郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Presented at the ICML 2017 Workshop on Machine Learning for Autonomous Vehicles
Abstract
动态视觉传感器(DVS)和动态有源像素视觉传感器(DAVIS)等事件相机可以通过提供标准有源像素传感器(APS)图像和DVS时间对比事件的并发流来补充其他自动驾驶传感器。APS流是一系列标准灰度全局快门图像传感器帧。DVS事件表示在特定时刻发生的亮度变化,在大多数照明条件下抖动约为一毫秒。它们具有>120 dB的动态范围和>1 kHz的有效帧速率,数据速率与30 fps(帧/秒)图像传感器相当。为了克服当前图像采集技术的一些限制,我们在这项工作中研究了在端到端驱动应用中使用组合的DVS和APS流。本文随附的数据集DDD17是带注释的DAVIS驾驶记录的第一个开放数据集。DDD17具有超过12小时的346x260像素DAVIS传感器,可记录白天、晚上、夜间、干燥和潮湿天气条件下的高速公路和城市驾驶,以及从汽车的车载诊断界面捕获的车速、GPS位置、驾驶员转向、油门和刹车。作为示例应用,我们使用卷积神经网络进行了初步的端到端学习研究,该网络经过训练可根据DVS和APS视觉数据预测瞬时转向角。
1 Introduction
机器学习和计算机视觉系统的快速改进推动了自动驾驶汽车的发展,在现实世界的场景中,自动驾驶汽车已经覆盖了数百万公里。处理技术和算法的发展目前似乎比传感硬件的发展速度更快,以从车辆周围环境(如障碍物、交通、标记和标志)中获取必要信息。正在集中开发汽车图像传感器,以应对对低成本、高动态范围、高灵敏度和抗闪烁光源(如LED交通标志和汽车尾灯)的伪影的相互矛盾的要求。在恶劣天气和/或光照条件下运行是汽车自动驾驶或自动驾驶辅助系统(ADAS)的主要要求,但是,与人类驾驶员在具有挑战性的情况下的表现相比,当前的ADAS传感器和系统仍然面临许多问题。由于事件摄像机已被提议作为可能的ADAS传感器(Posch et al., 2014),我们收集数据来研究使用事件摄像机来增强传统成像技术。
事件相机动态视觉传感器(DVS)不是提供基于帧的视频作为输出,而是检测单个像素亮度的局部变化,并在发生时异步输出这些变化(Lichtsteiner et al., 2008; Posch et al., 2014)。因此,与基于帧的系统相比,只有场景中发生变化的部分会产生数据,从而降低输出数据速率、提高时间分辨率并减少延迟,因为像素亮度的变化在发生时会从相机中流出。局部瞬时增益控制增加了不受控制的照明条件下的可用性。更高的时间分辨率和有限的数据速率使DVS非常适合自动驾驶应用,其中延迟和功耗都很重要。动态有源像素视觉传感器(DAVIS)具有同时输出DVS事件和标准图像传感器强度帧的像素(Brandli et al., 2014)。
