郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

CVPR 2018
Abstract
事件相机是仿生视觉传感器,可以自然地捕捉场景的动态,过滤掉多余的信息。本文提出了一种深度神经网络方法,该方法可以在具有挑战性的运动估计任务中释放事件相机的潜力:预测车辆的转向角。为了充分利用这种传感器-算法组合,我们将最先进的卷积架构应用于事件传感器的输出,并在公开可用的大规模事件相机数据集(≈1000km)上广泛评估我们的方法的性能。我们对事件相机为何即使在传统相机出现故障的情况下也能提供稳健的转向预测提供了定性和定量解释(例如具有挑战性的照明条件和快速运动)。最后,我们展示了利用迁移学习从传统视觉到基于事件的视觉的优势,并表明我们的方法优于基于标准相机的最先进算法。
Multimedia Material
本文随附的视频可在以下网址找到:https://youtu.be/_r_bsjkJTHA。
1. Introduction
事件相机,例如动态视觉传感器(DVS)[1],是仿生传感器,与传统相机相比,它不会以固定帧速率获取完整图像,而是具有仅输出强度变化的独立像素(称为"事件")在它们发生时异步。因此,事件相机的输出不是图像序列,而是异步事件流。与传统相机相比,事件相机具有多种优势:非常高的时间分辨率(微秒)、非常高的动态范围(HDR)(140 dB)以及低功率和带宽要求。此外,由于事件是由场景中的移动边缘生成的,事件摄像机是自然的运动检测器,会自动过滤掉任何时间冗余信息。由于其操作原理和非常规输出,事件相机代表了计算机视觉的范式转变,因此需要新的算法来利用它们的功能。事实上,事件相机在与运动估计相关的所有任务中都具有许多优势[2, 3, 4, 5, 6]。
最近,深度学习(DL)算法在运动估计领域的许多应用中表现良好[7, 8, 9]。在这项工作中,我们建议通过基于DL的解决方案来释放事件相机的潜力,并展示这种组合在转向角预测这一具有挑战性的任务中的力量。正如之前的工作[9]已经指出的那样,最终需要基于学习的方法来处理复杂的场景,更重要的是,自动驾驶汽车将在其中进行机动的极端情况。然而,这项工作的目标不是开发一个框架来实际控制自动驾驶汽车或机器人,正如[10]中已经提出的那样。相反,我们旨在了解基于学习的运动估计任务方法如何受益于事件摄像机对运动的自然响应、其固有的数据冗余减少、高速和非常高的动态范围。我们表明,事件摄像机结合专门设计的神经网络以低延迟捕捉场景动态的能力优于基于标准摄像机的最先进系统(图1)。
总体而言,本文做出以下贡献:
- 我们展示了深度学习在回归任务中基于事件的视觉的第一个大规模(≈100万张图像,覆盖超过1000公里)应用。此外,我们提供了结果和解释,说明为什么事件相机比传统相机更适合运动估计任务。
- 我们将最先进的卷积架构[11]应用于事件摄像机的输出。此外,我们表明,即使网络是在传统相机收集的帧上训练的,也可以在分类任务[12]上利用来自预训练卷积网络的迁移学习。
- 我们通过一组广泛的定性和定量实验证明了我们方法的有效性,这些实验在公开可用的数据集上优于最先进的系统。
本文的其余部分安排如下。第2节回顾了有关该问题的相关工作。第3节描述了提议的方法,其性能在第4节和第5节中进行了广泛评估。结果在第6节中讨论,结论在第7节中得出。

