神经网络的CQL的严格理论分析留待未来工作。此外,离线RL方法与标准监督方法一样容易受到过拟合的影响,因此未来工作的另一个重要挑战是设计简单有效的早期停止方法,类似于监督学习中的验证误差。
Appendices
A Discussion of CQL Variants

B Discussion of Gap-Expanding Behavior of CQL Backups



C Theorem Proofs






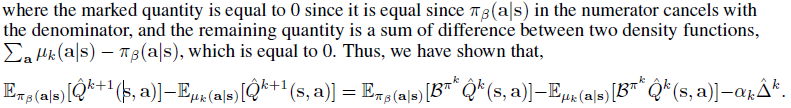

D Additional Theoretical Analysis
在本节中,我们对CQL的其他属性进行了理论分析。为了便于展示,我们在没有抽样误差的情况下陈述并证明了附录D.1和D.2中的定理,但正如附录C中广泛讨论的那样,我们可以通过添加由于抽样误差而引起的额外项来扩展这些结果中的每一个。
D.1 CQL with Linear and Non-Linear Function Approximation






D.2 Choice of Distribution to Maximize Expected Q-Value in Equation 2



D.3 CQL with Empirical Dataset Distributions

D.4 Safe Policy Improvement Guarantee for CQL





E Extended Related Work and Connections to Prior Methods

F Additional Experimental Setup and Implementation Details




G Ablation Studies