郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

AAAI 2022
Abstract
在深度神经网络(DNN)的帮助下,深度强化学习(DRL)在从游戏到机器人控制等许多复杂任务上取得了巨大成功。与具有部分受大脑启发的结构和功能的DNN相比,脉冲神经网络(SNN)考虑了更多的生物学特征,包括具有复杂动力学的脉冲神经元和具有生物学合理的可塑性原则的学习范式。受生物大脑中细胞组装的高效计算的启发,基于记忆的编码比读出复杂得多,我们提出了一种多尺度动态编码改进的脉冲actor网络(MDC-SAN),用于强化学习以实现有效的决策。网络尺度的群体编码与神经元尺度的动态神经元编码(包含二阶神经元动力学)相结合,形成强大的时空状态表示。广泛的实验结果表明,我们的MDC-SAN在OpenAI gym的四个连续控制任务上的性能优于其对应的深度actor网络(基于DNN)。我们认为这是从有效编码到有效决策的角度改进SNN的重大尝试,就像在生物网络中一样。
Introduction
强化学习(RL)在机器学习的研究领域中处于越来越重要的地位(Kaelbling, Littman and Moore 1996),其中智能体以试错的方式与环境交互并通过最大化累积奖励学习最优策略以达到出色的决策性能(Sutton and Barto 2018)。然而,对于所有传统的RL算法来说,有效地从复杂状态空间中提取特征是一个普遍但具有挑战性的问题。以深度神经网络(DNNs)作为强大的函数近似器,深度强化学习(DRL)通过直接学习从原始状态空间到动作空间的映射在一定程度上解决了这个问题,并在包括推荐系统(Zou et al. 2019; Warlop, Lazaric, and Mary 2018)、游戏(Mnih et al. 2015; Vinyals et al. 2019)和机器人控制(Duan et al. 2016; Lillicrap et al. 2016)等在内的各种应用中得到了很好的应用。
然而,强大的DRL距离生物大脑中有效的基于奖励的学习还很遥远,在生物大脑中,具有更复杂动力学的脉冲神经元和具有生物学合理可塑性原则的学习范式被整合以产生复杂的认知功能。生物大脑通过细胞组装(Harris et al. 2003)使高效计算成为可能,它更多地关注记忆的时空编码,而不是决策的读出。与DNN相比,SNN由于其复杂的动力学特性,在模拟类脑拓扑和功能方面具有更大的潜力。例如,SNN可以与多尺度动态编码(包括网络和神经元尺度)无缝兼容,从而实现强大的时间信息表示。SNN固有地传输和计算随时间分布的动态脉冲信息(Maass 1997)。对它们的进一步研究可能会帮助我们打开大脑有效信息编码的黑匣子(Painkras et al. 2013)。因此,我们认为使用SNN的RL可能比使用DNN更好。
为此,我们提出了一种多尺度动态编码改进的脉冲actor网络(MDC-SAN)来模拟生物大脑中的细胞组装,其中包含一个用于状态表示的复杂脉冲编码模块和一个用于动作推断的简单读出模块。编码模块结合了群体编码和动态神经元(DN)编码,使其在网络和神经元尺度上的状态表征上更加有效。具体来说,对于给定的输入状态,我们使用可学习的感受野对单个神经元群体中的每个维度进行编码。然后编码的模拟信息作为输入直接传送到网络。在网络内部,我们提出了新的DN来改进SNN,从而在时空学习期间获得更好的信息表示。DN包含由关键动态参数支持的膜电位的二阶动态。这些参数首先从OpenAI gym (Brockman et al. 2016)任务(例如Ant-v3)中自学,然后扩展到其他类似任务(例如HalfCheetah-v3、Walker2dv3和Hopper-v3)。在动态编码之后,我们在预定义的时间窗口中对累积的脉冲进行平均以获得平均发放率,进一步用于通过简单的读出模块推断输出动作。
