郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

FRONTIERS IN NEUROSCIENCE, (2017): 350
Introduction
本文介绍了一种在脉冲神经网络(SNN)系统中训练事件驱动分类器的新方法,该方法能够在使用合成输入数据和从动态视觉传感器(DVS)芯片捕获的真实数据时产生良好的分类结果。所提出的监督方法使用由先前SNN层的任意拓扑结构提供的脉冲活动来构建直方图并使用随机梯度下降算法在帧域中训练分类器。此外,这种方法可以处理SNN中LIF神经元模型,这是现实世界SNN应用的理想特性,在没有输入的情况下,神经激活必须在一段时间后消失。因此,这种构建直方图的方式可以捕捉到分类器之前的脉冲动态。我们使用不同的合成编码和真实的DVS感官数据集(例如N-MNIST、MNIST-DVS和Poker-DVS,使用相同的网络拓扑和特征图)在MNIST数据集上测试了我们的方法。我们通过使用脉冲卷积网络实现迄今为止在N-MNIST (97.77%)和Poker-DVS (100%)真实DVS数据集上报告的最高分类准确度来证明我们的方法的有效性。此外,通过使用所提出的方法,我们能够重新训练先前报道的脉冲神经网络的输出层并将其性能提高2%,这表明所提出的分类器可以用作使用无监督基于脉冲的学习方法来提取特征的工作中的输出层。此外,我们还分析了与最终硬件实现相关的SNN性能数据,例如总事件活动和网络延迟。总而言之,本文将无监督训练的SNN与有监督训练的SNN分类器聚合在一起,将它们组合并应用于异构基准集,包括合成的和来自真实DVS芯片的基准。
Keywords: spiking neural networks, supervised learning, event driven processing, DVS sensors, convolutional neural networks, fully connected neural networks, neuromorphic
1. INTRODUCTION
深度学习和深度人工神经网络(LeCun et al., 2015; Schmidhuber, 2015)目前在几乎所有机器学习基准测试中都拥有最先进的性能,包括计算机视觉、语音识别、自然语言处理、音频识别(仅举几例),在某些情况下,它们已经超过了人类的识别率(Schmidhuber, 2012; He et al., 2015)。由于这些原因,它们被称为我们十年的突破性技术之一(MIT Technology Review, 2013),并引起了学术界和工业界的广泛关注。深度学习实现分层特征提取;每增加一层,网络就会学习提取更多抽象特征,而事实证明,通过增加层数可以提高分类性能(Hinton and Salakhutdinov, 2006)。这些最先进的深度神经网络所需的大量操作禁止它们在处理和能源资源有限的平台上执行。目前,它们的执行被卸载到远程计算机集群。然而,这会引入额外的通信开销,从而增加整体系统延迟。对于某些应用,快速响应和低能耗是关键特性,例如在移动平台、机器人和关键系统中。
脉冲神经网络(SNN)(Gerstner and Kistler, 2002)最近被证明是模拟大规模神经网络的有趣替代方案(Izhikevich and Edelman, 2008; Ananthanarayanan et al., 2009; Eliasmith et al., 2012)。SNN本质上是异步的;与生物学类似,脉冲神经元通过通常称为脉冲的事件进行交流。每个脉冲神经元在接收到传入脉冲时更新其内部状态,并在其膜电压超过阈值时产生输出。神经形态工程的最新进展(Mead, 1990)能够直接在神经形态硬件上实时(毫秒更新)或加速模拟SNN,与传统计算平台相比,在功率和速度方面具有更高的效率,尽管需要大量的通信基础设施开销。例如,当前最先进的神经形态平台TrueNorth (Merolla et al., 2014)能够实时模拟100万个脉冲神经元,同时消耗63 mW。在高性能计算平台上执行的等效网络比实时慢100-200倍,并且每个突触事件1消耗的能量多100000到300000倍(Merolla et al., 2014)。TrueNorth能够在实时执行时每瓦每秒提供460亿次突触操作(Sops/W),并且以比实时(200 μs更新)快5倍的速度执行700亿次Sops/W。在神经形态平台上模拟SNN的另一个优势是它们基于事件的性质使它们更适合与低功耗、低延迟、高动态范围的神经形态视觉和听觉传感器一起使用(Lichtsteiner et al., 2008; Liu et al., 2010; Lenero-Bardallo et al., 2011; Posch et al., 2011, 2014; Serrano-Gotarredona and Linares-Barranco, 2013)。
