郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ArXiv 2021
Abstract
脉冲神经网络(SNN)与深度神经网络(DNN)相比,处理速度更快、能耗更低、生物可解释性更强,有望接近强人工智能。强化学习类似于生物学中的学习。研究SNN和RL的结合具有重要意义。我们提出了带有STBP的脉冲蒸馏网络(SDN)的强化学习方法。该方法通过蒸馏有效避免了STBP的弱点,在分类上可以达到SOTA性能,并且可以获得更小、收敛更快、功耗更低的SNN强化学习模型。实验表明,我们的方法比传统的SNN强化学习和DNN强化学习方法收敛速度更快,大约快1000个epoch,获得的SNN比DNN小200倍。我们还将SDN部署到PKU nc64c芯片上,证明SDN比DNN功耗更低,在大型设备上SDN功耗比DNN低600多倍。SDN提供了一种新的SNN强化学习方式,可以达到SOTA性能,证明了SNN强化学习进一步发展的可能性。
Introduction
大脑是动物最重要的器官。自从Cesar Julien Jean legallois定义了大脑区域的具体功能[1]以来,脑神经学就吸引了许多研究人员,并进行了许多复制大脑系统的实验。早在1958年,Rosenblatt就建立了基于脑神经元的感知器模型[2],为神经网络(NN)开辟了道路。Neuralink曾尝试将大脑神经元的活动转化为命令来控制猴子的外部设备[3]。Stephen Grossberg等人构建的神经模式识别机器架构[4]。也为后期的各种神经形态学芯片的设计提供了思路,包括TrueNorth [5]、Loihi [6]和Tianjic [7]。
自AlexNet [8]以来,深度神经网络(DNN)在语音和图像处理方面表现出卓越的性能。然而,DNN的高精度和高性能是基于非常高的功耗。此外,DNN的发展也逐渐偏离了模仿人脑、创造智能生活的初衷。脉冲神经网络(SNN)作为第三代神经网络,比DNN具有更低的功耗和更快的速度,并且在生物学上也更具可解释性[9]。有望以最接近大脑神经元范式的形式完成更复杂的认知问题,创造所谓的"电子生命"。另一方面,SNN的实现和应用是脑系统建模的一次大胆尝试,可能为神经病学提供宝贵而有意义的经验。
基于SNN的应用正在逐步改进:在分类方面,Riccardo Massa等人使用DVS进行手势识别[10];在目标检测方面,Kim S等人提出脉冲Yolo [11]。上述监督学习应用通过学习标签在准确率上取得了很好的效果。然而,要实现强人工智能,无监督学习和强化学习是必不可少的。强化学习是智能体通过与环境的交互和奖惩机制不断学习的一种方式。这种方式与生物的生长方式非常相似,也与SNN的研究理念不谋而合。
