郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

2019 IEEE INTERNATIONAL CONFERENCE ON MULTIMEDIA AND EXPO (ICME), pp.1396-1401, (2019)
ABSTRACT
由于高速运动模糊和低动态范围,传统的基于帧的相机在物体检测方面遇到了重要挑战,特别是在自动驾驶方面。基于事件的相机利用高时间分辨率和高动态范围的优势,为应对挑战带来了新的视角。受此事实启发,本文提出了一种结合基于事件和基于帧的视觉用于车辆检测的联合框架。特别是,两个独立的基于事件和基于帧的流被合并到卷积神经网络(CNN)中。 此外,为了适应来自基于事件的相机的异步事件,使用卷积脉冲神经网络(SNN)生成视觉注意力图,以便可以同步两个流。此外,引入了Dempster-Shafer理论,将CNN的两个输出合并到一个联合决策模型中。实验结果表明,所提出的方法优于仅使用基于帧的信息的状态方法,特别是在快速运动和具有挑战性的照明条件下。
Index Terms— Event-based Vision, Neuromorphic Cameras, Convolutional Neural Networks, Spiking Neural Networks, Dempster-Shafer Theory
1. INTRODUCTION
自动驾驶系统近年来得到了广泛的研究,未来将越来越多地被公众采用[1, 2]。目前,视觉相机与雷达、激光雷达、超声波一起构成了自动驾驶系统的支柱[3],可以为机器视觉模型获得高空间分辨率和足够的视频[4, 5]。事实上,视觉传感器在了解真实驾驶场景方面发挥了关键作用,在基于视觉的智能系统中准确、及时地检测危险车辆对于预防交通事故极为重要。
以前,已经进行了大量研究,重点是使用基于帧的相机,即主动像素传感器(APS)进行车辆检测[4, 6]。最早实现实时检测的方法主要是基于局部特征的级联检测。在那之后,目标检测系统通过深度神经网络得到了显著增强,例如Fast R-CNN [7]和Faster R-CNN [8]。此外,还出现了包括SSD [9]和YOLOs [10, 11]的端到端对象检测模型。然而,那些基于帧的方法只有在特殊条件下才能达到令人满意的性能,包括慢动作和适当的照明。实际上,由于路况复杂,光照变化大,尤其是在过度曝光和光线不足的场景中,基于帧的相机仍然具有挑战性。此外,帧在高速运动中会出现运动模糊,导致后续算法无法捕捉到对象。
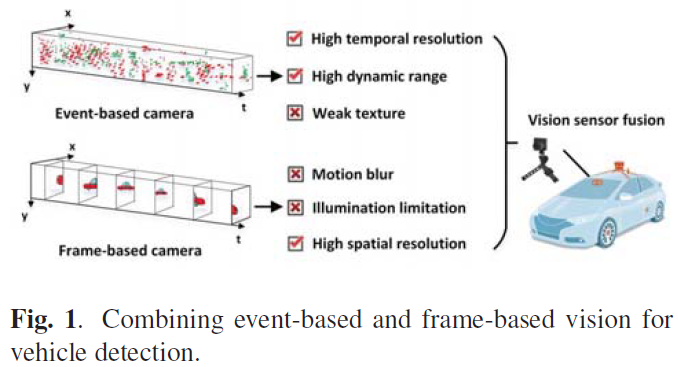