为了进行有效的学习,所提出的MDC-SAN使用双延迟深度确定性策略梯度(TD3)算法(Fujimoto, Hoof, and Meger 2018; Tang, Kumar, and Michmizos 2020)与深度critic网络一起训练。我们在四个标准OpenAI gym任务(Brockman et al. 2016)上评估训练后的MDC-SAN,包括Ant-v3、HalfCheetah-v3、Walker2d-v3和Hopper-v3。实验结果表明,多尺度动态编码,包括群体编码和DN的复杂时空编码,始终有利于MDC-SAN的性能。此外,在相同的实验配置下,所提出的MDC-SAN在上述四项任务上显著优于其对应的深度actor网络(DAN)。
本文的主要贡献可归纳如下:
- 我们提出了一个MDC-SAN来模拟生物大脑中的细胞组装以进行有效的决策,其中包含一个用于从网络规模和神经元规模表示状态的复杂编码模块,以及一个用于动作推断的简单读出模块。
- 对于网络规模,我们应用群体编码来增加网络的表示能力,它使用可学习的感受野对单个神经元群体中输入状态的每个维度进行编码。我们还验证了群体编码的优势,并全面比较了各种输入编码方法对性能的影响。
- 对于神经元尺度,我们构建了新的DN,其中包含用于复杂时空信息编码的二阶神经元动力学。我们还分析了DN的膜电位动力学,并展示了DN对标准LIF神经元的性能优势。
- 在相同的实验配置下,我们集成了群体编码和DN编码的MDCSAN在每项任务中都比对应的DAN取得了更好的性能。据我们所知,我们的工作是第一个使用SNN在多个连续控制任务上实现最先进性能的工作。
Related work
Integrating SNNs with RL 最近,围绕将SNN引入RL算法的文献越来越多(Florian 2007; O'Brien and Srinivasa 2013; Yuan et al. 2019; Doya 2000; Frémaux, Sprekeler, and Gerstner 2013)。这些方法通常基于奖励调节的局部可塑性规则,这些规则在简单的控制任务中表现良好,但由于优化能力有限,通常在复杂的机器人控制任务中失败。
为了解决这个限制,一些方法将SNN与DRL优化相结合。其中一种方法直接将深度Q网络(DQN)(Mnih et al. 2015)转换为SNN,并在具有离散动作空间的Atari游戏中获得有竞争力的分数(Patel et al. 2019; Tan, Patel, and Kozma 2021)。然而,这些转换后的SNN通常表现出不如具有相同结构的DNN的性能(Rathi et al. 2019)。另一种方法是基于混合学习框架。它在移动机器人的无地图导航任务中取得了成功,其中使用DRL算法结合深度critic网络对SAN进行训练(Tang, Kumar, and Michmizos 2020)。我们还希望在训练期间突出这种混合观点,并通过在SNN的有效信息表示中发挥重要作用的多尺度动态编码进一步扩展它。