SNN强化学习的研究也在进行中:Nan Zheng等人通过使用脉冲时序依赖可塑性规则(STDP)训练硬件友好的actor-critic网络[12]。Mengwen Yuan等人通过结合享乐主义突触模型和STDP来训练SDC网络[13]。Vahid Azimirad等人通过使用STDP训练TCT网络[14]。Fatemeh Sharifizadeh等人使用r-stdp训练r-snn网络[15]。Devdhar Patel等人基于DNN训练DQN网络,然后将其转换为SNN [16]。大多数研究倾向于使用STDP及其改进版本来完成SNN强化学习。与此同时,一些研究也在寻找新的解决方案。
2018年,Yujie Wu等人提出了用于训练高性能SNN的时空反向传播(STBP)算法[17]。实验表明,STBP算法训练的SNN性能远高于STDP算法,是训练SNN的一种新方法。然而,STBP算法使用脉冲发放率编码[18],这将极大地压缩强化学习动作价值的搜索空间,导致直接使用STBP算法训练基于动作价值的SNN强化学习有困难。Guangzhi Tang等人在DDPG中用DNN实现了基于动作价值的网络,用SNN实现了基于确定性策略的网络,避免了SNN进行动作价值搜索的操作[19]。这是使用STBP算法训练SNN强化学习模型的少数研究之一。本文提出了另一种实现基于动作价值的SNN的方法,并有望用这种方法训练更小的SNN。
在本文中,我们提出了带有STBP的脉冲蒸馏网络(SDN)的SNN强化学习方法,该方法比传统的SNN强化学习和DNN强化学习算法取得了更好的效果。我们还证明了STBP中的脉冲发放率编码将极大地压缩强化学习动作价值的搜索空间。我们从知识蒸馏[20]中得到启发,将原来的DNN教师网络训练DNN学生网络的方式转变为DNN教师网络训练SNN学生网络的方式。这样,DNN就会进行强化学习训练和搜索动作空间。然后SNN将向DNN学习。这有效地避免了SNN搜索动作空间的工作,并且可以进一步压缩SNN的容量。
下面,本文首先介绍先验知识,然后详细介绍我们的SDN方法,并通过公式证明动作价值搜索对于STBP的劣势。然后,我们将SDN与其他SNN和DNN强化学习方法进行比较,以证明SDN的有效性和效率,并通过比较SDN中教师网络和学生网络的容量来证明SDN的可压缩性。此外,我们还将SDN模型部署在PKU NC64C芯片上,以证明SDN的低功耗。
METHODS AND MATERIALS
我们专注于如何有效地使用STBP来训练更智能的SNN强化学习模型,同时避免STBP压缩动作搜索空间的问题。在本节中,我们将详细介绍我们的方法。同时,我们证明STBP会大大压缩强化学习动作搜索空间,以说明我们方法的必要性。
Training of Teacher Net