SNN已被描述为第三代人工神经网络(ANN),虽然它们在理论上比传统的连续或基于发放率的ANN具有更强的计算能力(Maass and Markram, 2004),但它们仍然缺乏前辈的成功。对此的一个可能解释是缺乏复杂的训练算法,如过去几十年为ANN开发的那些算法。由于脉冲神经元的激活函数不可微(由于阈值条件),SNN无法直接使用ANN中使用的流行训练方法,例如需要可微函数的反向传播。为了解决这个问题,研究小组目前专注于两种不同的路径:要么采用生物学合理的无监督学习规则,如脉冲时间依赖可塑性(STDP)(Dan and Poo, 1992)从输入中提取特征(Masquelier and Thorpe, 2007; Bichler et al., 2012; Neftci et al., 2014; Diehl and Cook, 2015; Kheradpisheh et al., 2016)或者他们遵循中间步骤:使用基于连续/发放率的神经元模型离线训练神经网络(ANN)与最先进的监督训练算法(LeCun et al., 1998; Hinton et al., 2006),然后将训练后的网络映射到SNN (Merolla et al., 2010; O'Connor et al., 2013; Pérez-Carrasco et al., 2013; Diehl et al., 2015),准备在神经形态平台上高效执行(Camuñas-Mesa et al., 2010; Arthur et al., 2012; Furber et al., 2014; Merolla et al., 2014; Stromatias et al., 2015a)。
虽然当前SNN分类任务的最新结果来自后一种方法(Diehl et al., 2015; Rueckauer et al., 2016),但仍有许多通常没有解决的缺点。一个主要问题是这些神经网络是使用合成数据进行训练的。也就是说,馈送到SNN的输入脉冲活动是从帧图像(如MNIST)人工生成的,其中使用某种算法方法(如流行的泊松分布编码)以数学方式将图像像素的灰度级转换为脉冲流。当切换到使用物理脉冲硅视网膜(例如神经形态动态视觉传感器(DVS))捕获的非合成真实输入数据时,这会带来实际问题(Lichtsteiner et al., 2008; Posch et al., 2011; SerranoGotarredona and Linares-Barranco, 2013)。在这种情况下,来自这些传感器的脉冲信号/事件的时间分布不是泊松分布,这导致SNN在分类精度方面表现非常差。我们的个人经验是,当将整个网络从ANN映射到SNN时,如果输入数据是作为泊松脉冲分布合成生成的,那么精度损失是低/合理的。然而,如果同一网络的输入数据被从脉冲硅视网膜(如N-MNIST、MNIST-DVS、Poker-DVS)记录的真实感官数据取代,准确性会急剧下降(Orchard et al., 2015a; Serrano-Gotarredona and Linares-Barrance, 2015; Soto, 2017)。事实上,报告的高精度工作在帧域中训练一个完整的网络并将其映射到SNN域总是使用合成数据报告结果(Merolla et al., 2010; O'Connor et al., 2013; Diehl et al., 2015)
