一、Play it again: reactivation of waking experience and memory(Trends in Neurosciences 2010)
来自啮齿动物的越来越多的证据表明,称为尖波/波纹(SWR)的网络事件在海马体依赖性记忆巩固中起着关键作用。
海马体依赖性记忆形成可能在两个主要阶段发生。首先,海马体在清醒时快速地编码记忆。然后,在“离线时段”内,海马体会“重新激活”记忆轨迹,从而促进转移到皮层网络中的长期储存状态,或促进海马体内外不同大脑区域的轨迹之间的关联。
随着动物的探索,不同组的细胞在环境中的特定位置一起发放。保留这些发放模式的时空组织可以为清醒经验的记忆轨迹提供基础。CA3区域是这种轨迹的一个潜在存储库,该区域具有强烈的循环连接性和高度可修改的突触。
SWR发放模式不仅反映了环境,而且反映了行为,这进一步表明来自以下事实:在以后的睡眠中,访问频率较高的地方会更强烈地重新激活。结果表明,在随后的睡眠过程中,编码特定位置的细胞的发放同步性随着在先前探索期间在该位置花费的时间而增加。因此,重新激活的模式偏向访问量最大的地方。
总之,这些发现表明,与探索有关的发放模式在睡眠期间会重新激活。因此,到目前为止,尚未直接显示,重新激活的模式表示巩固过程中的记忆轨迹。即便如此,我们知道,重新激活的模式代表了以前的清醒经验,首先需要将其存储在海马体中。
因此,依赖于NMDAR的突触可塑性可以作为后续重新激活的记忆轨迹的存储基础。
最近的一份报告表明,在随后的睡眠中,细胞的联合发放趋势(共同发放)取决于它们在探索过程中一起发放的次数。
将新的清醒经验的不稳定表示整合到先前存在的表示中,可能需要其他过程来防止其因干扰现有的表示而退化。
Tulving及其同事提出了“新颖性编码假设”,即长期存储信息的可能性随信息的新颖性而直接变化。以这种方式,在新的经验之后增强的重新激活可以优先促进代表那些事件的记忆轨迹的巩固。与此假设相符,重新激活在新颖的探索之后比熟悉的环境更强。
这些数据表明SWR的双重作用,既有利于主动探索过程中的初始轨迹采集,又有助于促进存储轨迹的回放。实际上,最近的数据表明,海马体可以在编码和回放模式之间快速切换。
在记忆形成的两阶段模型中,一个假设是在睡眠期间会发生轨迹重新激活,以减少正在进行的轨迹形成所造成的干扰。但是,最近的发现表明,SWR在短暂的探索停顿期间也发生了重新激活。
但是,这种轨迹运行的“回放”顺序是相反的,因此,最近访问过的位置会被首先回放。
因此,在清醒活动期间,海马体可以在编码和回放模式之间快速切换。在探索过程中,反向回放可能有助于协调近期的脉冲活动,并可能促进表示环境中显著特征(例如奖励)的细胞之间的关联。
有几条证据表明,整个大脑的重新激活是协调的。这种协调且全脑范围的激活,与分布在不同大脑区域的记忆轨迹回放一致,且每个区域都贡献了轨迹的一部分,反映了其在清醒过程中的作用。
Box 2. Outstanding questions
- 尽管研究表明重新激活的模式与动物的先验行为有关,并且SWR的发放可以促进空间学习,但尚无研究表明重新激活本身是反映获得的记忆轨迹还是在巩固过程中起作用。因此,必须问:
- 具体来说,在复杂的记忆任务中,重新激活是否反映了已学到的内容?
- 例如,在一项必须学习许多项目的任务中,与学得不好的项目相比,被召回项目的表示是否被更强烈或更频繁地重新激活?
- 通常,重新激活可以预测对所获取信息的未来召回吗?
- 尚无有关重新激活如何促进巩固的数据;重新激活是否可能导致海马体信息的转移,和/或加强不同大脑区域的助记项之间的关联?
- 重新激活是否在巩固所有类型的海马体依赖性记忆或仅某些类型的记忆中发挥作用?
- 另一个未解决的问题与重新激活背后的机制有关。虽然可能需要突触可塑性来存储重新激活的模式,但尚不清楚哪种网络事件会导致可塑性变化以及在细胞和突触水平上会发生什么变化。
- 最后,还不清楚控制特定模式重新激活的因素。海马体外输入是否控制重新激活哪些模式?