脉冲蒸馏网络(SDN)的训练基于训练有素的DNN强化学习教师网络。我们使用DQN [21]来训练DNN教师网络。
我们考虑一个智能体与环境交互的场景。环境为智能体提供当前时刻的 T 步先前状态,S∈RT*H*W,以及每个时刻的奖励。环境提供的状态就是图像,H和W代表图像的高和宽,智能体根据状态选择下一步的动作a1或a2。智能体将获得的状态输入到DNN中。DNN预测a1和a2的Q值,这表示从当前时刻到游戏结束可以获得的奖励的累积。智能体选择具有最高Q值的动作作为其下一个即时动作。
对于DQN,损失函数如下:
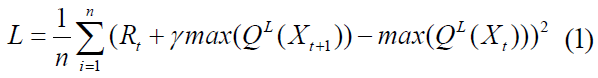
其中QL为第L层的DNN,γ为DNN预测结果的怀疑值,Xt和Rt是从经验池中随机抽取的,这存储了一段时间内的环境状态和奖励。
需要注意的是,SDN并不局限于强化学习DNN的训练方法。我们可以使用任何深度强化学习方法来训练我们的DNN教师网络,例如DDPG [22]、TD3 [23]、PPO [24]等,然后使用SDN来训练SNN。
Architecture of Spiking Distillation Network
脉冲蒸馏网络(Spiking Distillation Network, SDN)是一个使用DNN教师指导SNN学生的训练框架。与教师网络的训练相比,环境分别为DNN教师网络和SNN学生网络提供不同的预处理状态,并且不提供奖励。
对于DNN教师网络,环境为其提供当前时刻的 T 步先前状态,S∈RT*H*W。对于SNN学生网络,环境不会同时为其提供 T 步先前的状态。相反,这些状态st∈RH*W是按时间顺序提供的,这将为SNN提供强大的时间维度信息。
我们使用LIF神经元来描述我们的SNN模型。LIF神经元的状态由脉冲输入、膜电位和阈值电位决定。膜电位随着脉冲输入而累积。当膜电位超过阈值电位时,LIF神经元会发出脉冲信号。膜电位会随着时间的推移而泄漏和降低。LIF神经元的微分表达如下:
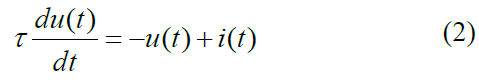
其中u(t)是LIF神经元在时间 t 的膜电位,τ 是泄漏率,I(t)是输入脉冲和权重的乘积。
为了使用STBP,我们需要将LIF神经元的表达分为三个部分:I(t)的计算,膜电位的累积u(t)和发放脉冲,在算法1中有描述。其中 t 是时间,l1是SNN学生网络的层数,![]() 表示SNN中第L层在时间 t 的脉冲发放情况,thresh是阈值电位,sp表示输出脉冲的数量,fr表示带有脉冲发放率编码的输出。
表示SNN中第L层在时间 t 的脉冲发放情况,thresh是阈值电位,sp表示输出脉冲的数量,fr表示带有脉冲发放率编码的输出。