最近的研究表明,在数据驱动的卷积神经网络(CNN)实时应用中使用DVS是有用的(Moeys et al., 2016; Lungu et al., 2017)。在这些应用中,DVS输入帧通常由恒定数量的几千个DVS事件组成的2D直方图图像组成。因为DVS事件率与亮度变化率成正比,即场景反射率(Lichtsteiner et al., 2008),所以CNN帧速率是可变的,范围从大约1 fps到1000 fps。Moeys et al. (2016)表明,将来自传感器的标准图像传感器帧与DVS帧相结合,可以提高准确度并缩短平均反应时间。在此,我们在第一个发布的DVS或DAVIS驾驶数据的端到端数据集中将这项工作扩展到现实世界的驾驶。
2 Davis Driving Dataset 2017 (DDD17)
DDD17可从sensors.ini.uzh.ch/databases获得。这些数据是从瑞士和德国在各种条件下的公路驾驶中收集的。它包括DAVIS数据和汽车数据。由于该数据集的主要目的是研究用于ADAS的APS和DVS数据的融合,因此我们没有包括其他传感器,例如LIDAR。
2.1 DAVIS data
视觉数据是使用包含DAVIS APS+DVS相机的DAVIS346B原型相机捕获的,这样可以通过相同的光学器件同时记录基于事件的和传统的基于帧的数据。相机分辨率为346 × 260像素。相机架构类似于Brandli et al. (2014),但传感器的像素增加了2.1倍,并包括片上列并行模数转换器(ADC),可实现高达50 fps的基于帧的APS输出。DAVIS346B还优化了带有微透镜的埋入式光电二极管,可增加填充因子并减少暗电流,从而与Brandli et al. (2014)的DAVIS240C相比,将低光强度下的操作提高了约4倍。所有记录均使用固定焦距镜头(C-mount, 6mm),提供56度的水平视野。光圈是手动设置的,具体取决于照明条件。APS帧速率取决于曝光持续时间,介于10 fps和50 fps之间;在某些录音中,它会根据自动曝光持续时间算法而有所不同。这些帧是使用DAVIS全局快门模式捕获的,以最大限度地减少运动伪影。相机安装在挡风玻璃后面的玻璃三脚架支架上,就在后视镜下方,并对准引擎盖的中心。汽车引擎盖上的标记最初用于在第一次录制期间对准摄像机,并且摄像机从未从该位置移动过。这些标记在整个记录期间都留在引擎盖上以进行控制。在一些录音中使用了偏振滤光片来减少挡风玻璃和引擎盖的眩光。相机由高速USB 2.0供电并连接到笔记本电脑。使用inilabs cAER软件1读取原始数据并流式传输到第2.3节中描述的自定义记录框架作进一步处理。
