郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

(2022)
Abstract
脉冲神经网络(SNN)以基于事件的方式进行计算,以实现比标准神经网络更高效的计算。在SNN中,神经元输出(即激活)不是用实值激活编码的,而是用二值脉冲序列编码的。在传统神经网络上使用SNN的动机源于基于脉冲的处理的特殊计算方面,尤其是神经输出激活的高度稀疏性。传统卷积神经网络(CNN)的成熟架构具有处理元素(PE)的大型空间阵列,在激活稀疏性的情况下,这些空间阵列仍然高度未充分利用。我们提出了一种新颖的架构,该架构针对具有高度激活稀疏性的卷积SNN(CSNN)的处理进行了优化。在我们的架构中,主要策略是使用较少但使用率较高的PE。用于执行卷积的PE阵列仅与核大小一样大,只要有要处理的脉冲,就允许所有PE处于活动状态。通过将特征图(即激活)压缩到队列中,可以确保这种持续的脉冲流,然后可以逐个脉冲地处理这些队列。这种压缩是在运行时使用专用电路执行的,从而实现自定时调度。这允许处理时间直接与脉冲的数量成比例。一种称为内存交错的新型内存组织方案用于使用多个小型并行片上RAM有效地存储和检索单个神经元的膜电位。每个RAM都硬连线到其PE,从而减少了开关电路并允许RAM靠近相应的PE。我们在FPGA上实现了所提出的架构,与其他实现相比实现了显著的加速,同时需要更少的硬件资源并保持较低的能耗。
Index Terms—Spiking Convolutional Neural Networks (SNN), Hardware Acceleration, Event-Based Processing, Field-Programmable Gate Array (FPGA).
I. INTRODUCTION
人工神经网络(ANN)已成为许多机器学习问题的首选解决方案[1][2]。一般来说,当有大量训练数据可用时,ANN开始优于传统的机器学习方法[2]。然而,这种性能是以巨大的计算成本为代价的。例如,人工神经网络模型ResNet-50需要总共3.9 · 109次操作来处理单个224ⅹ224图像[3]。一般来说,可以观察到一种趋势,即随着分类精度的提高和手头的任务变得更加复杂,ANN的大小会增加[3]。这在内存、内存带宽和处理能力方面给底层计算资源带来了沉重的负担。为了满足诸如功率、吞吐量和延迟等非功能性要求,需要对底层算法和相应的处理硬件进行仔细的协同设计[4][5]。寻找更高效的处理系统,灵感可能来自人类已知的最高效的认知系统:人脑。一个新兴趋势是实现专用硬件来处理受生物启发的脉冲神经网络(SNN)[6]-[12]。SNN一词指的是一大组共享一个属性的模型:神经元的输出(激活)不像标准NN那样用实值标量编码,而是用称为脉冲的二值事件序列编码。从计算的角度来看,SNN的有趣之处在于其固有的事件驱动处理:仅当脉冲(即事件)发生时才需要执行计算[13][14]。与标准神经网络相比,要真正获得性能优势,三个方面至关重要:
- 神经代码决定了如何用二值脉冲对信息进行编码。编码窗口的长度和编码神经元激活所需的脉冲数量是SNN推理速度和效率的最重要决定因素[15][16]。一般来说,脉冲稀疏度越高越好。
- 一般来说,神经元输出激活的高度稀疏性需要在推理过程中执行的计算更少。虽然脉冲稀疏性是一个很好的理论属性,但由于与之相关的不规则数据流[17],使用标准计算机架构实际上很难利用它。
- 脉冲神经元的输出不仅取决于其输入,还取决于其称为膜电位的内部状态。实际值的膜电位需要被存储,因此增加了开始时已经非常高的内存需求。必须部署策略来多路复用膜电位内存,以减少整体内存占用。
为了在计算机视觉任务上实现最先进的分类性能,来自标准NN的既定方法必须适应SNN。这些方法主要是:卷积层和池化层。为了使用专用硬件加速这种卷积脉冲神经网络(CSNN),大多数作者提出了处理元件(PE)的大型空间阵列[9][18][19]。空间架构以这样的方式耦合PE,以便它们可以交换中间结果而无需访问中央存储器[5]。典型的实现使用单个PE(脉动阵列)[10]或具有高度灵活的基于数据包的互连[9][11]的Network-on-Chips (NoCs)之间的固定数据路径连接。脉动阵列非常适合在数据流易于预测的情况下执行卷积,即在低稀疏度的情况下[20]。NoC更擅长处理不可预测的数据流,因为它们允许平衡不同PE上的工作负载。这是以用于实现路由器和控制电路的更昂贵的NoC通信基础设施为代价的。这种空间架构的主要缺点是,如果必须处理高度稀疏的激活,大多数PE都处于空闲状态。然而,由于泄漏和时钟切换(后者仅适用于同步实现),空闲PE仍会消耗功率。此外,空闲的PE对最终结果没有贡献,因此浪费了芯片面积。由于无法先验地预测激活稀疏性和相关的不规则数据流这一事实[4][21],这一点变得复杂。因此,将神经操作映射到PE的重要任务必须在运行时执行。本文的主要贡献如下:
- 一种非空间硬件架构,使用高效的神经代码针对基于稀疏事件的脉冲处理进行了优化。
- 一种序列处理方案,允许多路复用用于存储膜电位的内存,从而保持低内存占用。
- 引入了一种称为内存交错的新型内存映射方案,该方案允许片上RAM的高度并行、细粒度和高带宽分布。
- 基于队列的自定时处理可以最大程度地利用PE,因为跳过零激活是架构数据流所固有的。这允许执行时间直接与脉冲的数量成比例。其核心思想是使用较少的PE,但最大限度地提高其利用率。
II. BACKGROUND ON SPIKING NEURAL NETWORKS
由于生物合理性和模型复杂性之间的权衡,出现了各种各样的SNN模型。在这项工作中,我们使用IF模型[22]。IF模型具有真实神经元最少的神经计算特征,但在实现上非常有效[22]。最近的进展已经表明SNS部署简单的IF模型的分类性能与最先进的非脉冲NNS实现相一致[23][24]。例如,Sengupta等人报告,在标准NN上使用SNN时,CIFAR-10数据集的误差增量仅为0.15%,而在困难的ImageNet数据集上的误差增量为0.38%[23]。
A. The Integrate-and-Fire model
B. Information Encoding with Binary Spikes
C. Convolutional SNNs
III. RELATED WORK
IV. SPIKING NEURAL NETWORK DESIGN
V. HARDWARE DESIGN
A. Top-level overview
B. Performing convolution with address events
C. Thresholding Unit
D. Scheduling strategy
VI. IMPLEMENTATION
本节展示了如何将上一章中描述的顶级架构映射到实际硬件。顶层架构提出了一个需要解决的基本挑战:膜电位Vm存储在单个存储器(MemPot)中。然而,要执行卷积或阈值处理,需要并行访问3ⅹ3个膜电位。双端口RAM(例如大多数FPGA芯片上的BRAM)通常每个时钟周期仅支持一次写入和一次读取访问,从而无法进行9次并行读/写操作。为了解决这个问题,这里提出了一种称为内存交错的新内存分配策略。内存交错的想法是将MemPot的所有元素分布在9个称为列的不同RAM上,这样就可以进行9个并发读/写操作。膜电位的元素需要以某种方式放入9个记忆列中:无论3ⅹ3窗口放置在哪个位置(i, j),所有9个元素必须分别来自一个记忆列。图6进一步解释了这种内存交错方案。每个元素由其地址(i, j)及其列s ∈ (0, ... , 8)唯一寻址。对于更紧凑的符号,(i, j)[s]用于定义神经元的唯一地址。内存交错方案具有多个积极效果:
- Vm被分配到9个较小的RAM,而不是一个大型单片存储器。较小的RAM往往更快、更节能。
- 多个小型RAM可以分布在更靠近PE的地方,这进一步提高了速度和能源效率。
- 交错处理有效地防止了数据危害。
下面,我们将详细讨论不同模块的硬件实现。
A. Address Event Queue (AEQ)
B. Convolution Unit
C. Thresholding Unit
VII. EXPERIMENTS AND EVALUATION