2. Related Work
为自动驾驶制定稳健的策略是一个具有挑战性的研究问题。高度工程化的模块化系统在城市和越野场景中都表现出令人难以置信的性能[13]。解决该问题的另一种方法是将视觉观察直接映射到控制动作,紧密耦合问题的感知和控制部分。学习视觉运动策略的第一次尝试是使用ALVINN [14]完成的,其中使用浅层网络直接从图像中预测动作。尽管它只在简单的场景中取得了成功,但它暗示了神经网络在自主导航方面的潜力。最近,NVIDIA使用CNN从视频帧中学习驾驶策略[15]。尽管是一种非常简单的方法,但学习到的控件能够在基本场景中驾驶汽车。之后,已经花费了一些研究努力来学习更强大的感知动作模型[9, 8],以应对城市环境中通常遇到的视觉外观的多样性和不可预测性。Xu et al. [9]提出利用大规模驾驶视频数据集并进行迁移学习以生成更强大的策略。该模型表现出良好的性能,但仅限于一组离散的动作,并且容易在策略空间的未展示区域出现故障。在[8]中,作者提出了一种方法,可以直接从帧回归转向角,同时提供可解释的策略。然而,在性能方面,相对于[15]几乎没有改进。
所有以前的方法都对传统的基于帧的相机获取的图像进行操作。相比之下,我们提出根据事件相机产生的数据(异步、像素级亮度变化,延迟极低和动态范围高)学习策略,这些数据自然地响应场景中的运动。
[16, 17, 18, 19, 10]初步展示了事件相机为解决模式识别问题提供丰富数据的能力。在所有这些问题中,机器学习算法都应用于事件相机获取的数据以解决分类问题,并且通常在有限大小的数据集上进行训练和测试。例如[16, 17, 18]使用事件数据上的神经网络来识别一副牌的卡片(4类)、面孔(7类)或字符(36类)。一个类似的案例是[19],其中一个网络被训练来识别动态场景中的三种手势(石头、纸、剪刀)。到目前为止,未知变量连续的估计问题是通过离散化来解决的,即将解空间划分为有限数量的类。例如,[10]中的捕食者-猎物机器人就是这种情况,其中一个网络训练了来自动态有源像素视觉传感器(DAVIS)[20]的事件和灰度帧的组合输入,产生了四个输出的一个:猎物位于捕食者视野(FOV)的左侧、中心或右侧,或者在FOV中不可见。另一个例子是[21]中的光流估计方法,其中网络从具有8个不同方向和8个不同速度(即64个类别)的集合中生成运动向量。
与之前所有方法的分类近似相反,本文从回归的角度解决了一个连续估计问题(转向角预测)。因此,我们是第一个以有原则的方式解决事件相机的连续估计问题,而不诉诸解决方案空间的划分;我们的网络产生的角度可以取任何值,而不仅仅是离散的,在[−180度, 180度]范围内。此外,与以前使用小型数据集的基于事件的视觉学习工作相比,我们展示了迄今为止最大和最具挑战性(由于场景可变性)基于事件的数据集的结果。
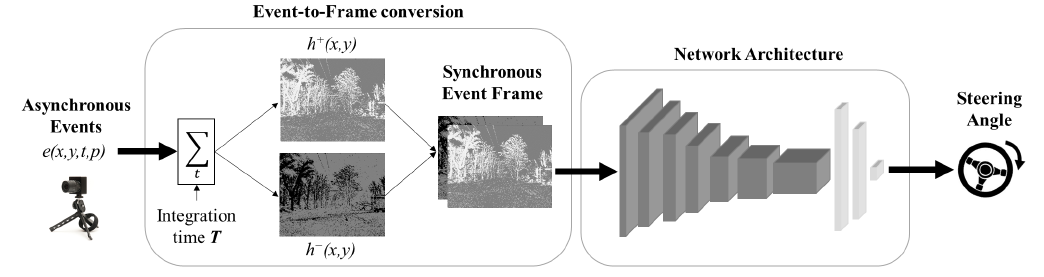
图2:所提出方法的框图。事件相机的输出在指定的时间间隔T内收集到帧中,使用取决于事件极性(正和负)的单独通道。生成的同步事件帧由受ResNet启发的网络进行处理,该网络产生对车辆转向角的预测。
3. Methodology