τ 是STBP中LIF神经元用来获取时间维度信息的重要参数,可以区分不同时间序列的输入。假设 0 到 t 时刻ut都没有达到阈值电位,则 t 时刻LIF神经元的膜电位如下:
![]()
可以看出,通过自身的累加乘法,τ 完成了不同时间序列中输入的区分。
DNN的卷积很难对不同通道上不同时间序列的输入进行强区分,因为所有通道上相同位置的像素会被均匀相加乘得到一个输出像素,如下式所示:
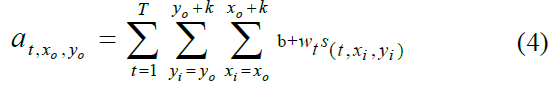
其中![]() 代表DNN第一层中位置x0, y0和通道 t 的像素,
代表DNN第一层中位置x0, y0和通道 t 的像素,![]() 代表输入中位置xi, yi和通道 t 的像素,wt代表DNN中的权重。
代表输入中位置xi, yi和通道 t 的像素,wt代表DNN中的权重。
这意味着当通道上具有不同时间顺序的输入被送到DNN的第一层时,第一层输出的每个通道将不再有很强的时间顺序差异,尽管输出的每个像素都融合了不同时间维度的信息,我们称之为弱微分。
SDN将首先积累经验池,保存由环境给出的 S 和st。st被发送到SNN学生网络,得到输出fr,我们提供fr给环境作为下一步动作选择的判断依据。当达到某个epoch且经验池已满时,SDN将开始使用存储在经验池中的内容来训练SNN学生网络。其中,经验池的作用是打乱样本的相关性,提高数据的利用率。SDN的整体架构如下图所示:
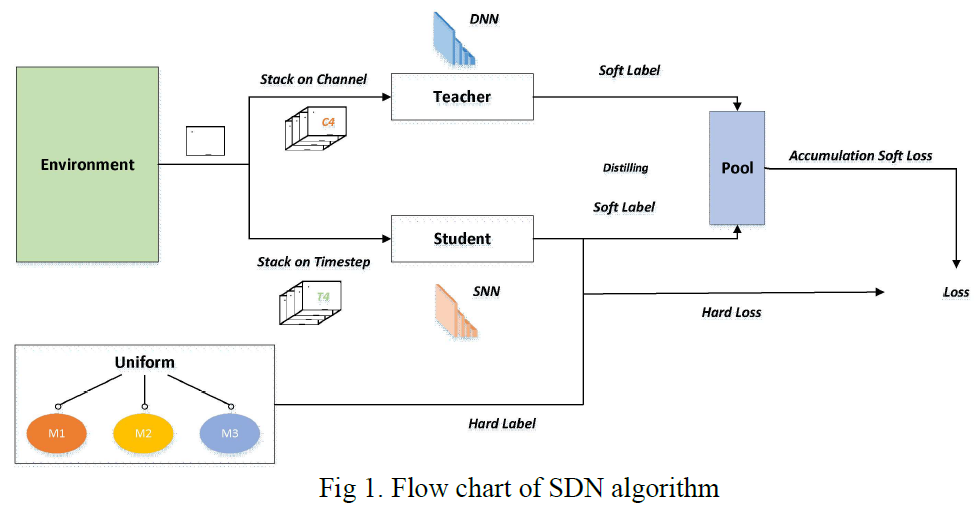
Training of SDN
SDN的训练过程如算法2所示。在开始时,SDN积累经验池。当epoch大于thresh_epoch时,经验池已满,我们将分批从经验池 D 中取出对应的环境状态Sb和![]() ,分别输入到SNN学生网络和DNN教师网络进行前向传播,得到相应的输出,frb和ob,并计算这两个输出的损失。
,分别输入到SNN学生网络和DNN教师网络进行前向传播,得到相应的输出,frb和ob,并计算这两个输出的损失。
我们使用的损失函数是带有 T 的CrossEntropy:我们将输出除以一个温度值来软化输出,然后通过Softmax和CrossEntropy计算SoftLoss。同时,我们将教师网络的输出设为one-hot作为硬标签,然后利用这个标签与学生网络的输出通过CrossEntropy计算HardLoss。将Softloss和Hardloss按比例相加,得到最终的损失函数。
然后,使用计算出的损失对学生SNN进行STBP反向传播,并从SD和TD更新学生SNN的参数。

Impact of STBP spike-rate coding on action value exploration space