Information coding methods in SNNs SNN中的输入编码方案有两类,发放率编码和时序编码。发放率编码使用时间窗口中脉冲序列的发放率来编码信息,其中输入实数被转换为频率与输入值成比例的脉冲序列(Cheng et al. 2020a)。时序编码使用各个脉冲的相对时间对信息进行编码,其中输入值通常被转换为具有精确时间的脉冲序列(Comsa et al. 2020; Sboev et al. 2018)。除此之外,群体编码在整合这两种类型方面是特殊的。例如,群体中的每个神经元都可以生成具有精确时间的脉冲序列,并且还包含与其他神经元的关系(例如,高斯感受野),以便在全局范围内更好地编码信息(Georgopoulos, Schwartz, and Kettner 1986)。
对于SNN中的神经元编码方案,有多种类型的脉冲神经元(Tuckwell 1988)。IF神经元是最简单的神经元类型。它在膜电位超过发放阈值时发放,然后将电位重置为预定义的静息膜电位(Rathi and Roy 2020)。另一个LIF神经元通过引入渗漏因子允许膜电位随着时间的推移而不断缩小(Gerstner and Kistler 2002)。它们通常用作标准的一阶神经元。此外,具有二阶膜电位方程的Izhikevich神经元被提出,它可以更好地表示复杂的神经元动力学,但需要一些预定义的超参数(Izhikevich 2003)。
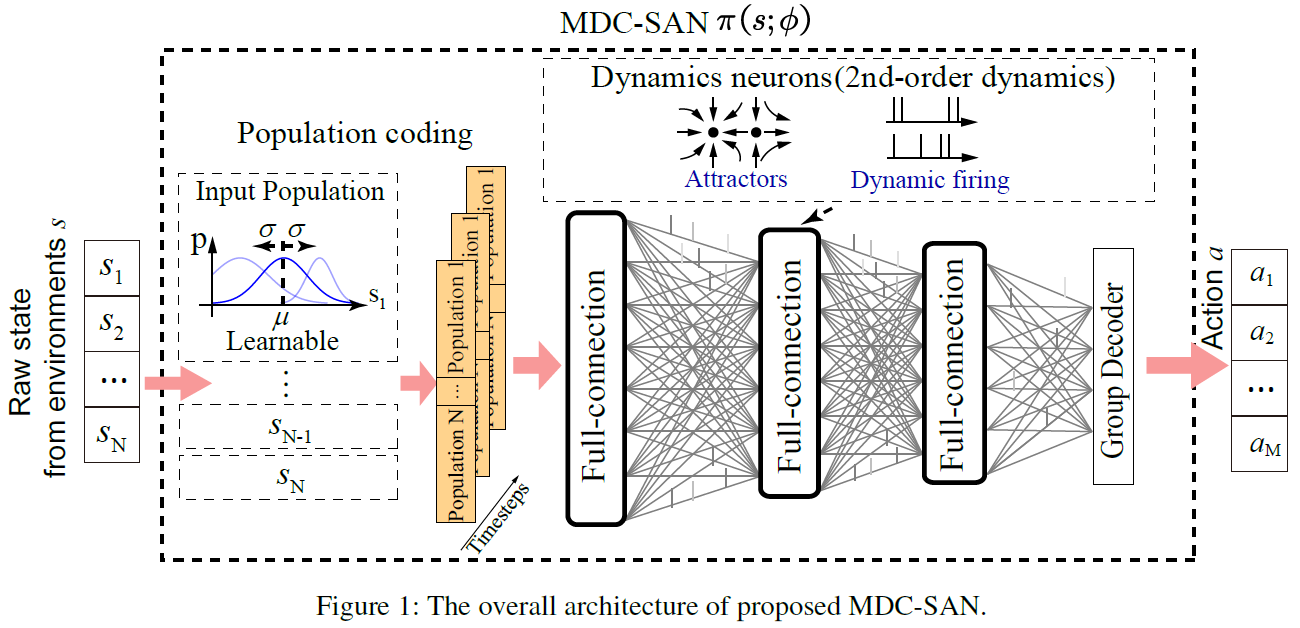
Methods
我们的MDC-SAN的概述如图1所示,其中包含一个用于时空状态表示的有效编码模块和一个用于动作推断的相对简单的读出模块。MDC-SAN通过结合网络规模的群体编码和神经元规模的动态神经元编码来模拟生物大脑中的细胞组装。对于群体编码,输入状态的每个维度首先用一组动态感受野编码,然后输入到SAN。对于动态神经元编码,SAN内部的DN包含具有多达两个稳定点的二阶动态膜电位,以描述复杂的神经元动力学。最后,使用额外的组解码器将预定义时间窗口中累积脉冲的平均发放率解码为输出动作。
Population coding
对于一个输入状态s ∈ RN,它被编码为每个时间步骤的一个输入It, t = {1, 2, ... , T1},其中T1是SNN的时间窗口。
Pure population coding Cpop 我们创建了一组神经元Pi来编码状态si的每个维度,其中每个神经元Pi,j在群体中都有一个高斯感受野(μi,j, σi,j),具有两个可学习的均值和标准差参数。群体编码Cpop的公式为:
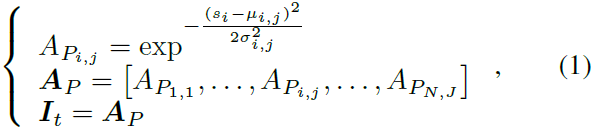
其中 i 是输入状态的索引(i = 1, ... , N), j 是群体中神经元的索引(j = 1, ... , J), AP是群体编码后的刺激强度,直接作为网络输入It使用。
还有其他候选输入编码方法结合了群体编码和发放率编码(包括均匀编码、泊松编码和确定性编码)。它们包含两个阶段(Tang et al. 2020):首先将状态 s 通过群体编码转换为刺激强度AP,然后使用计算的AP通过发放率编码生成输入It。我们将这些方法形式化如下。
The population and uniform coding (Cpop+Cuni) 我们生成从0到1均匀分布的随机数Randk(t),其大小与每个时间步骤的输入刺激强度AP的大小相同。然后我们将每个生成的随机数与其对应的输入数据进行比较。如果生成的随机数小于其输入数据,则将Ik,t设置为1。否则,将其设置为0,公式为:
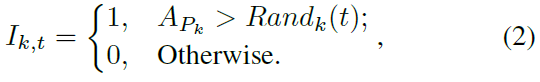
其中 k 是输入刺激强度的序数(k = 1, ... , N×J)。
The population and Poisson coding (Cpop+Cpoi) 考虑到泊松过程可以被认为是伯努利过程的极限,输入刺激强度AP包含概率可用于绘制二值随机数。Ik,t将根据AP中给出的第 k 个概率值![]() 得出一个值1,其公式为:
得出一个值1,其公式为:
![]()
The population and deterministic coding (Cpop+Cdet) 输入刺激强度AP作为突触后神经元的突触前输入(Tang et al. 2020),其公式如下:

其中,当Ik,t = 1时,Vk,t重置为Vk,t - 1,Vk,t为伪膜电压。
Dynamic Neurons
本节介绍最多具有一个稳定点的传统一阶神经元(例如LIF神经元),然后定义具有最多两个稳定点的改进二阶DN。以下部分还介绍了构建DN的过程。
The traditional 1st-order neurons SNN中传统的一阶神经元是LIF神经元,它是Hodgkin-Huxley模型的最简单抽象。为了展示LIF神经元的基本稳定点特征,这里我们对LIF神经元进行一个简单的定义,描述如下:

其中Vi,t是神经元 i 在时间 t 的动态膜电位,![]() 是输入,表示为整合的突触后电位。单个稳定点可以计算为
是输入,表示为整合的突触后电位。单个稳定点可以计算为![]() ,输入
,输入![]() 在 τ 的期间内。
在 τ 的期间内。
稳定点的数量将是区分不同神经元动力学水平的关键。例如,LIF模型的Vi,t的动态场正在达到单个吸引子![]() 。当发放阈值大于
。当发放阈值大于![]() 时,神经元将大部分泄漏(图2(a)),否则它将连续发放(图2(b))。
时,神经元将大部分泄漏(图2(a)),否则它将连续发放(图2(b))。
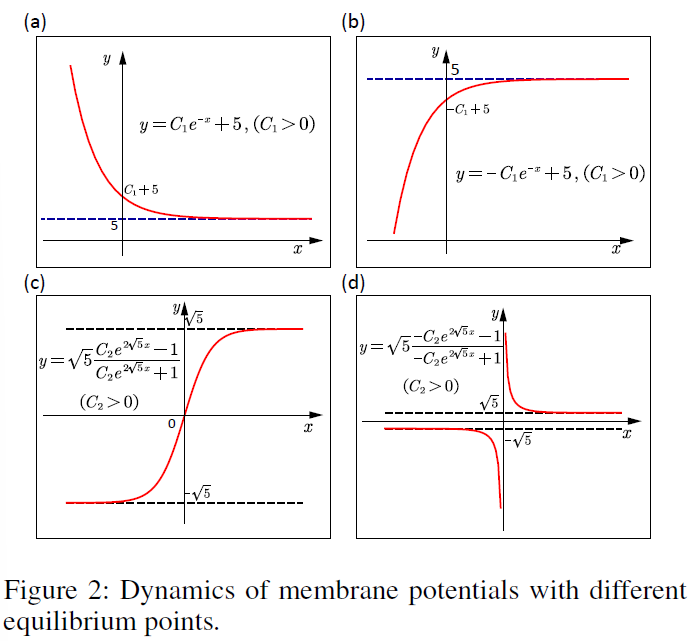
The designed 2nd-order DNs 具有高阶动力学的神经元意味着这些神经元的稳定点数量将不止一个。为简单起见,这里我们将其设置为2。二阶神经元动力学如下所示:
![]()
其中![]() 和Vj,t是不同动态程度的膜电位,Uj,t是模拟超极化的电阻项。当我们将常微分方程设置为0时,动态膜电位Vj,t在某些点会被吸引或不稳定。图2(c)和图2(d)显示了描绘膜电位动态场的图表,其中N = 2,达到稳定点的周期大约需要时间τ。为简单起见,我们将传统的mV或ms单位表示为1。除了膜电位外,还使用了其他一些隐式变量来描述二阶动力学,如下所示:
和Vj,t是不同动态程度的膜电位,Uj,t是模拟超极化的电阻项。当我们将常微分方程设置为0时,动态膜电位Vj,t在某些点会被吸引或不稳定。图2(c)和图2(d)显示了描绘膜电位动态场的图表,其中N = 2,达到稳定点的周期大约需要时间τ。为简单起见,我们将传统的mV或ms单位表示为1。除了膜电位外,还使用了其他一些隐式变量来描述二阶动力学,如下所示:
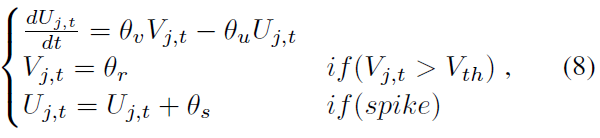
其中Vj,t的稳定点由Uj,t和输入电流![]() 共同决定。稳定点的数量和值将受到θv (V的电导率)、θu (U 的电导率)、θr (重置膜电位)和θs (U的脉冲改进)四个参数的动态影响,这与Izhikevich神经元(Izhikevich 2003)不同,它只关注高阶动力学。