我们的方法旨在通过安装在汽车上的前视DVS传感器[1]预测方向盘指令。如图2所示,我们提出了一种学习方法,该方法将事件摄像机获取的视觉信息作为输入,并输出车辆的转向角。通过在恒定时间间隔内逐像素累积,将事件转换为事件帧。然后,深度神经网络通过解决回归任务将事件框架映射到转向角。下面,我们详细介绍学习过程的不同步骤。
3.1. Event-to-Frame Conversion
所有最近和成功的深度学习算法都是为传统的视频输入数据(即基于帧的和同步的)设计的,以从传统处理器中受益。为了利用这些技术,需要将异步事件转换为同步帧。为此,我们以像素方式在给定时间间隔 T 内累积事件1 ek = (xk, yk, tk, pk),获得事件的2D直方图。由于事件相机自然地响应移动边缘,这些事件直方图是编码事件相机和场景之间的相对运动的地图。此外,由于事件摄像机的传感原理,它们没有冗余。
受[18]的启发,我们对正和负事件使用单独的直方图。正事件的直方图是:
![]()
其中 δ 是Kronecker delta,负事件的直方图h-定义类似,使用pk = -1。直方图h+和h-被堆叠以产生两通道事件图像。不同极性的事件存储在不同的通道中,而不是具有极性平衡的单个通道(h+-h-),以避免在积分间隔 T 期间在同一像素中发生相反极性事件的情况下由于抵消而导致信息丢失。
1 事件ek由预定义幅度的相对亮度变化的时空坐标(xk, yk, tk)及其极性pk ∈ {-1, +1}(即亮度变化的符号)组成。
3.2. Learning Approach
3.2.1. Preprocessing. 输入和输出数据的正确归一化对于可靠地训练任何神经网络都是必不可少的。由于道路几乎总是笔直的,因此驾驶汽车的转向角分布主要在[−5度, 5度]中选取。这种不平衡的分布会导致有偏差的回归。此外,车辆经常因为暴露在交通灯和行人面前而静止不动。在没有运动的情况下,只会产生嘈杂的事件。为了处理这些问题,我们对输出变量(即转向角)进行了预处理,以实现成功的学习。为了解决第一个问题,在训练时只部署了与小于5度的转向角对应的数据的30%。对于后者,我们过滤掉了与小于20km h-1的车辆速度相对应的数据。为了去除异常值,过滤后的转向角随后被修剪为其标准差的三倍,并归一化为[−1, 1]范围。在测试时,所有与小于5度的转向角对应的数据都被考虑在内,以及20km h-1以下的场景。回归的转向角被非规范化为[-180度, 180度]范围内的输出值。最后,我们将网络输入(即事件图像)缩放到[0, 1]范围。
3.2.2. Network Architecture. 为了在我们的研究案例中释放卷积架构的力量,我们首先必须调整它们以适应事件摄像机的输出。最初,我们堆叠不同极性的事件帧,创建一个2D事件图像。之后,我们部署了一系列ResNet架构,即ResNet18和ResNet50,因为事实证明它们随着层数(深度)的增加更容易优化,并且可以更好地应对过拟合[11]。由于这些网络是为图像分类目的而设计的,因此我们将它们用作回归问题的特征提取器,仅考虑它们的卷积层。为了将从最后一个卷积层提取的图像特征编码为矢量化描述符,我们使用了一个全局平均池化层[23],它返回特征的通道均值。事实证明,与直接添加全连接层相比,这种选择可以提高性能,因为它通过减少参数总数来最小化过拟合,并且更好地传播梯度。在全局平均池化之后,我们添加了一个全连接(FC)层(ResNet18为256维,ResNet50为1024维),然后是ReLU非线性和最终的一维全连接层,以输出预测的转向角。