另一方面,近年来的工作表明,使用STDP和其他无监督方法,例如基于事件的对比发散(CD) (Neftci et al., 2014, 2016)可以利用SNN有效地学习特征(Masquelier Thorpe, 2007; Bichler et al., 2012; Diehl and Cook, 2015; Kheradpisheh et al., 2016)。使用STDP的一个优势是它本质上考虑了来自DVS传感器的事件的时间分布(Bichler et al., 2012; Roclin et al., 2013)。然而,在提取SNN特征后,许多研究人员使用一种方法将SNN的异步事件转换为ANN的帧,以训练基于帧的分类器,例如支持向量机(SVM) (Kheradpisheh et al., 2016)或径向基函数(RBF)分类器(Masquelier and Thorpe, 2007)并评估脉冲域学习特征"好"的程度。通常这种转换是由一群具有无限阈值的LIF神经元完成的(Masquelier and Thorpe, 2007)。神经元整合来自前几层的输入,当控制信号到达时,它们输出它们的内部状态并创建一个帧。在实际的SNN系统中,例如,如果将其完全部署为紧凑型硬件,则非常希望包括分类器在内的所有阶段都可以在脉冲域中实现。
最近的工作成功地探索了脉冲域的直接训练。例如,Lee et al. (2016)提出了一种类似反向传播的技术,用于直接训练具有全连接层间连接的多层SNN。他们使用了realDVS记录的(N-MNIST)输入传感数据(Orchard et al., 2015a)并报告了迄今为止使用FC(全连接)拓扑和DVS数据报告的最佳准确度(98.66%)。Neftci et al. (2017)最近提出了一个简单的事件驱动随机反向传播规则来快速学习深度表征,尽管它们只提供合成输入数据的结果。
在本文中,我们提出了一种以监督方式仅训练基于事件的分类器的替代方法。这种基于脉冲的分类器可以用作任何已经提取特征的SNN中的输出层,例如使用STDP或其他无监督方法(Bichler et al., 2012; Roclin et al., 2013; Neftci et al., 2014, 2016; Diehl and Cook, 2015; Kheradpisheh et al., 2016),或微调已经训练好的SNN (O'Connor et al., 2013)。这里提出的方法基于在帧域中训练然后用事件进行测试的思想,但不是训练完整的ANN然后将其映射到SNN,它使用(预分类器)SNN的脉冲输出活动来创建一个新的基于帧的数据集,它捕获脉冲的动态。然后,这些SNN敏感帧用于在新数据集上使用随机梯度下降(SGD) (Bottou, 2010)等监督学习算法来训练全连接的分类器。训练后,基于帧的ANN分类器直接映射到LIF神经元群,用作SNN的输出层。这种方法的优点是易于利用流行的监督训练算法实现,它对合成数据和真实的DVS数据都有很好的预测精度,并且可以在分类性能损失最小的情况下处理神经元泄漏。据我们所知,这种训练SNN分类器输出层的技术以前从未有过报道2。
本文的结构如下:第2节讨论了用于这项工作的数据集,其中包括从DVS传感器记录的数据和从静态图像合成生成的脉冲序列。第2.2节介绍了用于这项工作的SNN模拟器。第2.3节描述了用于所有实验的神经网络的拓扑结构。第2.4节介绍了神经元和突触模型。第2.5节描述了所提出的使用帧以监督方式训练分类器的方法以及如何将其转换回SNN。第3节介绍了结果,最后,第4节介绍了一些讨论和结论。
1突触事件被定义为击中单个突触的脉冲。
2另一方面,在ANN域中训练完整网络并将其映射到SNN是一种众所周知的方法。
2. MATERIALS AND METHODS
2.1. Data Sets
对于这项工作,我们使用了两种具有不同编码方法的数据集:MNIST手写数字数据集和用DVS摄像机记录的扑克牌组数据集。
原始MNIST数据集(LeCun et al., 1998)由70000张手写数字的28 × 28灰度图像组成,其中60000个数字用于训练,10000个数字用于测试。在本文中,我们使用MNIST数据集的4个变体。前两个使用不同的方法(Liu et al., 2016)将原始MNIST静态图像转换为人工脉冲训练,(a) 泊松编码和 (b) 强度-延迟编码。另外两个利用从DVS传感器记录的脉冲信号,称为 (c) MNIST-DVS (Serrano-Gotarredona and LinaresBarranco, 2015)和 (d) N-MNIST (神经形态MNIST) (Orchard et al., 2015a)。
扑克牌数据集包括 (e) 在DVS传感器前以非常高的速度浏览扑克牌组(Serrano-Gotarredona and Linares-Barranco, 2015),或 (f) 将纸上印刷的符号显示到DVS (Soto, 2017)。接下来我们简要描述不同的数据集:
(a) MNIST Poisson Encoding.