二、Playing Atari with Deep Reinforcement Learning(CoRR 2013)
为了减轻相关数据和非平稳分布的问题,我们使用一种经验回放机制,该机制随机采样先前的转换,从而使训练分布在许多过去的行为上变得平滑。
与TD-Gammon和类似的在线方法相比,我们使用一种称为经验回放的技术,在该技术中,我们将智能体在每个时间步骤的经验存储在数据中,将许多回合汇聚到一个回放内存中,数据集D = e1, ... , eN,其中et = (st, at, rt, st+1)。在算法的内部循环中,我们将Q学习更新或小批量更新应用于从存储的样本池中随机采样的经验样本e ~ D。
与标准的在线Q学习相比,该方法具有多个优势。首先,经验的每个步骤都可能在许多权重更新中使用,这可以提高数据效率。其次,由于样本之间的相关性强,因此直接从连续样本中学习是无效的。将样本随机化会破坏这些相关性,因此会减少更新的方差。第三,当学习策略时,当前参数确定训练参数的下一个数据样本。例如,如果最大化动作是向左移动,则训练样本将由左侧样本控制;如果最大化动作然后切换到右侧,则训练分布也将切换。很容易看出不必要的反馈回路是如何产生的,参数可能会陷入一个很差的局部最小值,甚至会发生灾难性的发散。通过使用经验回放,行为分布可以在其许多先前状态中进行平均,从而平滑学习过程并避免参数出现波动或发散。请注意,在通过经验回放进行学习时,有必要学习异策(因为我们当前的参数与用于生成样本的参数不同),这激发了选择Q学习的动机。
实际上,我们的算法仅将最近的N个经验元组存储在回放内存中,并在执行更新时从D中随机均匀采样。该方法在某些方面受到限制,因为内存缓存不区分重要的转换,并且由于有限的内存大小N而始终用最近的转换覆盖。类似地,均匀采样对回放内存中的所有转换都具有同等的重要性。一种更复杂的采样策略可能会强调我们可以从中学习最多的转换,类似于优先扫描。
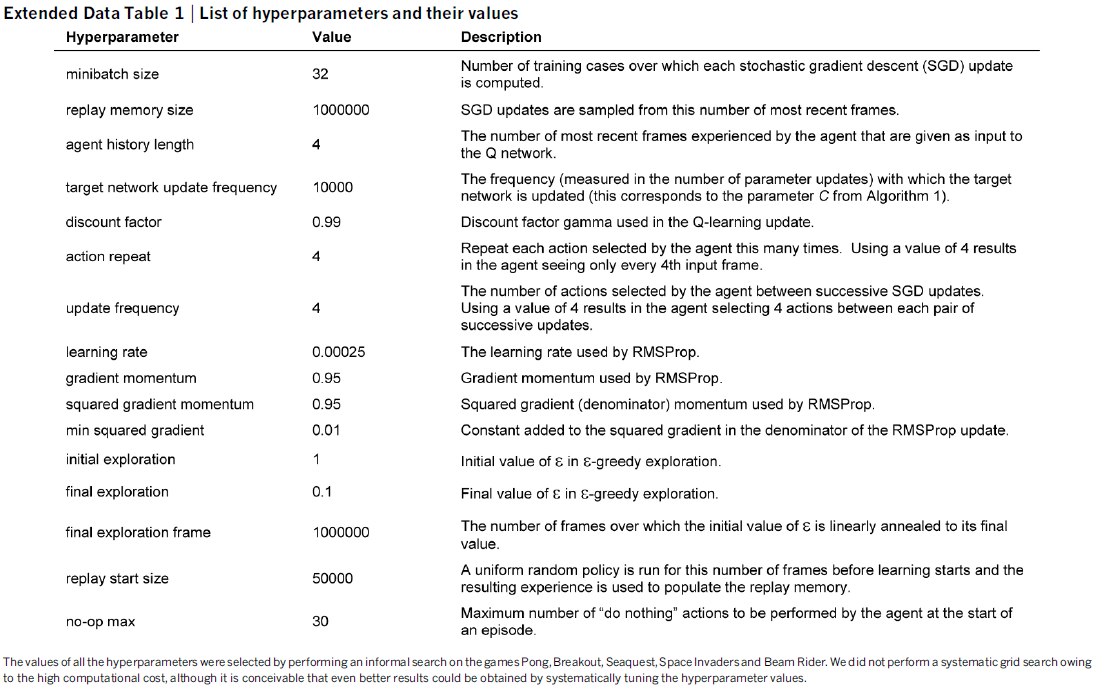
在这些实验中,我们使用小批量(大小为32)的RMSProp算法。训练过程中的行为策略是ε-贪婪,在前一百万帧中从1到0.1线性退火,此后固定为0.1。我们总共训练了1000万帧,并使用了一百万个最新帧的回放内存。

三、Human-level control through deep reinforcement learning(Nature 2015)
首先,我们使用一种受生物学启发的机制(被称为经验回放)对数据进行随机化,从而消除了观察序列中的相关性,并平滑了数据分布的变化(有关详细信息,请参见下文)。
为了执行经验回放,我们在每个时间步骤 t 将智能体的经验et = (st, at, rt, st+1)存储在数据集Dt = {e1, ... , et}中。在学习过程中,我们对经验的样本(或小批量)(s, a, r, s') ~ U(D)应用Q学习更新,这些样本是从存储样本池中随机采样的。
值得注意的是,RL与深度网络结构的成功集成在很大程度上取决于我们结合使用回放算法,其中涉及存储和表示最近经验的转换。越来越多的证据表明,海马体可能支持哺乳动物大脑中这种过程的物理实现,在离线时期(例如,清醒的休息)期间最近经验的轨迹的时间压缩重新激活提供了一种推定的机制,通过该机制可以有效地发挥价值函数,通过与基底神经节的交互来更新。未来,探索将经验回放的内容偏向显著事件的潜在用途非常重要,这种现象是根据经验观察到的海马体回放的特征,并且与RL中"优先扫描"的概念有关。综上所述,我们的工作说明了将最新的机器学习技术与受生物启发的机制相结合所产生的力量,这些力量可以创造出能够学习掌握各种挑战性任务的智能体。
在这些实验中,我们使用小批量(大小为32)的RMSProp算法。训练期间的行为策略是ε-贪婪,ε在最初的一百万帧中从1.0线性退火到0.1,然后在之后固定为0.1。我们总共训练了5000万帧(即总共大约38天的游戏经验),并使用最近一百万帧的回放内存框架。
首先,我们使用一种被称为"经验回放"的技术,在该技术中,我们将智能体在每个时间步骤的经验et = (st, at, rt, st+1)存储在数据集Dt = {e1, ... , et}中,多个回合汇聚(当到达终止状态时,回合的结束发生)到回放内存。在算法的内循环中,我们将Q学习更新或小批量更新应用于经验样本(s, a, r, s') ~ U(D),这些样本是从存储样本池中随机采样的。与标准的在线Q学习相比,此方法具有多个优势。首先,经验的每个步骤都可能用于许多权重更新,这可以提高数据效率。其次,由于样本之间的相关性强,因此直接从连续样本中学习是无效的。 将样本随机化会破坏这些相关性,因此会减少更新的方差。第三,当学习策略时,当前参数确定训练参数的下一个数据样本。 例如,如果最大化动作是向左移动,则训练样本将由左侧样本控制; 如果最大化动作然后切换到右侧,则训练分布也将切换。很容易看出可能会出现有害的反馈循环,并且参数可能陷入极小的局部最小值中,甚至发生灾难性的变化。通过经验回放,行为分布可以在其以前的许多状态中进行平均,从而可以平滑学习过程并避免参数出现振荡或发散。请注意,在通过经验回放进行学习时,有必要进行异策学习(因为我们当前的参数与用于生成样本的参数不同),这激发了选择Q学习的动机。