共同决定。稳定点的数量和值将受到θv (V的电导率)、θu (U 的电导率)、θr (重置膜电位)和θs (U的脉冲改进)四个参数的动态影响,这与Izhikevich神经元(Izhikevich 2003)不同,它只关注高阶动力学。
The procedure for constructing the DNs DN的构建主要是基于识别其中的一些关键参数。以θv,u,r,s为例,这四个动态参数中的每一组都描述了一个脉冲神经元的动态状态。因此,我们想要获得一组最优的动态参数。
我们随机初始化网络中每个神经元的动态参数(θv,u,r,s)。连同突触权重,这些动态参数将使用TD3算法针对其中一项任务进行调整。学习后,大部分可学习变量都达到稳定点,这些参数将被绘制并用k-means方法聚类,以获得θv,u,r,s参数的最佳中心。最佳中心对应的四个关键参数将进一步作为所有任务的所有动态神经元的固定配置。
The simple readout module
输出层的脉冲在预定义的时间窗口中进行汇总,以首先计算平均发放率。然后,输出动作 a 作为组解码器计算的平均发放率的加权和返回。更多细节可以在MDC-SAN的前向传播(算法1)中找到。

The learning of MDC-SAN with TD3
MDC-SAN使用TD3算法(Fujimoto, Hoof, and Meger 2018; Tang, Kumar, and Michmizos 2020)与深度critic网络(即多层全连接网络)一起训练。在训练期间,MDC-SAN从给定状态 s 中推断出一个动作 a 来表示该策略,并且一个深度critic网络估计相关的动作价值Q(s, a)以指导MDC-SAN学习更好的策略。我们在一组连续控制基准上评估训练有素的MDC-SAN,并在相同设置下将其性能与其对应的DAN(即多层全连接网络)进行比较。TD3算法的具体训练过程可以在(Fujimoto, Hoof, and Meger 2018)中找到。
Tuning MDC-SAN with approximate BP
在多尺度的网络中很好地调整参数是一项挑战,例如,不同层的突触权重、群体编码器和组解码器中的参数。已经提出了许多用于调整多层SNN的候选方法,包括近似BP (Cheng et al. 2020b; Zenke and Ganguli 2018)、稳定点平衡(Shi, Zhang, and Zeng 2020; Zhang, Tielin and Zeng, Yi and Shi, Mengting and Zhao, Dongcheng 2018),Hopfield-like调整(Zhang et al. 2016)和生物学合理的可塑性规则(Zeng, Zhang, and Xu 2017)。
在此,我们选择近似BP是因为它的效率和灵活性。近似BP的关键特征是将BP期间脉冲神经元的非微分部分替换为预定义的梯度数,如公式(9)所示,其中我们使用矩形函数公式来近似脉冲的梯度。

其中 z 是伪梯度,V是膜电压,Vth是发放阈值,w是通过梯度的阈值窗口。
Experiments
为了评估我们的模型,我们测量了它在OpenAI gym的四个连续控制任务上的性能(图3)(Brockman et al. 2016)。

Implement details
由于最近对复现性的担忧(Henderson et al. 2018),我们所有的实验都报告了超过10个网络初始化和gym模拟器的随机种子。每个任务运行100万步,每10k步评估一次,每个评估报告10个回合的平均奖励,没有探索噪声,每个回合最多持续1000个执行步骤。