为了了解生物学方法和神经形态工程技术如何有助于推进人工视觉[12],研究基于帧的相机的一些缺点是令人鼓舞的。最近,基于事件的相机,即神经形态相机,如动态视觉传感器(DVS)[13]、ATIS [14]和DAVIS [15],是仿生视觉传感器,与基于帧的相机相比,它们以完全不同的方式工作:获取独立像素的异步事件流,而不是以固定速率提供基于帧的图像序列,如图1所示。与基于帧的相机相比,基于事件的相机具有一些关键优势:高时间分辨率(μs)、高动态范围(HDR)和低功耗,因为它可以传输稀疏事件且几乎没有冗余。此外,仅在强度变化时才输出事件,因此基于事件的相机是自然的物体移动检测器,并且在空间结构上存在纹理弱的缺陷。事实上,基于事件的相机逐渐应用于与运动估计相关的计算机视觉任务[16, 17, 18]。
针对基于帧的相机的不足,一些研究人员专注于基于事件相机的目标检测[17, 19, 20, 21]。Mesa et al. [17]提出了一种事件驱动的立体目标检测和跟踪算法,可以解决高速运动的目标遮挡问题。Li et al. [19]引入了一种递归自适应时间池化方法来提取运动不变特征以进行目标检测。Anton et al. [20]在具有快速运动或光照变化的挑战性条件下提出了一种多运动目标检测方法。此外,Chen [21]使用伪标签对DVS数据进行监督学习,以在自我运动下进行目标检测。然而,这些方法仅使用基于事件的流,而不使用基于帧的相机。事实上,基于事件的相机可以作为辅助基于帧的目标检测的主要信息[22, 23]。换句话说,结合基于事件和基于帧的视觉可以进一步提高检测性能。
受前人工作优缺点的启发,本文提出了一种基于DAVIS的联合检测框架(JDF),该框架同时输出常规帧和事件流。事实上,这项工作的目标不是开发最先进的检测器[8, 9, 10, 11]。相比之下,我们旨在克服以下挑战:1)如何利用基于事件和基于帧的流;2)稀疏和异步事件很好地应用于计算机视觉算法,特别是利用来自事件流的有效时空特征。作为结果,两个独立的流被集成到卷积神经网络(CNN)中。此外,为了适应来自基于事件的相机的异步事件,使用卷积脉冲神经网络(SNN)生成视觉注意力图,以便可以同步两个流。此外,在联合决策模型中引入了Dempster-Shafer机制[24],它在DDD17 [25]数据集上取得了令人印象深刻的性能,尤其是在快速运动和具有挑战性的照明条件下。
主要贡献如下:1)将Dempster-Shafer理论引入到JDF中,将基于事件和基于框架的视觉相结合;2)我们提出了一种卷积SNN来生成视觉注意图,从而为异步事件与深度学习算法之间的联系搭建了一座桥梁。此外,我们还证明了在检测任务中利用预训练模型的迁移学习是可能的;3)我们提供了一个标记和同步的数据集†包括帧和事件流,实验验证了所提出的框架的有效性,其中JDF优于基于帧的相机的最新方法。
†https://pkuml.org/resources/pku-ddd17-car.html
2. OUR APPROACH
在本节中,我们首先解释基于事件的相机的时空事件,并描述卷积SNN中的基本概念。然后,我们展示了提议的JDF中的组件。最后,我们介绍了在联合决策模型中应用的Dempster-Shafer理论。