实际上,我们的算法仅将最近的N个经验元组存储在回放内存中,并在执行更新时从D中随机采样。这种方法在某些方面受到限制,因为内存缓存不能区分重要的转换,并且由于有限的内存大小N而总是用最近的转换覆盖。类似地,均匀采样对回放内存中的所有转换都同样重要。可能会强调我们可以从中学到最多的转换,类似于优先扫描。

四、Prioritized Experience Replay(ICLR 2016)
1 Introduction
经验回放(Lin, 1992)解决了这两个问题:将经验存储在回放内存中,可以通过混合越来越多的用于更新的最近经验来打破时间相关性,而罕见的经验将不仅仅用于一次更新。深度Q网络(DQN)算法(Mnih et al., 2013; 2015)证明了这一点,该算法通过使用经验回放来稳定以深度神经网络为代表的价值函数的训练。具体来说,DQN使用了一个大的滑动窗口回放内存,从中随机采样均匀地对其进行采样,然后平均重访每个转换八次。通常,经验回放可以减少学习所需的经验,而可以用更多的计算和内存来代替,这些资源通常比RL智能体与其环境的交互要便宜。
在本文中,我们研究了优先回放哪些转换会比均匀回放所有转换更加有效。关键思想是,RL智能体可以通过某些转换更有效地学习。转换可能或多或少令人惊讶,冗余或与任务相关。某些转换对智能体可能不是立即有用的,但当智能体能力增强时可能会变得有用(Schmidhuber, 1991)。经验回放将在线学习智能体从完全按照经历顺序处理转换中解放出来。优先回放进一步将智能体从以相同频率考虑转换中解放出来。
尤其是,我们提出更频繁地回放具有较高期望学习进度的转换,以其TD误差的大小来衡量。这种优先次序可能会导致多样性的丧失,而我们通过随机优先次序来缓解多样性,并引入偏差,这可以通过重要性采样进行纠正。
2 Background
大量的神经科学研究已经找到了在啮齿动物海马体中经验回放的证据,这表明在清醒的休息或睡眠过程中都会回放先前经验序列。与奖励相关的序列似乎更频繁地回放(Atherton et al., 2015;Ólafsdóttir et al., 2015;Foster&Wilson, 2006)。高TD误差的经验似乎也经常被回放(Singer&Frank, 2009;McNamara et al., 2014)。
众所周知,通过按适当的顺序对更新进行优先级排序,可以使诸如价值迭代之类的计划算法更加有效。优先扫描(Moore&Atkeson, 1993;Andre et al., 1998)选择下一个要更新的状态,如果执行了该更新,则根据价值的变化进行优先选择。TD误差提供了一种衡量这些优先级的方法(van Seijen&Sutton, 2013)。我们的方法使用了类似的优先级排序方法,但是用于无模型的RL,而不是基于模型的计划。此外,当从样本中学习函数近似时,我们使用鲁棒性更高的随机优先级。
TD误差也已被用作确定资源集中于何处的优先机制,例如在选择要探索的地方时(White et al., 2014)或选择待选特征时(Geramifard et al., 2011;Sun et al., 2011)。
在监督学习中,有许多技术可以在已知类标识时处理不平衡数据集,包括重采样,欠采样和过采样技术,可能与集成方法结合使用(有关综述,请参见Galar et al., 2012)。最近的一篇论文介绍了在具有经验回放的深度RL的背景下进行重采样的方式(Narasimhan et al., 2015);该方法将经验分成两个部分,一个用于正奖励,一个用于负奖励,然后从每个中选择一个固定的划分进行回放。这仅适用于(不同于我们的)拥有"正/负"经验的自然概念的领域。此外,Hinton (2007)引入了一种基于误差的非均匀采样形式,并进行了重要性采样校正,从而使MNIST数字分类的速度提高了3倍。
3.2 Prioritized with TD-error
优先回放的中心部分是用来衡量每个转换的重要性的标准。一个理想的标准是RL智能体可以从其当前状态的转换(期望学习进度)中学习的量。虽然无法直接获得此度量,但合理的替代是转换的TD误差δ,它表明转换有多"令人惊讶"或出乎意料:具体而言,该价值与其下一步自举估计的差距有多大(Andre et al., 1998)。这特别适用于增量在线RL算法(例如SARSA或Q学习),这些算法已经计算出TD误差并按δ的比例更新参数。在某些情况下,TD误差也可能是错误的估计(例如,当奖励带噪时)。有关替代方法的讨论,请参见附录A。
为了证明利用TD误差进行优先回放的潜在有效性,我们将Blind Cliffwalk中的统一oracle基准与"贪婪TD误差优先级"算法进行了比较。该算法将最后遇到的TD误差以及每个转换存储在回放内存中。具有最大绝对TD误差的转换从内存中回放。Q学习更新应用于此转换,该更新与TD误差成比例地更新权重。新的转换不会出现已知的TD误差,因此我们将其设置为最高优先级,以确保看到所有经验至少一次。该算法大大减少了解决Blind Cliffwalk任务所需的工作量。
3.3 Stochastic Prioritization