我们将我们的MDC-SAN与DAN和Pop-DAN(与DAN集成的群体编码;为了公平比较,它具有与MDC-SAN相同数量的参数)进行了比较。DAN、Pop-DAN和我们的MDC-SAN都使用TD3算法(Fujimoto, Hoof, and Meger 2018)与相同结构的深度critic网络一起训练。我们在相同设置下在四个连续控制任务(图3)上评估了训练有素的DAN、Pop-DAN和MDC-SAN,并比较了它们的性能(获得的奖励)。除非明确说明,否则Pop-DAN和MDC-SAN使用与DAN相同的超参数。这些模型的超参数配置如下:
Integrate DAN with TD3 actor网络是(256, relu, 256, relu, action dim M, tanh);critic网络是(256, relu, 256, relu, 1, linear);actor学习率为10-3;critic学习率为10-3;奖励折扣系数为γ = 0.99;软目标更新因子为η = 0.005;回放缓冲区的最大长度为T = 106;高斯探索噪声为![]() ;噪声裁剪为c = 0.5;小批量大小为n = 100;策略延迟因子为d = 2;
;噪声裁剪为c = 0.5;小批量大小为n = 100;策略延迟因子为d = 2;
Integrate Pop-DAN with TD3 actor网络时(Population Encoder, 256, relu, 256, relu, Group Decoder, action dim M, tanh);单一状态维度的输入群体规模为J = 10;输入编码使用群体编码(所有任务的Cpop);
Integrate MDC-SAN with TD3 使用了MDC-SAN (Population Encoder, 256, DNs, 256, DNs, Group Decoder, action dim M, tanh),其中DNs的当前衰减因子和发放阈值均为0.5;单一状态维度的输入群体规模为J = 10;MDC-SAN学习率为10-4;输入编码使用群体编码(所有任务的Cpop)。
Pre-learning of the dynamic parameters in DNs
我们选择Ant-v3作为基本源任务来预学习MDC-SAN内部DN的动态参数。所有MDC-SAN参数,包括突触权重和动态参数,都使用近似BP进行了调整。在大约100万个训练步骤后,学习曲线(未显示)不断增加并收敛。
学习后,对所有与DN相关的动态参数进行聚类,通过选择聚类中心来确保参数配置最优。如图所示。在图6(a, b)中,我们获得了参数θv,u,r,s(红色星星)的聚类中心。在此,为了简单起见,我们在k-means中设置k = 1。DN的最佳动态参数为![]() (膜电位电导率),
(膜电位电导率),![]() (隐藏状态U的电导率),
(隐藏状态U的电导率),![]() (重置膜电位),
(重置膜电位),![]() (对U的脉冲效应)。这些参数被表示为θ*并进一步用作以下实验中所有任务的所有动态神经元的固定配置。
(对U的脉冲效应)。这些参数被表示为θ*并进一步用作以下实验中所有任务的所有动态神经元的固定配置。



Benchmarking MDC-SAN against DAN