我们统计了基于DQN和DDQN [25]的DNN输出和输出精度的变化,如下图所示。可以看出,DNN输出的动作价值是从小负数训练到大正数的。但是脉冲发放率编码的输出范围仅在0到1之间,很难表达变化范围如此大的动作价值,这使得在DQN和DDQN中直接训练基于动作价值强化学习(STBP)的SNN变得非常困难。
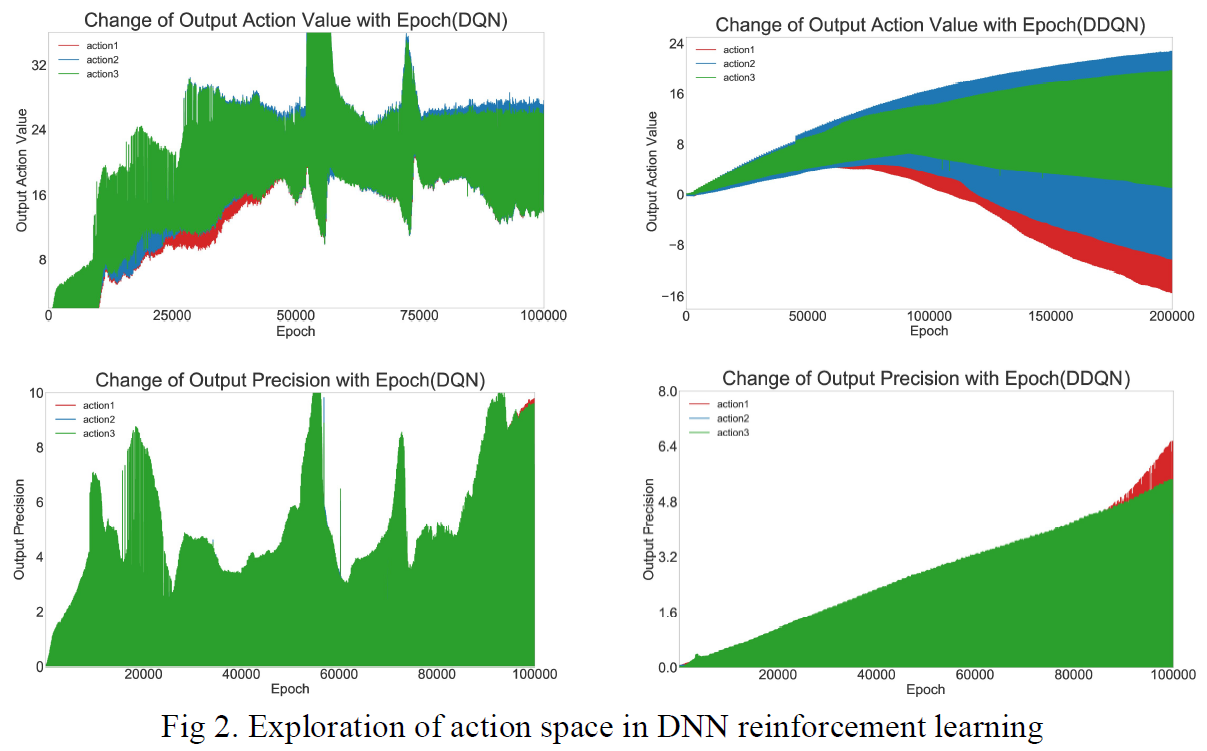
我们考虑使用仿射变换将DNN训练的输出准确地映射到STBP脉冲发放率编码xfr的范围(使用准确率accfr)。
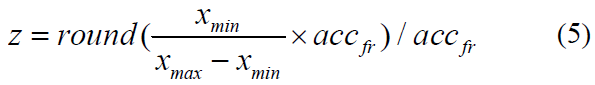
其中:
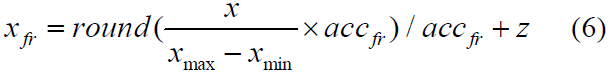
为了这个仿射变换不会造成损失,我们至少需要指定:
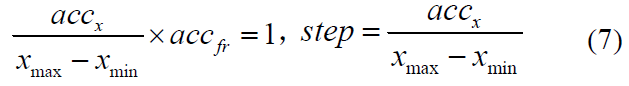
结合以上数据,脉冲发放率编码所需的步骤会达到1e5量级,这意味着需要消耗大量的能量和推断速度,给推断和训练带来很大的负担。SDN有效地避免了这种搜索,并以较少的步骤完成了SNN的强化学习训练。
Experiments
在第一部分,我们为SDN尝试了不同的损失函数并得到了最好的损失函数:CrossEntropy with Temperature(T)。然后,我们将我们的SDN与其他SNN方法进行比较,以确认SDN的有效性。此外,我们将DNN强化学习方法与SDN进行了比较,结果表明SDN具有良好的学习能力。所有实验均在Pong游戏环境中进行,如图3所示。
Comparison of different Loss treatments of SDN
对于SDN中的损失函数,我们测试了均方误差函数和交叉熵函数,如图4所示。对于均方误差,由于DNN的输出范围不适合SNN输出脉冲发放率编码的范围时,我们尝试将DNN的输出映射到我们设定的范围内,这样就可以通过DNN和SNN的输出来计算损失函数。根据DNN输出的柔软度,我们将映射范围分为三个独立的实验:(1) 设置DNN输出的最大值为1,另一个为0。(2) 线性缩放DNN输出中的最大值。(3) 线性缩放DNN输出中的最大值(2)并调整公式中的剩余值。公式中的调整是为了扩大最大值和其他值之间的差异。
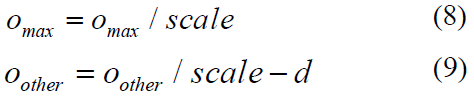
其中scale是线性缩放的比例因子,D用于扩大最大值和其他值之间的差异。
对于带有 T 的CrossEntropy,我们设置T=10,λ=0.9。
从下图可以看出,带有 T 的CrossEntropy的训练方法中的奖励最多,因此我们选择带有 T 的CrossEntropy作为SDN中的损失函数。

Comparison of SDN and other SNN reinforcement learning methods