但是,贪婪TD误差优先级有几个问题。首先,为避免对整个回放内存进行昂贵的扫描,仅针对回放的转换更新TD误差。作为结果,第一次访问时TD误差较低的转换可能不会长时间回放(这意味着从不使用滑动窗口回放内存永远不会回放)。此外,它对带噪脉冲敏感(例如,当奖励是随机时),这种噪声会因自举而加剧,在这种情况下,近似误差似乎是另一种噪声源。最后,贪婪优先级集中在经验的一小部分:误差缓慢缩小,尤其是在使用函数近似时,这意味着最初的高误差转换频繁回放。缺乏多样性使系统易于过拟合。
为了克服这些问题,我们引入了一种随机采样方法,该方法在纯贪婪优先级和均匀随机采样之间进行插值。我们确保采样的概率在转换的优先级中是单调的,同时即使对于最低优先级的转换,也要保证非零概率。具体来说,我们将采样转换 i 的概率定义为:
![]()
其中pi > 0是转换 i 的优先级。指数α确定使用多少优先级,其中α = 0对应于均匀情况。
我们考虑的第一个变体是直接且按比例的优先级排序,其中pi = |δi| + ε,其中ε是一个小的正常数,这可以防止一旦其误差为零,就不会重新考虑转换的边缘情况。第二种变体是基于次序的间接优先级排序,其中![]() ,其中rank(i)是当根据|δi|对回放内存进行排序时转换 i 的次序。在这种情况下,P变为具有指数α的幂分布。两种分布在|δ|中都是单调的,但是后者可能更鲁棒,因为它对异常值不敏感。随机优先级的这两种变体都会导致在Cliffwalk任务上的速度大幅超过统一基准。
,其中rank(i)是当根据|δi|对回放内存进行排序时转换 i 的次序。在这种情况下,P变为具有指数α的幂分布。两种分布在|δ|中都是单调的,但是后者可能更鲁棒,因为它对异常值不敏感。随机优先级的这两种变体都会导致在Cliffwalk任务上的速度大幅超过统一基准。
3.4 Annealing the Bias
具有随机更新的期望价值估计依赖于那些与期望相同分布的更新。优先回放会引入偏差,因为它会以不受控制的方式更改此分布,因此这会更改估计将收敛到的解决方案(即使策略和状态分布是固定的)。我们可以使用重要性采样(IS)权重来纠正这种偏差:
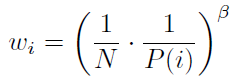
如果β = 1,这可以完全补偿非均匀概率P(i)。这些权重可以通过使用wiδi而不是δi折入Q学习更新中(因此这是加权IS,而不是普通IS,请参见例如Mahmood et al., 2014)。出于稳定性的原因,我们始终将权重归一化为1/maxi wi,以便它们仅向下缩放更新。
在典型的RL场景中,更新的无偏差性质在训练结束时接近收敛是最重要的,因为由于策略,状态分布和自举目标的改变,该过程还是非常不稳定的。我们假设在这种情况下可以忽略小的偏差。因此,我们通过对仅在学习结束时达到1的指数β定义时间表来利用随时间进行重要性采样校正量退火的灵活性。实际上,我们对β从初始值β0到1进行线性退火。请注意,此超参数的选择与优先级指数α的选择相互作用;同时增加两者将优先考虑更积极地采样,同时对其进行更强地校正。
当非线性函数近似(例如深度神经网络)与优先回放结合使用时,重要性采样还有另一个好处:这里的大步长可能是非常破坏性的,因为梯度的一阶近似仅在局部可靠,并且必须通过较小的全局步长来防止。取而代之的是,在我们的方法中,确定优先级可确保多次看到高误差转换,而IS校正可减小梯度幅度(从而减小参数空间中的有效步长),并允许算法遵循高度非线性优化图的曲率,因为泰勒展开式不断被重新近似。
我们基于最新的双重DQN算法,将优先回放算法结合到了全尺度的RL智能体中。我们的主要修改是用我们的随机优先级和重要性采样方法(请参阅算法1)代替双重DQN使用的均匀随机采样。

4 Atari Experiments
对于本文而言,这些基准中最相关的部分是回放机制:所有经历的转换都存储在滑动窗口内存中,该内存保留了最后106个转换。该算法处理从内存中均匀采样的小批量(大小为32)的转换。每次进入内存的4个新转换都会进行一次小批量更新,因此所有经验平均要回放8次。出于稳定性原因,奖励和TD误差被限制在[-1, 1]中。
与基准相比,仅需进行一次超参数调整:鉴于优先回放更频繁地选择高误差转换,典型的梯度幅度越大,因此与(双重)DQN相比,我们将步长η减小了4倍。对于优先级引入的超参数α和β0,我们进行了粗略网格搜索(对8个游戏的子集进行了评估),发现基于次序的变体的最优点是α = 0.7,β0 = 0.5;对于比例变体,α = 0.6,β0 = 0.4。这些选择是在积极性与鲁棒性之间的权衡,但是通过减少α和/或增加β,很容易恢复为接近基准的行为。
优先回放可以提高几乎所有游戏的性能,总体而言,学习速度是之前的两倍。
5 Discussion
在基于次序的优先级和比例优先级之间的正面对比中,我们期望基于次序的变体更加鲁棒,因为它不受异常值和误差幅度的影响。此外,其heavy-tail特性还保证了样本的多样性,并且在整个训练过程中,来自具有不同误差划分的分层采样将使总的小批量梯度保持稳定的大小。另一方面,次序使算法对相对误差量视而不见,当要利用的误差分布中存在结构时,例如在稀疏奖励方案中,这可能导致性能下降。也许令人惊讶的是,两种变体在实践中的性能相似。我们怀疑这是由于DQN算法大量使用了限幅(奖励和TD错误),从而消除了异常值。监视TD误差随时间变化的分布,发现随着学习的进行,TD误差的分布已接近heavy-tailed分布,而各游戏之间的差异仍然很大;这从经验上验证了等式1的形式。