4. Experimental Setup
4.1. Dataset
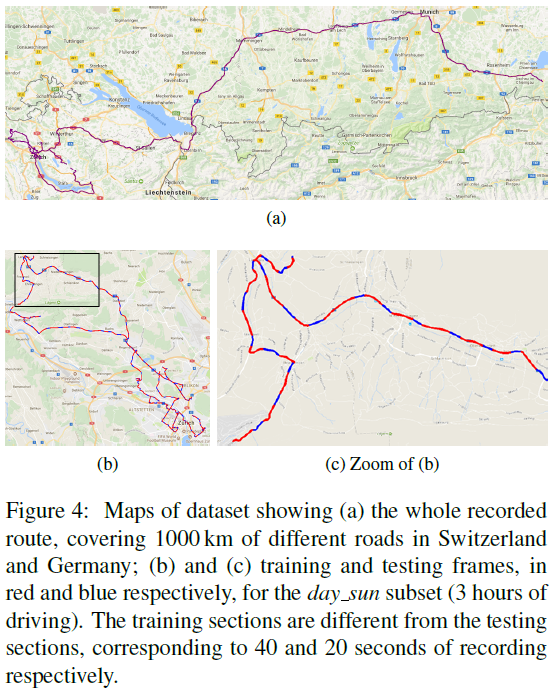
为了从事件图像中预测转向角度,我们使用公开的DAVIS Driving Dataset 2017 (DDD17)[22]。它包含汽车在不同且具有挑战性的天气、道路和照明条件下收集的大约12小时带注释的驾驶记录(总共432 GB)。该数据集包括异步事件以及同步的灰度帧,由DAVIS2传感器[20]同时收集。根据数据集作者提供的标签,我们将记录分为四个子集:day、day_sun、evening和night。子集不仅在照明和天气条件方面有所不同,而且在行驶的路线上也有所不同。图3描述了一些数据样本。
由于在驾驶时,后续帧通常非常相似并且具有几乎相同的转向角,因此将数据集随机划分为训练和测试子集会导致过度乐观的估计。因此,为了正确测试学习模型的泛化能力,我们将数据集划分如下。我们将记录分成连续且不重叠的短序列,每个短序列只有几秒钟,并使用这些序列的备用子集进行训练和测试。特别是,训练序列对应于40秒的记录,而测试序列对应于20秒。如图4所示,训练子集与测试子集交替出现,从而产生不同的样本。
4.2. Performance Comparison on Different Types of Images
我们使用三种不同类型的视觉输入来预测转向角:
- 灰度图像,
- 灰度图像的差异,
- 事件积累产生的图像。
灰度图像对应于来自传统相机的绝对强度帧(图3的第一列),它们对应于最先进的转向角预测系统的典型输入(第2节)。正如上面已经指出的,来自DAVIS传感器的灰度帧可以与事件进行公平比较,因为它们由相同的光电二极管产生,它们观察到的场景完全相同。我们还将我们的方法与强度图像的时间差异进行了比较(图3的第二列)。如图所示,它们类似于事件图像(图3的第三列)。强度差异包含时间信息,并且正如实验(第5节)所示,它们提供了比绝对强度图像更强的基线,用于比较事件数据架构的结果。更具体地说,事件相机报告预定义大小 C 的逐像素对数亮度变化:
![]()
其中L(t) = log I(t),I(t)是图像平面上的强度。当这些变化(2)在某个时间间隔内聚合时,它们会量化每个像素发生的亮度变化量(增加或减少),
![]()
对于一个小的时间间隔,两个连续灰度帧的差异是这种强度变化(3)的一阶(Taylor)近似值,因为:
![]()
这就是为什么图3的第二列和第三列中的图像(它们基本上编码了指定时间间隔内的时间亮度变化)看起来相似的原因。
如在[9]中,我们选择相对于当前帧(事件或灰度帧)在未来1/3秒处的方向盘角度作为地面实况方向盘角度。
4.3. Performance Metrics

5. Experiments
我们设计了我们的实验来调查以下问题:
- 用于生成事件框架的事件集成时间对系统性能有何影响?
- 使用事件图像而不是灰度或灰度差作为网络输入的优势是什么?
- 我们的方法是否可以扩展到非常大的输入空间?它与基于传统相机的最先进方法相比如何?