1 cAER支持
2.2 Vehicle control and diagnostic data
使用Ford Mondeo MK 3 European Model获取数据。我们使用插入乘客舱OBDII端口的OpenXC Ford Reference车辆接口,从汽车的CAN总线读取控制和诊断数据。车辆接口连接到主机USB端口2。
车辆接口使用Ford Mondeo MK 3车型("类型3"固件)的供应商提供的固件进行编程,并使用OpenXC python库读取。原始数据被传递到第2.3节中描述的自定义记录软件。以下每个量以约10 Hz的速率读出。端到端学习实验的可能目标以粗体显示。
- 方向盘转角(度,最高720度),
- 加速踏板位置(%踩下),
- 制动踏板状态(踩下/未踩下),
- 发动机转速(rpm),
- 车速(km/h),
- 纬度,
- 经度,
- 前照灯状态(开/关),
- 远光灯状态(开/关),
- 挡风玻璃雨刷状态(开/关),
- 里程表(km),
- 变速箱扭矩,
- 变速箱档位(档位号),
- 自重启以来消耗的燃料,
- 燃油油位(%),
- 点火状态,
- 驻车制动状态(开/关)。
2.3 Recording and viewing software
创建了一个用于记录、查看和导出数据的Python软件框架3,其主要目的是组合和同步来自不同输入设备的数据并将其存储为标准化文件格式。特别是,由于APS帧和DVS数据在相机上使用其自己的本地时钟进行了微秒时间戳,而车辆接口提供的数据不是,因此两个数据流都增加了记录计算机的毫秒系统时间,然后可以用于同步。由于车辆接口以每个记录变量仅约10 Hz的速率流式传输数据,因此这种设备外时间戳是合理的。在录制之前,计算机时间已与标准时间服务器同步。数据以HDF5格式存储,其中存在适用于各种环境的广泛使用的库。每种数据类型(例如 DVS 事件、方向盘角度、车速……)都存储在一个单独的容器中,每个容器包含一个用于系统时间戳的容器和一个用于数据的容器。这样,系统时间戳可以用于快速索引和读取时同步数据。由于记录设备以不规则的时间间隔提供数据,每种数据类型都以事件驱动的方式存储,因此不同的容器包含不同数量的样本。DAVIS数据以其原生cAER AER-DAT3.1格式4存储在每个HDF5容器中。
除了记录框架之外,基于python的查看器view.py将记录的DAVIS数据与选定的车辆数据(如转向角或速度)一起可视化(图1)。脚本export.py将数据导出到帧中,以准备数据以供机器学习算法进一步处理。
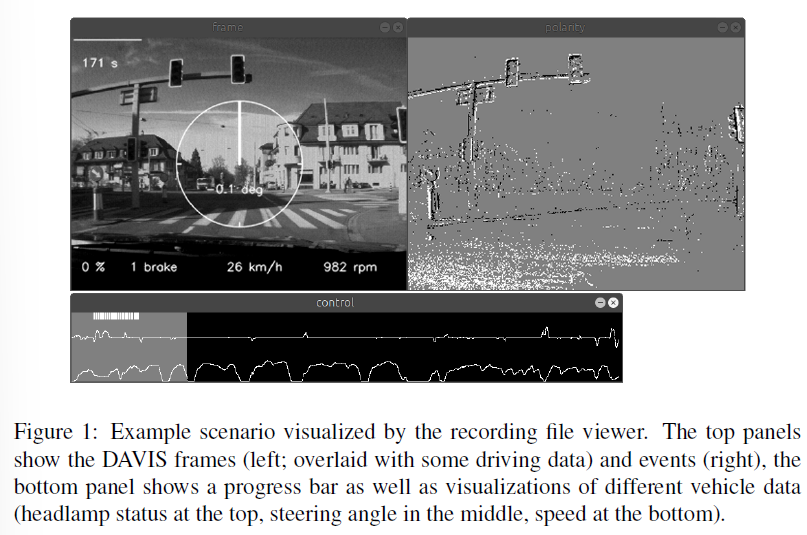
3 Recorded data
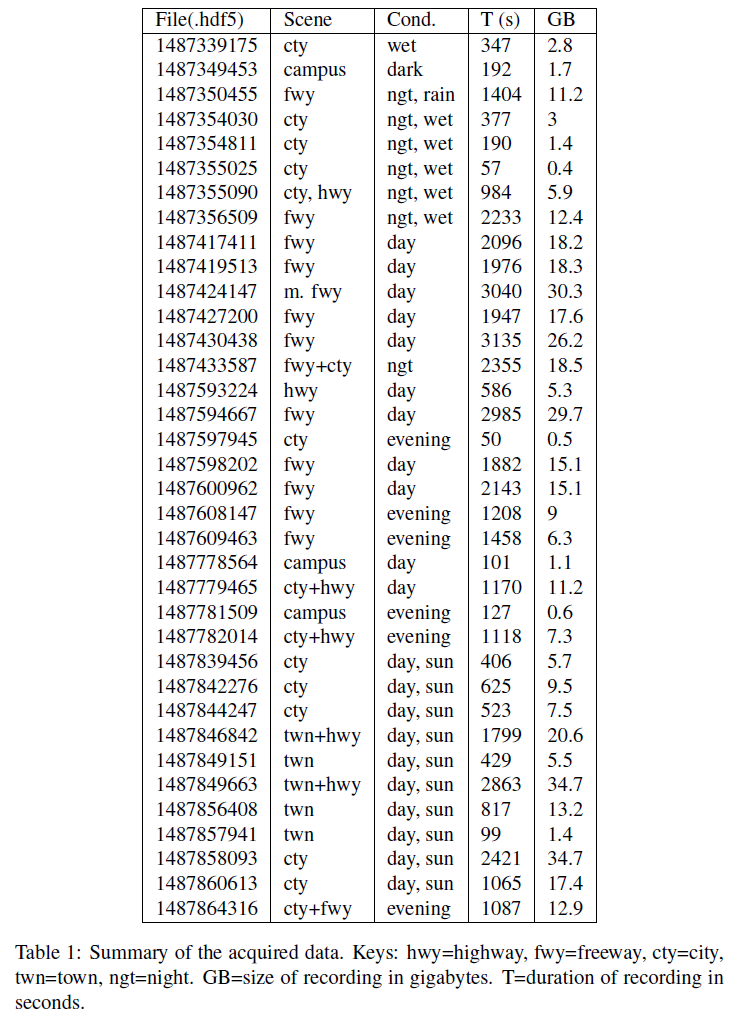