在进行此分析时,我们偶然发现了另一种现象(回想起来很明显),即某些访问的转换在从滑动窗口内存中退出之前从未回放过,而更多的转换是在它们遇到的很久之后才第一次回放。此外,均匀采样隐式偏向于由策略生成的过时转换,该策略从那以后通常已经看到数十万次更新。带有针对未见过的转换提供奖励的优先回放可以直接纠正这些问题中的第一个,并且由于最近的转换往往会产生更大的误差,因此也倾向于帮助解决第二个问题——这是因为旧的转换将有更多的机会来纠正它们 ,并且新数据往往难以通过价值函数进行预测。
我们假设深度神经网络以另一种有趣的方式与优先回放交互。当我们区分学习给定表示(即顶层)的价值和学习改进的表示(即底层)的价值时,表示良好的转换将迅速减少其误差,然后减少回放,将学习重点放在表示较差的其他转换上,从而将更多资源用于区分混叠状态——如果观察和网络容量允许的话。
6 Extensions
Off-policy Replay: 异策RL的两种标准方法是拒绝采样和使用重要性采样率ρ来纠正同策转换的可能性。我们的方法包含这两种方法的类似物,即回放率P和IS校正w。因此,如果在回放内存中有转换,则将其应用于异策RL很自然。特别是,在比例变体中,我们用w = ρ,α = 0,β = 1恢复加权IS,并以p = min(1; ρ),α = 1,β = 0拒绝采样。我们的实验表明,中间变体(可能带有退火或次序)在实践中可能更有用——尤其是当IS比率引入高方差时,即当感兴趣的策略与某些状态的行为策略有很大不同时。当然,异策修正是对基于期望学习进度的优先级的补充,并且可以通过定义p = ρ · |δ|或基于ρ和δ两者的其他合理权衡,将相同框架用于混合优先级。
Feedback for Exploration: 优先回放的一个有趣的副作用是,最终将被回放的转换总数Mi千差万别,这大致表明了它对智能体的有用性。该潜在有价值的信号可以反馈给生成转换的探索策略。例如,我们可以在每个回合开始时从参数化分布中采样探索超参数(例如随机动作的概率ε,玻尔兹曼温度或要混合的内在奖励的数量),以通过Mi监控经验的有用性,并更新分布以产生更多有用的经验。或者,在像Gorila智能体(Nair et al., 2015)这样的并行系统中,它可以指导同时存在但异构的"执行者"集合之间的资源分配,每个执行者都有不同的探索超参数。
Prioritized Memories: 帮助确定要回放的转换的考虑因素也可能与确定存储哪些内存以及何时擦除它们有关(例如,何时不再可能回放它们)。显式控制要保留或擦除的内存可以帮助减少所需的总内存大小,因为它可以减少冗余(频繁访问的转换误差低,因此很多转换将被丢弃),同时自动调整已学到的知识(删除许多"简单"转换)并将内存的内容偏向误差很高的地方。这是不平凡的方面,因为DQN的内存需求当前由回放内存的大小控制,而不再由神经网络的大小控制。与降低回放率相比,擦除是一个更最终的决定,因此,可能需要更加强调多样性,例如,通过跟踪每个过程的年龄并使用它来调整优先级,从而保留足够的旧经验以防止循环(与多智能体文献中的"名人堂"思想有关,Rosin&Belew, 1997)。优先级机制也足够灵活,可以整合来自其他来源的经验,例如来自计划者或人类专家轨迹的经验(Guo et al., 2014),因为知道来源可用于调整每个转换的优先级,例如以某种方式在内存中保留足够比例的外部经验。
A Prioritization Variants
绝对TD误差只是期望学习进度的理想优先级度量的一种可能替代。尽管它捕获了潜在改进的规模,却忽略了奖励或转换中固有的随机性,以及部分可观察性或FA容量可能造成的限制;换句话说,当存在无法学习的转换时,这是有问题的。在这种情况下,其导数(可能可以用转换的当前|δ|与上次回放时的|δ|之差来近似)可能会更有用。但是,此度量不太立即可用,并且受同时回放的内容的影响,这增加了其方差。在初步的实验中,我们发现它的性能并没有优于|δ|,但这可能更多地说明了我们研究的(近似确定的)环境的类别,而不是衡量指标本身。
正交变体将考虑回放转换引起的权重变化的范数——如果基础优化器采用自适应步长可减少高噪声方向上的梯度,则此方法会很有效(Schaul et al., 2013;Kingma& Ba, 2014),因此将区分可学习和不可学习转换的负担放在优化器上。
通过将正TD误差与负TD误差区别对待,可以调整优先级。例如,我们可以援引Anna Karenina原理(Diamond, 1994),该原理被解释为意味着,在许多情况下,转换可能不如期望的好,但只有其中一种可能更好,以引入不对称并优先考虑正TD误差(与同等程度的负误差相比),因为前者更有可能提供丰富的信息。在大鼠研究中也观察到这种回放率的不对称性(Singer&Frank, 2009)。同样,我们对此类变体的初步实验尚无定论。
神经科学的证据表明,基于回合回报而不是期望学习进度的优先级排序也可能有用(Atherton et al., 2015;Ólafsdóttir et al., 2015;Foster&Wilson, 2006)。对于这种情况,我们可以提高整个回合(而不是转换)的回放率,或者通过观察到的return-to-go(甚至是其价值估计)来提高单个转换。