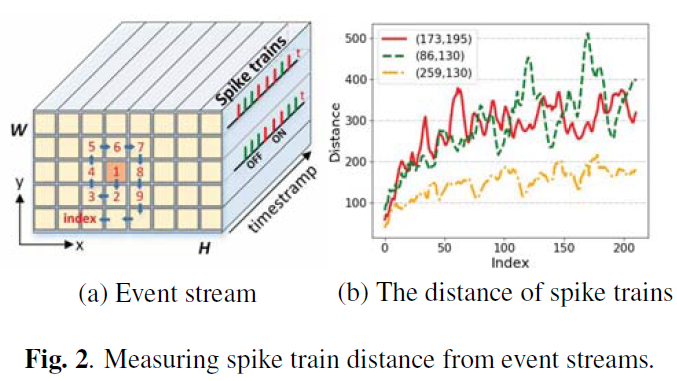
2.1. Spatial-Temporal Events


2.2. Convolutional Spiking Neural Network
许多工作[18, 19, 20, 21]表明,事件流能够以恒定的间隔转换为图像[18, 19, 21]或时间表面[20],因此可以应用于计算机视觉算法。然而,那些使用基于发放率的策略的方法尚未利用时空特征。受生物学视觉感受野的启发,卷积SNN用于根据输出神经元的发放率生成视觉注意图。
在网络拓扑中,两层网络使用3×3卷积核连接,如图3所示。第一层是事件流的输入,有2×W×H个神经元。换句话说,每个像素包括两个神经元,分别代表生物视网膜中的ON和OFF神经节细胞。此外,第二层是视觉注意力图的输出,具有W×H神经元,分别获得ON层或OFF层的发放率。
在这项研究中,我们使用LIF神经元[27]来模拟SNN中的神经元动力学,如下所示:
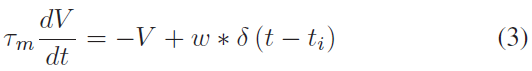
其中 V 是神经元膜电位,w 是突触权重,τm是时间常数。在两个脉冲之间,LIF的膜电位表示为:
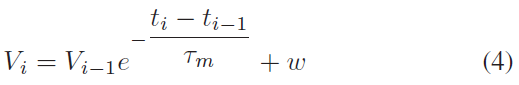
当 Vi 达到阈值时,它会发放一个脉冲。然后,Vi 重新设置为零,直到超过不应期。
2.3. Joint Detection Framework
所提出的框架如图3所示,有两个分支分别针对处理帧和事件流。实际上,该框架的一个核心是事件流是基于卷积SNN生成的视觉注意力图,详细信息在第2.2节中介绍。此外,另一个是将两个单独的流输入CNN,它利用来自预训练检测模型的迁移学习。
重要的是,我们要努力建立一个将事件流连接到现有检测器的桥梁[7, 8, 9, 10, 11]。从这个意义上说,考虑到准确性和复杂性的平衡,我们选择YOLOv3架构[11]作为公平的基准。因为它有G×G网格,B 预测每个网格单元的边界框,以及 C 类预测。在这项工作中,最后一个全连接(FC)层被调整为G×G×B×(C + 5)张量。
最后,基于Dempster-Shafer理论[24]将最后一个CNN层的两个输出整合为检测结果,通过结合相关假设概率的证据来获得综合判断。
对于目标检测,通用集表示边界框的各种可能状态,定义为:
![]()
其中 T 是目标假设,¬T 是非目标,{T, ¬T}是中间状态。
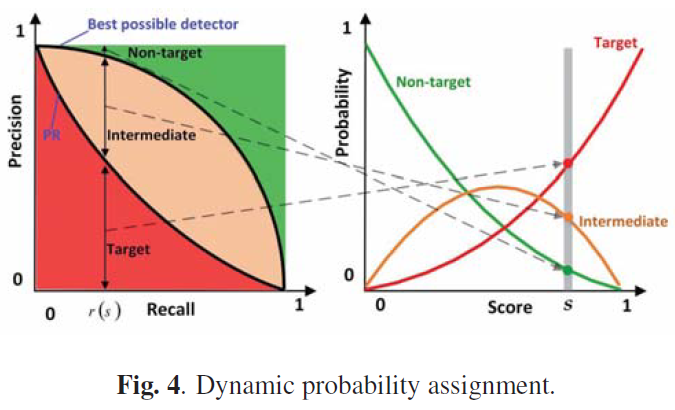
为了获得动态概率分配,训练好的精确召回模型被用来表示检测器的先验信息。同时,我们引入了一个理论上最好的检测器,如图4所示,它被建模为:
![]()
其中![]() 是召回 r 和性能参数 k 中最佳检测器的理论极限。
是召回 r 和性能参数 k 中最佳检测器的理论极限。