我们将MDC-SAN的性能与DAN和Pop-DAN进行了比较。如图4和表1所示,我们的模型在所有四个任务中都取得了最佳性能,显示了我们提出的MDC-SAN对于连续控制任务的有效性。此外,Pop-DAN在四个任务上都没有明显优于DAN。图5中的进一步分析表明,与没有群体编码的SAN相比,采用群体编码的SAN实现了显著的性能改进。SAN似乎比DAN更兼容群体编码。
Further discussion of different input codings
我们全面比较了各种输入编码方法对性能的影响,同时保持神经元编码方法固定为DN。如图5所示,单独的发放率编码方法(Cpoi,直接用泊松编码对输入状态进行编码)在所有四个任务上的性能远不如基于群体编码的方法(Cpop + Cuni、Cpop + Cpoi、Cpop + Cdet和Cpop)。这可能是因为发放率编码方法对单个神经元的表示能力具有固有的限制。并且群体编码可以更好地以更高维度的方式分离不同的状态,以产生更好的输入表示。对于基于群体编码的方法,Cpop在所有任务上都取得了最好的性能。其他三种基于群体编码的方法在性能上差别不大。因此,直接使用群体编码后状态的模拟值作为网络输入似乎更有效,而无需进一步使用发放率编码将模拟值编码为脉冲序列。

The neuronal analysis in MDC-SAN
我们在所有四个任务上进一步测试了构建的DN,并将它们与LIF神经元进行了比较,同时将输入编码方法固定为纯群体编码(Cpop)。如图7所示,在所有测试任务中,DN的性能都优于LIF神经元,包括源任务(学习DN的动态参数,即Ant-v3)和其他类似任务(即HalfCheetah-v3、Walker2d-v3和Hopper-v3)。该结果验证了DN的泛化能力,即从任务中学习到的DN的动态参数可以推广到其他类似的任务。
LIF神经元和DN之间性能差异的一个可能原因是DN包含更高阶的膜电位动力学、更复杂的电导率配置(θv和θu)和复位电位(θr)。因此,使用DN的模型在时空信息处理中表现出更高的复杂性,这可能有助于提高性能。给出了这两种类型神经元的额外模拟,如图8所示,包括不同显式(例如,膜电位 V 和受激输入 I)和隐式变量(例如,阻力项 U)的神经元动力学。
对于图8(a)中的标准LIF神经元,膜电位与神经元输入成正比。例如,对于值范围从-1到1的sin-like输入,动态积分V被动态积分,直到仅在强正刺激下达到发放阈值Vth,否则随着弱正或负刺激相应地衰减。与LIF神经元不同,DN显示出更高的复杂性,并带有额外的隐式U,使得稳定点的动态变化不同。根据DN的定义,U的微小差异会导致V的显著更新,尤其是当公式(8)中的参数u较小时。因此,DN会在强正刺激下表现出相似的发放模式,而在弱正或负刺激下表现出稀疏的发放,而不是像LIF神经元那样停止发放。该结果显示DN的动态表示比LIF神经元更好。

Conclusion
多尺度的高效编码对于生物神经网络的下一步决策至关重要。本文将输入层的空间群体编码和隐藏层的时间DN编码结合为一个集成的脉冲actor网络(MDC-SAN),在四个基准Open-AI gym任务上取得了比其对应的DAN更好的性能。与SAN中通常使用的LIF神经元不同,更复杂的DN在时间非线性信息处理方面表现出更重要的能力并获得更高的性能。此外,群体编码在空间信息编码方面也表现出优势。
未来,可以从生物网络中借鉴更多生物学合理的原则,并将其应用于SAN,以实现更低的能源成本、更重要的适应性和更高的鲁棒性计算。神经科学和人工智能之间的这些相互作用对未来有很大的意义。