对于保留足够的多样性(防止过拟合,过早收敛或表示不当)的问题,我们选择引入随机性有其他解决方案,例如,可以通过观察空间中的新颖性措施来调整优先级。没有什么能阻止一种混合方法,其中(每个小批量处理的)一部分元素是根据一种优先级度量进行采样的,而其余元素则是根据另一种优先度量进行采样的,从而引入了额外的多样性。一个正交的想法是通过引入显式的陈旧性奖励来增加一段时间未回放的转换的优先级,以确保不时重新审视每个转换,并且以与上次出现的TD误差相同的速度增加的机会变得陈旧。在这种奖励随时间线性增长的简单情况下,可以通过在任何更新中从新优先级中减去与全局步骤数成比例的量来实现这一目标,而无需任何额外成本。
在RL带有价值函数自举的特殊情况下,可以使用以下直觉来利用回放内存的顺序结构:导致大量学习(关于其传出状态)的转换有可能更改导致该状态的所有转换的自举目标,因此有更多的知识要学习。当然,我们至少知道其中之一,即历史的前导转换,因此提高优先级使其有可能很快被重新审视。与资格迹类似,这可以使信息从未来的结果反向缓慢移动到导致结果的动作和状态的价值估计。实际上,我们将当前转换的|δ|添加到先前转换的优先级中,但前提是先前转换不是终止转换。这个想法与在啮齿动物(Foster&Wilson, 2006)中观察到的"反向回放"有关,并且与优先扫描的最新扩展有关(van Seijen&Sutton, 2013)。
五、Language Understanding for Text-based Games using Deep Reinforcement Learning(EMNLP 2015)
从经验内存D创建这些小批量的最简单方法是均匀随机采样。但是,某些经验比其他经验更有价值,可供智能体学习。例如,提供正奖励的罕见转换可以更经常地用于更快地学习最优Q值。在我们的实验中,我们认为此类正奖励转换具有更高的优先级,并在D中对其进行跟踪。我们使用优先采样(由Moore and Atkeson (1993)启发)从较高优先级的池中采样比例为ρ的转换,其余转换的采样比例为1-ρ。
对于优先采样,我们对两个世界使用ρ = 0.25。

六、Distributed Prioritized Experience Repaly(ICLR 2018)
1 Introduction
在本文中,我们描述了一种通过生成更多数据并以优先方式从中选择来扩展深度RL的方法(Schaul et al., 2016)。神经网络分布式训练的标准方法着重于并行化梯度的计算,以更快速地优化参数(Dean et al., 2012)。相反,我们分配了经验数据的生成和选择,发现仅此一项就可以改进结果。这是对分布式梯度计算的补充,可以将这两种方法结合起来,但是在这项工作中,我们仅专注于数据生成。
我们根据经验调查了框架的可伸缩性,分析了优先级如何在增加数据生成工作者的数量时影响性能。我们的实验包括对诸如回放容量,经验的新近性以及对不同工作者使用不同数据生成策略等因素的分析。最后,我们讨论了可能适用于我们分布式框架之外的深度RL智能体的含义。
2 Background
Prioritized Experience Replay 经验回放(Lin, 1992)长期用于RL以提高数据效率。当使用随机梯度下降算法训练神经网络函数近似时,如在神经拟合Q迭代(Riedmiller, 2005)和深度Q学习(Mnih et al., 2015)中,此方法特别有用。经验回放还可以通过允许智能体从策略的早期版本生成的数据中学习来帮助防止过拟合。优先经验回放(Schaul et al., 2016)扩展了经典的优先扫描概念(Moore&Atkeson, 1993),以与深度神经网络函数近似一起使用。该方法与上一节中讨论的重要性采样技术密切相关,但是使用了更普遍的一类有偏的采样过程,这些过程将学习重点放在最"令人惊讶"的经验上。有偏采样在RL中特别有用,因为奖励信号可能稀疏并且数据分布取决于智能体的策略。作为结果,在许多智能体中使用了优先经验回放。在一项消融研究中,研究了几种算法成分的相对重要性(Hessel et al., 2017),发现优先级是影响智能体性能的最重要成分。
3 Our Contribution: Distributed Prioritized Experience Replay
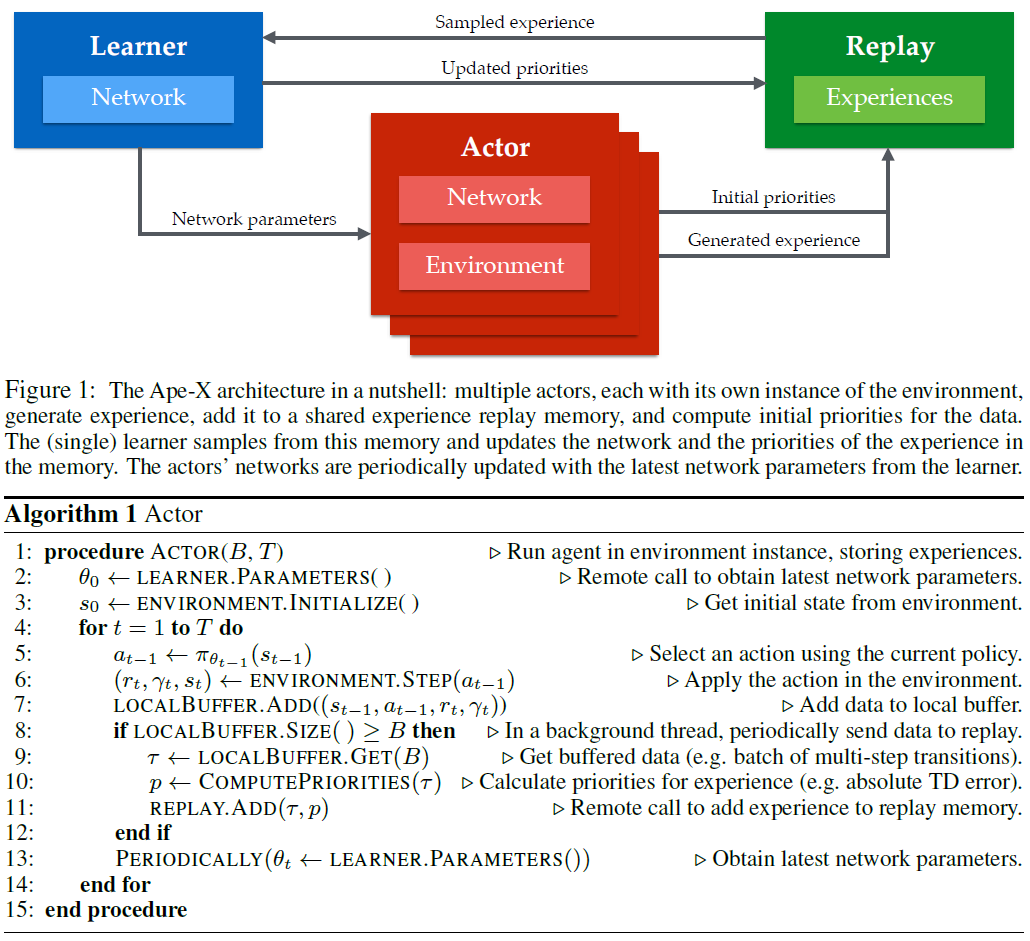
在本文中,我们将优先经验回放扩展到分布式环境,并表明这是深度RL的高度可扩展方法。我们介绍了实现此可伸缩性的一些关键修改,并将我们的方法称为Ape-X。

七、Revisiting Fundamentals of Experience Replay (ICML 2020)
参考链接:https://www.cnblogs.com/lucifer1997/p/13525276.html
经验回放对于深度RL中的异策算法至关重要,但是在我们的理解上仍然存在很大差距。因此,我们对Q学习方法中的经验回放进行了系统且广泛的分析,重点是两个基本属性:回放容量和学习更新与所收集经验的比率(回放率)。我们的加性和消融研究颠覆了有关经验回放的传统观点——更大的容量被发现可以显著提高某些算法的性能,而不会影响其他算法。与直觉相反,我们表明,理论上没有根据且未经校正的n步回报是唯一有益的,而其他技术则对于通过更大的内存进行筛选提供了有限的好处。另外,通过直接控制回放率,我们可以结合文献中的先前观察结果,并通过经验来衡量其在三种深度RL算法中的重要性。最后,我们通过测试关于这些性能优势的性质的一组假设来得出结论。