总共连续六天在各种天气、驾驶、道路和照明条件下记录了超过12小时的数据,覆盖了瑞士和德国超过1000公里的不同类型道路。记录是手动开始和停止的,通常持续一分钟到一小时。结果记录总结在表1中。图2显示了几个记录变量在整个数据集中的分布。转向角以直线行驶和10°的小偏差为主。速度在0-160 km/h范围内均匀分布。自动控制的前照灯大约有一半时间亮着,这表明大部分数据是在弱光条件下捕获的。

4 Experiments: Steering prediction network
控制模型的端到端学习对于自动驾驶应用来说是一种有吸引力的方法,因为它消除了对数据或特征进行繁琐的手工标记的需要——面对当今车辆获取的大量数据,这项任务令人望而却步(Bojarski et al., 2016)。所呈现的数据集有明显的局限性,因为它不包括其他传感器,如激光雷达,不包括可以更好地预测用户意图的路线信息,并且数据往往是不平衡的。然而,在某些条件下,例如高速公路驾驶、沿道路行驶而不转向其他道路或不可预测的用户行为,它可以用于研究数据在预测测量的用户行为方面的效用。
我们训练了简单的转向预测网络。这些网络获取输入的APS和/或DVS数据并尝试预测瞬时方向盘角度。他们的灵感来自LeCun的早期工作(LeCun et al., 2005)、comma.ai的开创性开放数据集(Santana & Hotz, 2016),以及最近的Nvidia (Bojarski et al., 2016)和未发表的VW研究。
我们的结果比较了在纯APS数据上运行的网络与在纯DVS数据上运行的网络的转向预测精度。我们的示例实现应被视为验证数据和相关软件可用性的初步研究。特别是,这里介绍的实验基于整个数据集的一小部分(表1中的记录1487858093和1487433587)。使用更多数据训练更多架构的工作正在进行中。
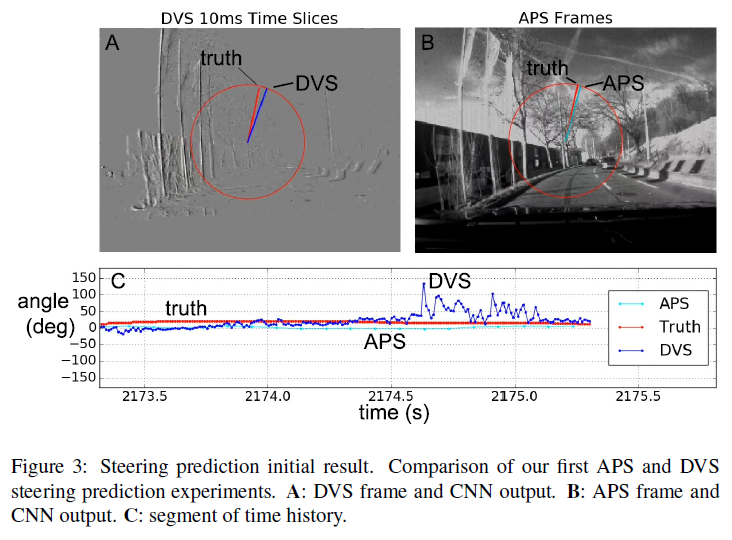
图3显示了我们的第一个结果,它是从具有4个卷积层的CNN获得的,每个卷积层有8个特征图并使用3×3核,并在单个1.5小时的记录上进行训练。每层后面都有一个2x2最大池化层。最终的特征图层被映射到一个64单元的全连接(FC)层。FC层映射到范围±180度中的输出转向角。DVS和APS输入被二次采样为80×60图像。输入帧归一化按照Moeys et al. (2016)的方法进行。
我们的定量准确性结果无法报告,但我们已经验证了数据集和工具的可用性。进一步的分析是必要的,并且是正在进行的工作的主题。
5 Conclusion
本文的主要成果是介绍了DDD17,第一个开放的DAVIS驾驶数据数据集,带有端到端的标签,以及必要的软件工具。CNN对端到端转向角预测的初步研究显示了数据的可用性。