为了计算输出置信度分数S1和S2的假设的联合概率,基于Dempster-Shafer理论的组合规则表示为:
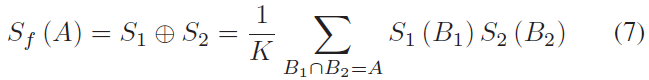
其中B1和B2是 Ω 的子集,K 是衡量全集之间冲突量的归一化常数,由下式给出:
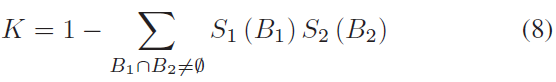
在动态概率分配之后,问题就变成了如何组合独立的源,换句话说,如何分别组合来自两个流的边界框和概率。基于Dempster-Shafer理论合并联合概率,然后采用非最大抑制(NMS)[6]来整合边界框。
3. EXPERIMENTS
在本节中,可以找到详细的实验设置、性能分数和代表性结果,如下所示。
3.1. Experimental Settings
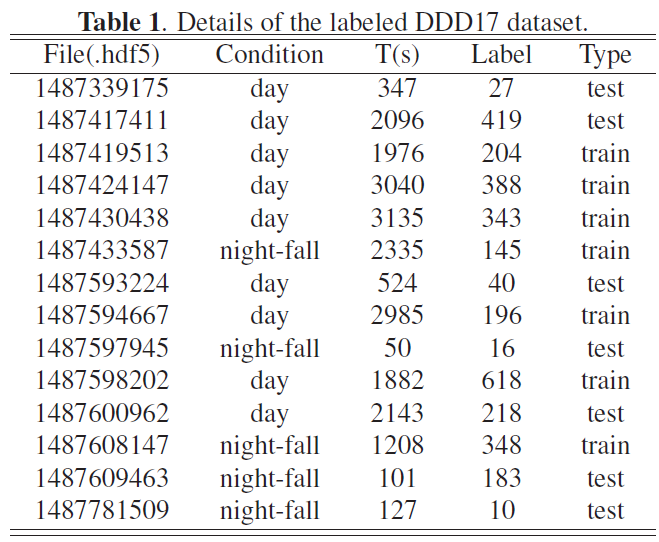
为了验证我们方法的有效性,我们在DDD17 [25]数据集上进行了实验,包括帧和事件流,该数据集有超过400 GB和12小时的346×260像素DAVIS传感器记录驾驶场景。为了获得准确的车辆检测标签,我们提供了一个手动标记的数据集,包括同步帧和事件流,如表1所示。此外,我们在标记的DDD17数据集上微调预训练的YOLOv3模型,在整个实验中设置0.5重叠阈值和0.5分数。所有时间信息都在Tesla K80上。
为了对提出的联合检测框架(JDF)进行全面评估,我们将JDF与最先进的模型和两个基线进行了比较,包括:
(1) APS [11]:一种基于帧的检测方法,仅将APS帧作为输入。
(2) 基于发放率的DVS (R-DVS)[21]:采用基于发放率的方法将事件流转换为以10毫秒为间隔的帧作为输入的方法。
(3) 基于脉冲的DVS (S-DVS):与R-DVS不同,S-DVS使用卷积SNN的基于脉冲的方法来生成视觉注意力图。
(4) APS + S-DVS:APS和S-DVS的两个流在输入检测器之前合并成帧。
为了比较不同的方法,精度,召回率和平均精度(AP),每秒帧数(FPS)被用作评估指标,这是目标检测中使用最广泛的指标。
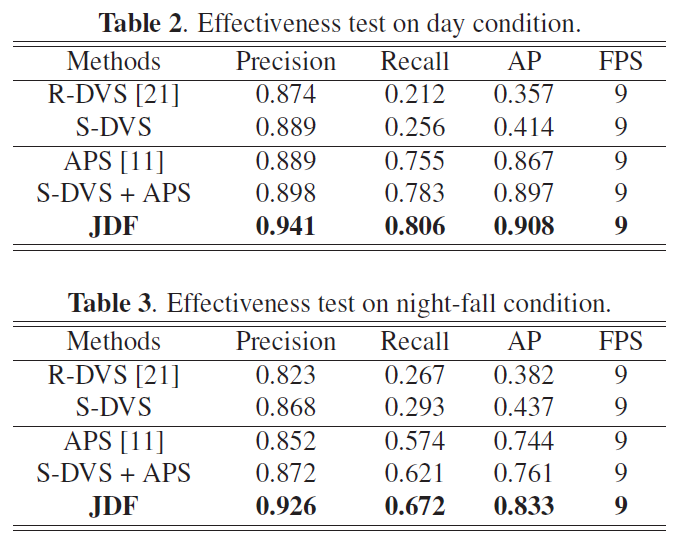

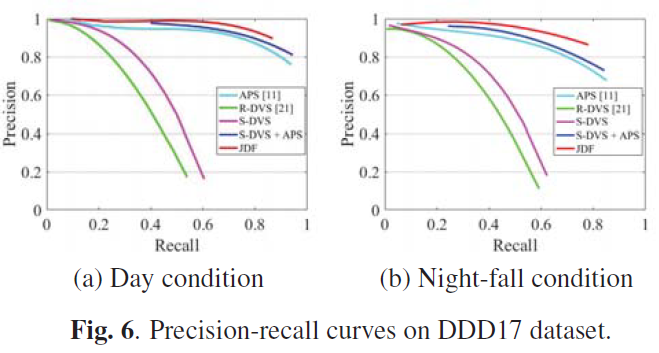
3.2. Effectiveness Test
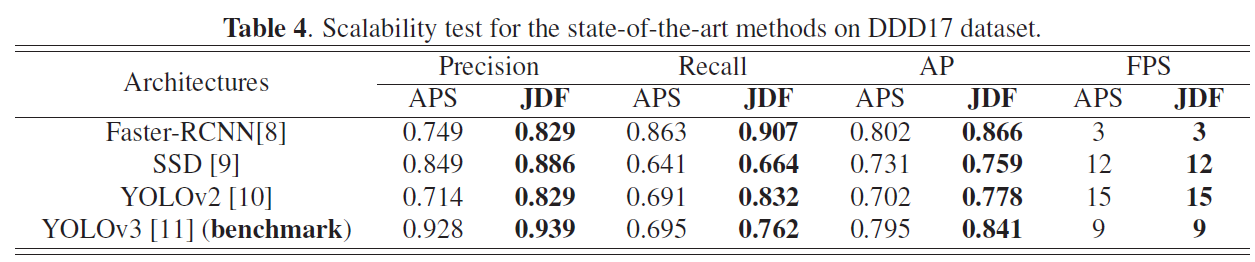
3.3. Scalability Test
4. CONCLUSION
在本文中,我们提出了一种结合事件流和帧的联合检测框架(JDF),旨在基于Dempster-Shafer理论使两个流相互受益。正如在DDD17数据集上的实验结果所证明的那样,我们的JDF可以显著改进两个流框架,并且优于仅使用基于帧的相机的最先进的方法,特别是在快速运动和具有挑战性的照明条件下。