(b) MNIST Intensity-to-Latency Encoding.
(c) MNIST-DVS data set.
(d) N-MNIST data set.
(e) Fast-Poker-DVS data set.
(f) Slow-Poker-DVS data set.
2.2. Spiking Neural Network Simulator
对于这项工作,我们使用模块化事件驱动增长异步模拟器(MegaSim)3作为我们的主要模拟平台。MegaSim是一种设计用于模拟Address-Event-Representation (AER) (Mahowald, 1994)多模块硬件系统行为的工具,重点强调模块的硬件性能参数(处理延迟、握手和通信延迟、参数变化、噪声等)。
在MegaSim中,用户定义了通过AER链接(也称为"节点")互连的模块的网表。模块处理进入其输入AER节点的事件并在其输出AER节点上生成输出事件。网表还包含至少一个"源节点",它提供带时间戳的事件列表(来自DVS记录,或人工创建)。MegaSim中的模块可以有任意数量的输入/输出端口,可以是神经元群体、用标准C编程语言描述的算法或两者的组合。在启动时,只有源节点中的事件可用,它们被标记为"未处理"。MegaSim查看所有节点,挑选最早的未处理事件,将其标记为"已处理",调用接收它的模块, 并在各个模块内进行相应的处理。如果模块在其一个或多个输出端口生成事件,则将它们写入这些节点上,时间戳等于实际时间或等于某个未来时间,以防模块被建模为具有某些处理延迟,同时将它们标记为"未加工"。每次将事件添加到节点的未处理事件列表中时,所有未处理事件都会根据其时间戳重新排序。
AER事件使用3个计时值和n个事件参数表示。事件参数通常为3,并采用X、Y和极性的形式。但是,这些参数可以是任何有符号整数,并且由用户决定模块如何解释和处理它们。3个时序参数包括:预请求(pre-Rqst)表示事件在模块内创建的时间、请求(Rqst)表示该事件实际放在节点上的时间以及确认(Ack)是传送确认信号的时间。当一个事件已在链接或节点中排队时,通过将Rqst和Ack设置为-1将其标记为"未处理"。一旦Rqst和Ack都为正数,则意味着它们被标记为"已处理"。
模拟通过设置最大模拟时间或在没有更多"未处理"事件时结束。当模拟完成时,网络中的每个节点都会有一个带时间戳的处理事件列表。然后可以使用像jAER (Delbruck, 2013)这样的动态事件查看器来可视化节点的活动。
2.3. Network Architecture
2.3.1. Convolutional Neural Network
2.3.2. Fully Connected Network
2.4. Neuron Model
2.5. Methodology for Training an Event-Driven Classifier
对于这项工作,两种SNN架构都已经提取了特征。对于ConvNet拓扑(图2),这是通过对C1层使用一组"足够丰富"的预编程特征检测滤波器来完成的,如图3所示。对于全连接网络(图4),使用O'Connor et al. (2013)描述的无监督方法训练2个隐藏层。这里接受训练的唯一权重是全连接脉冲分类器(输出层)的权重。
然而,这里的训练不是在脉冲域中进行的。 我们在这项工作中使用的方法包括以下步骤:
- 将每个样本的刺激脉冲序列提供给SNN(第1层)的输入,并通过在"Flatten"模块用于ConvNet拓扑,第二层的输出用于全连接拓扑。
- 使用这些向量(帧)来训练使用随机梯度下降(SGD)的全连接(非脉冲)分类器。
- 将学习分类器权重的缩放版本用于脉冲分类器。