八、Prioritized Sequence Experience Replay(Arxiv 2020)
1. Introduction
在游戏环境中,获得经验的成本相当低廉,但是对现实世界中控制任务的试验通常涉及我们不希望浪费的时间和资源。另外,由于系统的磨损,试验次数可能会受到限制,从而使数据效率变得至关重要(Gal, 2016)。在这些情况下,无法进行仿真或获取样本需要大量的时间或成本,因此有必要更有效地利用获取的数据来更好地进行推广。
作为深度RL算法的重要组成部分,经验回放已被证明可以提供不相关的数据来训练神经网络并显著提高数据效率(Lin, 1992;Wang et al., 2016a;Zhang&Sutton, 2017)。一般而言,经验回放可以减少学习所需的经验量,但会消耗更多的计算和内存(Schaul et al., 2016)。
有多种采样策略可以从经验回放内存中采样转换。经验回放内存的最初主要目的是对传递到神经网络的输入进行去相关,因此最初的采样策略是均匀采样。优先经验回放(PER)(Schaul et al., 2016)证明了智能体可以从某些转换中学习到比其他转换更有效的学习。通过在每个训练步骤中更频繁地对回放内存中的重要转换进行采样,PER使经验回放比均匀采样更加有效。
在本文中,我们提出了对PER的扩展,我们将其称为优先序列经验回放(PSER),它不仅为重要的转换分配了高采样优先级,而且还增加了产生重要转换的前导转换的优先级。
2.2. Experience Replay
经验回放在为深度RL算法的在线神经网络训练提供不相关数据方面发挥了重要作用(Mnih et al., 2015;Lillicrap et al., 2015),还研究了经验回放如何影响深度RL算法的性能(de Bruin et al., 2015;Zhang&Sutton, 2017)。
在DQN的经验回放中,将观察序列存储在回放内存中,并进行均匀采样以训练神经网络,以便删除数据中的相关性。但是,这种均匀采样策略忽略了每个转换的重要性,并且显示出学习效率低下(Schaul et al., 2016)。
众所周知,通过按适当的顺序对更新进行优先级排序,可以使基于模型的计划算法(例如价值迭代)更加高效。基于此思想,优先扫描被提出(Moore&Atkeson, 1993;Andre et al., 1998)来更新具有最大Bellman误差的状态,从而可以加快基于状态且紧凑的(使用函数近似)模型与价值函数的表示形式。类似于优先扫描,优先经验回放(PER)(Schaul et al., 2016)基于无模型的深度RL算法中的TD误差(Sutton&Barto, 1998),为经验回放内存中的每个转换分配优先级,与来自经验回放内存的均匀采样相比,这被证明可以极大地提高学习效率。还有其他一些提出的方法试图提高深度RL算法的样本效率。Lee et al. (2018)提出了一种采样技术,可以从整个回合反向更新转换。Karimpanal&Bouffanais (2018)提出了一种选择合适的转换序列以加速学习的方法。
Zhong et al. (2017)在最近的另一项研究中,作者调查了反向传播奖励刺激对先前转换的使用。在我们的工作中,我们遵循Schaul et al. (2016)提出的方法。通过使用当前TD误差作为优先级信号提供一种更通用的方法,并介绍了我们认为对最大化性能至关重要的技术。
本文提出的方法是PER的扩展。在为回放内存中的转换分配优先级的同时,我们还以有效的方式将此优先级信息传播到了先前的转换,而Atari 2600基准测试的实验结果表明,我们的算法在PER采样上得到了显著改进。
3.2. Prioritized sequence decay
在本小节中,我们正式定义了优先序列的概念,并在回放内存中随时间反向递减优先级。
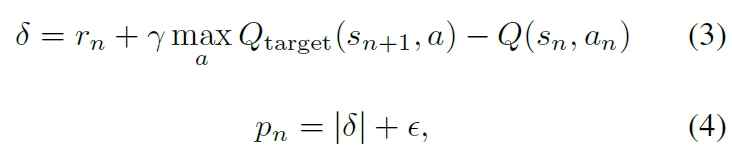

我们将优先级指数(使用衰减系数ρ)衰减到该回合的回放内存中存储的先前转换,并应用max运算符以努力保留分配给该衰减后的转换的任何先前优先级:

我们将此衰减策略称为MAX变体。衰减优先级的另一种可能方法是简单地将衰减后的优先级pn · ρi与先前分配给该转换的优先级pn-i相加。我们将其称为ADD变体。请注意,在ADD变体中,当反向衰减优先级时,我们将优先级保持为小于最大优先级,以避免出现溢出问题。
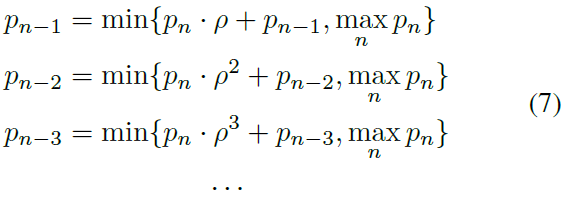
图4说明了这种情况,其中计算了转换T7处的优先级衰减,然后在转换T13处发生了另一个优先级衰减。如果未应用max运算符,回放内存中转换T7的优先级p7将设置为ρ · p8,其中p8是转换T8的优先级。
在这里,我们注意到随着优先级的衰减,我们期望经过一定数量的更新后,衰减后的优先级pn-k可以忽略不计,因此浪费了计算量。因此,我们定义了一个大小为W的窗口,在该窗口上我们将允许优先级pn进行衰减,此后我们将停止。当衰减后的优先级可以忽略不计时,我们任意选择一个pn的1%作为截止阈值。然后,我们根据超参数ρ的值计算窗口大小W,如下所示:
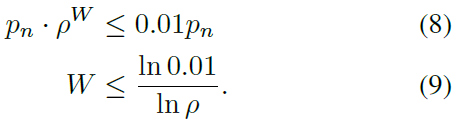