为了回答第一个问题,我们分析了我们系统在一系列积分时间内的性能(第5.1节)。关于第二个问题,我们对4.1节中详述的四个数据集的子集进行了广泛的研究,并强调了事件图像相对于灰度图像的优势(第5.2节)。最后,我们通过在整个数据集上学习单个网络来回答最后一个问题(第5.3节)。我们表明,尽管光照、天气和道路条件各不相同,但我们可以学习一个稳健且准确的回归器,该回归器的性能优于基于传统框架的最先进方法。

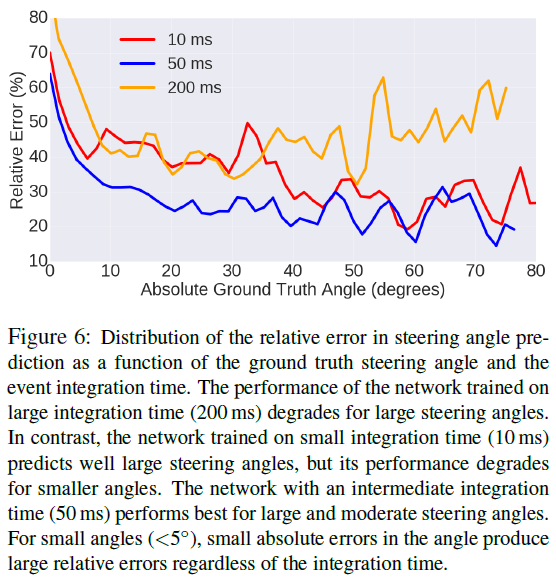
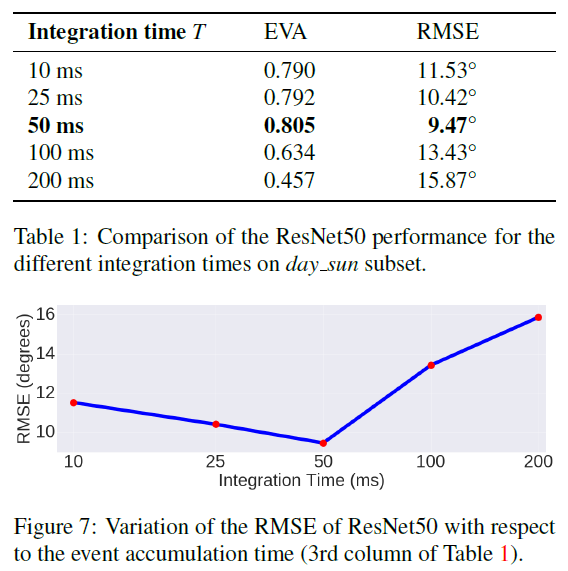
5.1. Sensitivity Analysis with Respect to the Event Integration Time
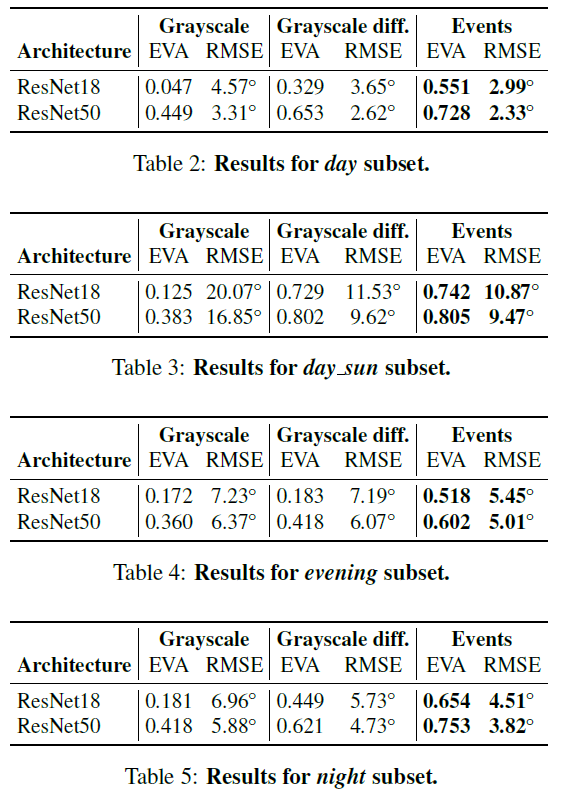
5.2. Results on Different Illumination Scenarios
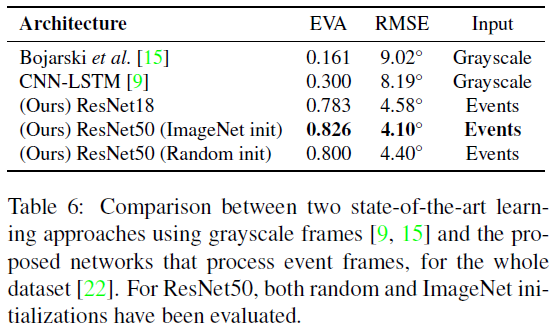
5.3. Results on the Entire Dataset
6. Discussion
网络在事件图像上比在灰度帧(或它们的差异)上产生更好的结果的很大原因在于它们捕捉场景动态的能力。在高速下,灰度帧会受到运动模糊的影响(例如,图3第一行的小路树),而事件图像由于事件摄像机的非常高的时间分辨率(微秒)和事实而保留了边缘细节。我们在馈送到网络的不同通道中获取正和负事件,从而避免信息丢失(第3.1节)。