原则上应该影响训练和测试的一个参数是泄漏率。根据泄漏率值,归一化直方图可能会略有变化,因此学习权重也会发生变化。因此,应使用与用于获得归一化直方图相同的泄漏率进行测试。事实上,在关于脉冲神经网络的文献中报道的许多作品都没有使用泄漏(Diehl et al., 2015; Rueckauer et al., 2016)或以秒为单位使用泄漏(O'Connor et al., 2013)。然而,如果没有泄漏,在提供代表输入模式的脉冲信号后,所有神经元都需要重置以准备下一次输入。在这种情况下,输入样本必须逐个样本(SBS)提供,并且系统需要在新样本演示之间重置。在实际场景设置(例如,移动机器人)中,系统不知道新样本何时进入,而应在连续模式下工作。这是当泄漏进入时,神经活动在输入模式激活后一段时间消失。在这种情况下,无需重置神经元状态,系统以连续方式运行。因此,如果存在非零泄漏,我们可以一个接一个地呈现输入模式,只要有足够的采样间时间来允许神经元状态淡入到它们的静止状态。在这种情况下,我们可以将所有符号作为唯一的输入脉冲序列传递。我们称这种情况为"One Pass"(OP)。对于本文的其余部分,我们将区分SBS(零泄漏)和OP(非零泄漏)设置,用于训练(即获得归一化直方图)和测试。我们注意到,总的来说,SBS的表现略好于OP。
接下来,我们更详细地描述训练过程所遵循的三个步骤中的每一个。
2.5.1. From Events to Frames
使用脉冲模拟器MegaSim,我们在ConvNet拓扑中的模块"Flatten"的输出和全连接拓扑的第二层收集脉冲序列,以便为每个样本创建归一化脉冲直方图。对于"Flatten"层中的每个神经元(参见第2.3节),我们计算脉冲的总数。得到的直方图相对于最大值进行归一化,从而得到一个在区间[0,1]内具有N个分量的模拟向量,N是flatten层的输出数量。这些产生的脉冲直方图根据数据集、C1层的参数以及是否有泄漏而变化。
2.5.2. Training
每个输入样本的Flatten层(图2)的脉冲计数的归一化直方图被转换为模拟向量(帧)。对训练集和测试集重复此操作,以创建将用于训练分类器的新数据集。
用于这项工作的分类器是使用小批量随机梯度下降(MSGD) (Bottou, 2010)无偏差训练的Softmax回归。分类器的输出Y = (Y1, · · · , Yk, · · · )表示每个类别 K 的分数或概率。Softmax激活函数导致以下类别 K 输出预测概率对于给定的输入向量xi:
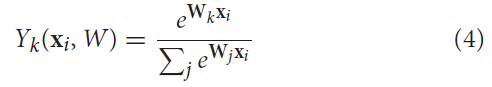
其中 W 是权重矩阵,xi 是输入向量,输入到由Flatten层提供的分类器。向量 Wk 是表示类别 K 的权重矩阵线。请注意,所有类别的概率相加为1。
MSGD算法要最小化的成本函数是负对数似然损失(NLL),其描述为:
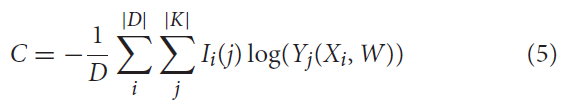
其中 D 是小批量,K 是类集,对于j = Li,Ii(j) = 1,否则为0。Li 是样本 i 的目标输出(标签),Yj 是Softmax单元 j 的输出。
SGD的目的是通过更新模型W ∈ ℜh×|K|的参数来最小化成本函数NLL,其中 h 是Flatten层的大小,K 是类的数量。MSGD通过计算相对于目标函数权重的梯度来更新每个小批量后的权重矩阵,
![]()
其中 η 是学习率,它决定了达到最小值所采取的更新步骤的大小。对于这项工作,我们使用了固定的学习率和固定的epoch数。
给定输入 xi 的模型预测类 yi 被视为具有最大激活的单元,并描述为:
![]()
2.5.3. From Frames Back to Events
在训练过程结束后,学到的权重被一个常数整数 K 缩放。这个整数应该是全连接分类器脉冲神经元THFC的阈值的数量级。正如我们将在第3节中看到的,我们设置THFC = K,其中 K 始终等于10000000。
3. RESULTS
3.1. Synthetic MNISTs
3.2. N-MNIST
3.3. MNIST-DVS
3.4. Slow-Poker-DVS
3.5. Fast-Poker-DVS
3.6. SNN Fine-Tuning
3.7. Summary of Results and Comparison with Related Work
4. DISCUSSION