郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

CoRR, (2016)
Abstract
我们介绍了BinaryNet,一种在计算参数梯度时使用二值权重和激活来训练DNN的方法。我们表明,可以在MNIST上训练多层感知器(MLP),在CIFAR-10和SVHN上使用BinaryNet训练ConvNet,并获得几乎最先进的结果。在运行时,BinaryNet大大减少了内存使用,并用1位异或(XNOR)运算代替了大多数乘法运算,这可能对通用和专用深度学习硬件产生重大影响。我们编写了一个二值矩阵乘法GPU内核,使用它运行我们的MNIST MLP比使用未优化的GPU内核快7倍,而不会损失分类精度。BinaryNet的代码可用。
Introduction
深度神经网络(DNN)在广泛的任务中极大地推动了人工智能(AI)的极限,包括但不限于从图像中识别物体(Krizhevsky et al., 2012; Szegedy et al., 2014)、语音识别(Hinton et al., 2012; Sainath et al., 2013),统计机器翻译(Devlin et al., 2014; Sutskever et al., 2014; Bahdanau et al., 2015),Atari和围棋游戏(Mnih et al., 2015; Silver et al., 2016),甚至是抽象艺术(Mordvintsev et al., 2015)。
如今,DNN几乎只在一个或多个非常快速且耗电的图形处理单元(GPU)上进行训练(Coates et al., 2013)。因此,在目标低功耗设备上运行DNN通常是一项挑战,并且已经进行了大量研究工作以在运行时加速DNN在这两种通用设备(Vanhoucke et al., 2011; Gong et al., 2014; Romero et al., 2014; Han et al., 2015)和专用计算机硬件(Farabet et al., 2011a;b; Pham et al., 2012; Chen et al., 2014a;b; Esser et sl., 2015)上的运行速度。
我们认为我们的文章的贡献如下:
- 我们介绍了BinaryNet,这是一种在计算参数梯度时使用二值权重和激活来训练DNN的方法(参见第1节)。
- 我们展示了使用BinaryNet在MNIST上训练多层感知器(MLP)和在CIFAR-10和SVHN上训练ConvNet是可能的,并获得几乎最先进的结果(见第2节)。
- 我们表明,在运行时,BinaryNet极大地减少了内存使用,并用1位异非或(XNOR)操作代替了大多数乘法,这可能对通用和专用深度学习硬件产生重大影响。我们编写了一个二值矩阵乘法GPU内核,使用它运行我们的MNIST MLP比使用未优化的GPU内核快7倍,而不会损失分类精度(参见第3节)。
1. BinaryNet
在本节中,我们将详细介绍我们的二值化函数,我们如何使用它来计算参数的梯度以及我们如何通过它进行反向传播。
Sign function
BinaryNet将权重和激活限制为+1或-1。从硬件的角度来看,这两个值非常有利,正如我们在第3节中解释的那样。我们的二值化函数就是符号函数:
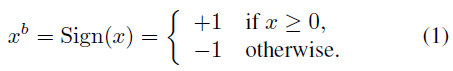
其中xb是二值化变量(权重或激活),x 是实值变量。它实现起来非常简单,并且在实践中运行良好(参见第2节)。可以使用随机二值化,如(Courbariaux et al., 2015),理论上更具吸引力,但也是一种成本更高的替代方案,因为它需要硬件在量化时生成随机位。
Gradients computation and accumulation
了解BinaryNet的一个关键点是,尽管我们使用二值权重和激活来计算参数的梯度,但我们仍然按照算法1在实值变量中累积权重的实值梯度。随机梯度下降(SGD)可能需要实值权重才能起作用。SGD通过小而带噪的步骤来探索参数空间,并且通过每个权重中累积的随机梯度贡献来平均化噪声。因此,为这些累加器保持足够的分辨率非常重要,乍一看,这表明绝对需要高精度。
除此之外,在计算参数的梯度时向权重和激活添加噪声提供了一种正则化形式,可以帮助更好地泛化,如之前的变分权重噪声(Graves, 2011)、Dropout (Srivastava, 2013; Srivastava et al., 2014)和DropConnect (Wan et al., 2013)。BinaryNet可以看作是Dropout的一种变体,在计算参数梯度时,我们不是将一半的激活值随机设置为零,而是将激活值和权重都二值化。

Propagating Gradients Through Discretization
符号函数的导数几乎处处为0,这显然与反向传播不兼容,因为成本相对于离散化之前的量(预激活或权重)的精确梯度为零。请注意,即使使用随机量化,这仍然是正确的。Bengio (2013)研究了通过随机离散神经元估计或传播梯度的问题。他们在实验中发现,使用之前在Hinton (2012)的讲座中介绍的"直通式估计器"时获得了最快的训练。
我们采用了类似的方法,但使用了直通估计器的版本,该版本考虑了饱和效应,并且确实使用了比特的确定性而不是随机采样。考虑符号函数量化:
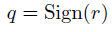
并假设已获得梯度![]() 的估计器gq(在需要时使用直通估计器)。然后,我们对
的估计器gq(在需要时使用直通估计器)。然后,我们对![]() 的直接估计器很简单:
的直接估计器很简单:

请注意,这会保留梯度的信息并在 r 太大时取消梯度。算法1说明了这种直通估计器的使用。导数1|r|≤1也可以看作是通过硬tanh传播梯度,也就是下面的分段线性激活函数:

对于隐藏单元,我们使用符号函数非线性来获得二元激活,对于权重,我们结合了两个成分:
- 将每个实值权重约束在-1和1之间,当权重更新使wr超出[-1, 1]时就将其映射为-1或1,即按照算法1在训练期间裁剪权重。否则,实值权重会变得非常大,而不会对二值权重产生任何影响。
- 使用权重wr时,使用wb = Sign(wr)对其进行量化。
根据公式2,这与|wr| > 1时的梯度抵消一致。
A few helpful ingredients
我们实验的一些元素,虽然不是绝对必要的,但显著提高了BinaryNets的准确性,如算法1所示:
- 批量归一化(BN) (Ioffe & Szegedy, 2015),在算法2中有部分详细说明,它加速了训练,而且似乎还降低了权重尺度的整体影响。归一化噪声也可能有助于正则化模型。
- 算法3中详述的ADAM学习规则(Kingma & Ba, 2014)似乎也减少了权重尺度的影响。
- 最后,正如Courbariaux et al. (2015)所建议的那样,使用来自(Glorot & Bengio, 2010)的权重初始化系数来缩放权重的学习率似乎也有帮助。
2. Benchmark results
MLP on MNIST
ConvNet on CIFAR-10
ConvNet on SVHN
3. Much faster at run-time
First layer
XNOR-accumulate
7 times faster on GPU at run-time
4. Related work
Conclusion