然而,为网络提供数据所需的时间聚合确实会影响延迟。此外,事件摄像机具有非常高的动态范围(HDR)(140 dB与数据集中灰度帧的55 dB范围相比[22])。因此,事件数据代表场景的HDR内容,这在传统相机中是不可能的,因为这需要较长的曝光时间。这是有益的,以便对不同的照明条件(明亮的白天、黑暗的夜晚、隧道中的突然过渡等)具有鲁棒性。此外,由于事件相机响应移动边缘并因此过滤掉时间冗余数据,它们比单独的灰度帧更能提供关于车辆运动的信息。如图1定性和图6定量所示,关注移动边缘有助于解决学习问题。为创建事件图像选择一个好的集成时间还可以提高性能(图7)。关于这个问题的有趣的未来工作是使用强化学习技术[25]来产生一个自适应集成时间策略,该策略取决于汽车的速度和观察到的场景。
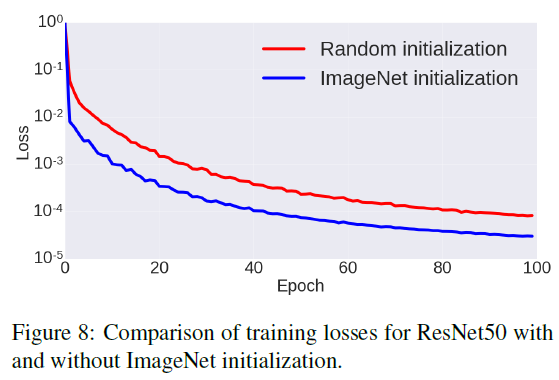
最先进的卷积网络需要大量数据来获取重要的运动特征。为了简化任务,我们展示了可以从使用传统图像训练的分类任务网络中转移知识。因此,我们能够解锁事件摄像机的功能来解决手头的任务。
7. Conclusion
在这项工作中,我们展示了基于DL的方法如何受益于事件摄像机对运动的自然响应,并在各种条件下准确预测汽车转向角。我们的DL方法专门设计用于处理事件传感器的输出,通过从事件帧中包含的运动线索中提取转向角度来学习预测转向角度。实验结果表明了该方法的鲁棒性,尤其是在灰度帧失败的情况下,例如大输入空间、具有挑战性的照明条件和快速运动。总之,我们表明它优于其他基于传统相机的最先进系统。我们鼓励读者观看随附的视频,网址为https://youtu.be/_r_bsjkJTHA。