为了评估所提出架构的有效性,我们首先在MNIST2和更难的Fashion-MNIST3数据集上训练了一个小型CSNN。训练是使用Tensorflow Keras4的传统CNN和截断的ReLU激活函数(如Rueckauer et al. [14]所述)进行的。为了准备在硬件中部署,然后使用量化感知训练对CNN进行了重新训练[38]。然后使用Rueckauer et al. [14][24]提出的SNN-Toolbox5转换CNN的权重并量化为8位和16位。CSNN的结构为(28ⅹ28-32C3-32C3-P3-10C3-F10)。符号如下。卷积层:<#channels>C<kernel size>,最大池化层:P<window size>,全连接层:F<#neurons>。实验发现,在T = 5个时间步骤上模拟这种m-TTFS编码的CSNN会产生最佳的分类精度。输入帧由整数像素组成,在处理之前需要对其进行二值化以获得输入脉冲,然后将其馈送到CSNN。可以通过对各个帧进行阈值化来实现二值化。对于像MNIST这样背景与对象明显分离的简单数据集,仅应用一个阈值就足够了。然而,这不可避免地会导致信息丢失,因此我们建议通过应用一组阈值P = (p1, p2, ... , pT-1)将输入帧转换为二值脉冲。P的一个重要性质是它是一个严格递增的集合来模拟m-TTFS编码。
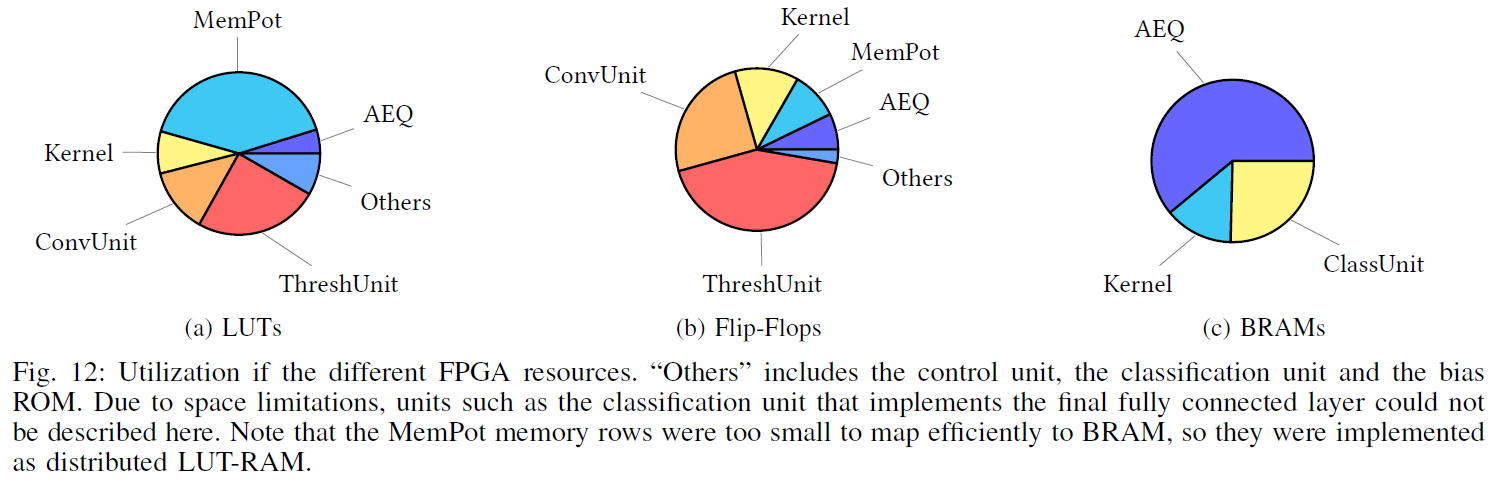
为Xilinx Zynq UltraScale + XCZU7EV FPGA综合了所提出的架构。使用Vivado Power Estimator工具执行功耗估计。加速器的一般架构非常紧凑,因此可以通过并行实现多个单元来改善并行度和延迟。我们使用多个并行化程度测试了我们的实现,参考了AEQ、MemPot存储器、Kernel和Bias ROM、阈值单元和卷积单元的数量。我们发现对于这个CSNN,8倍的并行化产生了最好的能效(见表I)。表II提供了详细的综合和利用结果(在LUT、触发器(FF)、块RAM (BRAM)和专用DSP方面),并将它们与相关工作进行了比较。为了评估所提出方法的有效性,我们将每一层的输入激活稀疏度与表III中的PE利用率进行了比较。稀疏性是指与所有激活相关的非零激活的数量。PE利用率测量PE接收有效地址事件的时钟周期相对于处理CSNN所需的所有时钟周期。请注意,PE利用率没有考虑到可能有零权重不会导致并更新到MemPot。表V显示了此处提出的架构的性能统计数据,并将它们与其他CSNN MNIST实现进行了比较。表IV将Fashion-MNIST数据集的准确性与相关工作进行了比较。应谨慎进行直接定量比较,因为不同的方法在实验中不使用相同的SCNN架构。尽管如此,SCNN的大小足够可比(都包含三到四个可训练层),可以进行有意义的定性比较。图12概述了各个单元如何消耗硬件资源。
2http://yann.lecun.com/exdb/mnist/
3https://github.com/zalandoresearch/fashion-mnist
4https://keras.io/about/
5https://snntoolbox.readthedocs.io/en/latest/

VIII. CONCLUSIONS
在这项工作中开发的SNN硬件实现策略允许对卷积SNN进行低延迟和节能处理。由于最大池化和神经元偏差的硬件实现,它支持最先进的SNN架构。这允许部署的SNN实现具有竞争力的分类精度。
为了降低膜电位的记忆成本,引入了一种神经元复用方案。在这个方案中,只模拟了SNN的一小部分,并且只存储了这个部分模拟的稀疏输出脉冲。为了实现高性能,引入了一种称为内存交错的新型内存分配方案。内存交错允许靠近PE的内存单元的高度并行细粒度分布。为了利用高度的稀疏性,脉冲事件被压缩到队列中。因此,处理时间随着出现的脉冲数量而变化。基于队列的处理可确保尽可能多地利用PE,即使仍有进一步提高PE利用率的空间。我们发现在我们的CSNN中,卷积层中有多个通道从未产生过脉冲。因此,修剪这种"死"层可能会导致进一步的改进。PE被高度流水线化以实现高时钟频率并提高并行度。相比之下,基于HLS的方法,如Fang et al. [8]的方法或S2N2 [39],我们的方法与CSNN的架构无关,因此也可以在ASIC上实现。由于单个卷积单元的硬件利用率非常小,因此可以并行实现多个卷积单元,从而可以轻松扩展吞吐量。在这项工作中开发的原型显示出非常有前途的性能,但是,这里使用的目标SNN相对较小,是为相对简单的基准数据集开发的。在未来,我们计划实现更大的SNN,并将我们的结果与非脉冲实现进行比较。