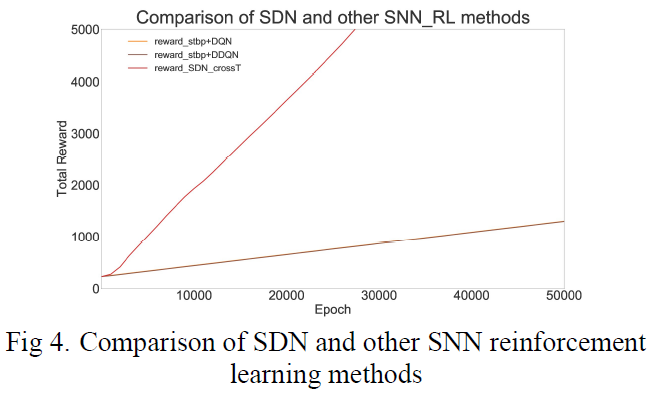
我们将SDN与其他SNN强化学习方法进行了比较,如图4所示。可以发现STBP结合DNN并不能达到理想的学习效果,但是SDN的效果比STBP强化学习的效果要好很多,这与上面对STBP脉冲发放率编码对动作价值探索空间的影响的解释是一致的。
Comparison of teacher network and student network in SDN
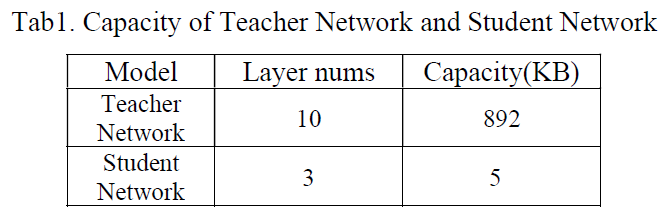
我们采用较大结构的DNN教师网络来训练较小的SNN学生网络。在pong比赛中,我们使用了10层大小为892 KB的教师网络,而训练出来的SNN学生网络只有3层,大小为5 KB,压缩了近200倍,证明了SDN有能力训练更小的SNN。
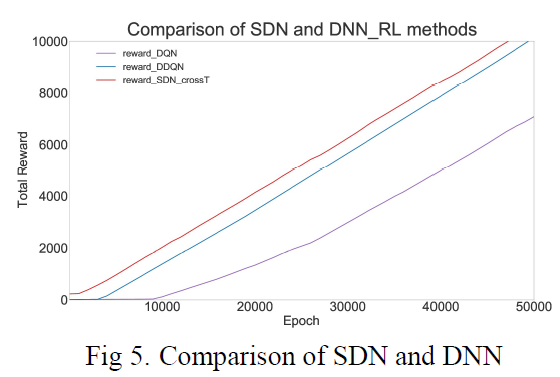
Comparison of SDN and DNN
此外,我们尝试将DNN强化学习方法与SDN进行比较,如图5所示。由于时间维度信息的结合,SDN的学习速度比DNN快,获得的奖励也比DNN多。
Deployment
为了证明SDN在低功耗方面的效果,我们将其部署在PKU NC64C芯片[26]上,并与各种设备进行了比较,如表2所示。可以看出,与NVIDIA rtx2080等大型设备相比,SDN的功耗降低了600多倍;与NVIDIA Jetson NX等嵌入式设备相比,SDN的功耗也降低了10倍以上。

Discussion and Conclusion
与DNN相比,SNN具有更低的功耗和更快的速度,更接近于大脑神经元范式的形式。与其他类型的机器学习相比,强化学习更接近生物学习增长的本质。因此,探索两者的结合具有重要意义。
本文提出了一种新的SNN强化学习算法:脉冲蒸馏网络(SDN)(使用STBP)。该方法将动作价值空间的搜索交给DNN,通过类似的知识蒸馏方法,让DNN教师网络训练SNN学生网络。SDN可以取得比传统SNN和DNN强化学习算法更好的结果。
我们用公式证明STBP不利于动作价值空间的搜索,说明SDN的必要性。此外,我们通过实验证明,SDN的收敛速度比传统的SNN和DNN强化学习算法要快,体现了SDN的高效率。同时,我们也通过实验证明,SDN中学生网络的容量可以远小于教师网络,这说明了SDN的可压缩性。最后,我们将SDN部署在PKU NC64C芯片上,结果表明其功耗低于其他设备,显示了SDN的低功耗。
对于未来的工作,我们可以将更多的DNN强化学习算法移植到SDN中,比如A3C、DDPG等,尝试使用其他蒸馏方法来提高SDN中SNN的准确率,并使用新的方法进行更多的游戏训练。NVIDIA Jetson NX、SDN等设备的功耗也低于10倍。