通过以上针对PSER的公式,我们确定了一个在衰减过程中称为"优先级崩溃"的问题。假设对于给定的环境,PSER已经对"令人惊讶的"转换(我们称为Ti)反向衰减优先级。假设当前所有Q值均为0,并且我们在回放内存Ti-2中采样了一个产生Ti的转换。从等式3和等式4,转换Ti-2的优先级将降至ε。作为结果,最近衰减的优先级序列几乎没有影响,因为几乎可以保证在下一次采样时将其消除。当这发生在多个状态时,我们称之为"优先级崩溃",并且消除了PSER的潜在好处,使其几乎等同于传统的PER。
为了防止这种灾难性的"优先级崩溃",我们设计了一个参数,该参数迫使优先级缓慢降低。在回放内存中更新采样转换的优先级时,我们希望保留其先前优先级的一部分,以防止其降低得太快:
![]()
其中 i 在这里指的是回放内存中采样转换的索引。没有此衰减参数,我们通过实验发现PSER与PER相比没有明显的好处,这证实了我们的直觉。
我们的信念是,衰减参数η为Bellman更新过程提供了时间,以通过该序列传播有关TD误差的信息,并为神经网络提供了更容易地学习适当的Q值近似的时间。

5.3. Ablation Study
为了弄清分配给转换的初始优先级如何与优先采样相互作用,我们进行了额外的实验以评估性能。
我们在消融研究中考虑了两种初始优先级分配方法。首先,在Mnih et al. (2015);Van Hasselt et al. (2016);Hessel et al. (2018)中,转换会以已经见过的最大优先级添加到回放内存中。第二,在Horgan et al. (2018)中,转换的优先级是根据在线模型的当前TD误差计算得出的。我们分别将这两个变体称为MaxPrio和CurrentTD。
6. Discussion
我们已经证明,PSER通过Blind Cliffwalk环境和Atari 2600基准可大幅提高性能。
在执行此分析时,我们测试了PSER的不同配置,并发现了我们没有想到的现象。最重要的是第3.2节中描述的优先级崩溃问题。通过引入参数η以保留转换的先前优先级的一部分,我们可以防止PSER创建的更改后的优先级快速恢复为PER分配的优先级。我们认为深度RL固有两个过程:所有RL和马尔可夫决策过程固有的Bellman更新过程,以及神经网络梯度下降更新过程。这两个过程都很慢,并且需要许多样本才能收敛。我们假设在回放内存中保持先前转换的优先级升高会导致该序列的Bellman更新,并包含有价值的信息。虽然这可以加快Bellman更新过程的速度,但它还可以为神经网络提供更好的目标,从而提高总体收敛速度。
在Atari 2600基准上进行实验时,我们需要选择固定的超参数集,以便在PSER和PER之间进行合理的比较。但是,Atari 2600基准中的游戏在获得奖励的方式以及动作和奖励之间的延迟时间方面有所不同。即使我们使用固定的衰减窗口相对于PER有了实质性的改进,但允许衰减窗口随每个游戏而变化可能会带来更好的性能。一种方法是根据TD误差的大小引入自适应衰减窗口。我们将自适应衰减窗口的研究留给以后的工作。
将新的转换添加到回放内存时,是否应该使用MaxPrio或CurrentTD初始优先级分配仍不清楚。对于Blind Cliff Walk实验,我们发现与CurrentTD相比,MaxPrio方法将收敛延迟到了真实的Q值。但是,在Atari上,我们发现MaxPrio方法更有效。直观地讲,将具有当前TD误差的转换添加到回放内存中是有道理的,可以鼓励智能体程序尽快对这些高优先级转换进行采样。对于大多数新转换,以最大优先级进行添加将导致人为地具有较高的优先级。我们假设这可能与优先级崩溃问题有关,在优先级崩溃问题中,这些人为的高优先级在学习过程中暂时允许更好的信息流。
我们选择在DQN之上实现PSER,主要是为了在实验中可以对PER和PSER进行公平的比较,但是将PSER与其他算法结合起来是未来工作的有趣方向。例如,PSER也可以与其他异策算法一起使用,例如双重Q学习和Rainbow。

九、Recurrent Experience Replay in Distributed Reinforcement Learning(ICLR 2019)
blog:https://blog.csdn.net/qq_29176963/article/details/106907958
基于RL智能体分布式训练的最新成功经验,本文从分布式优先经验回放中研究基于RNN的RL智能体的训练。我们研究了参数滞后对表征漂移和循环状态陈旧性的影响,并凭经验得出了一种改进的训练策略。使用单个网络结构和一组固定的超参数,生成的智能体程序Recurrent Replay Distributed DQN将Atari-57上的最先进水平提高了四倍,并可以媲美DMLab-30上的最先进水平。它是第一个在57款Atari游戏中有52款性能指标超过人类水平的智能体。
十、Hindsight Experience Replay(NIPS 2017)
arxiv:https://arxiv.org/abs/1707.01495v1
blog:https://zhuanlan.zhihu.com/p/34309324;https://www.jianshu.com/p/4c7b52d4d578;https://zhuanlan.zhihu.com/p/98659017

