郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!


Plos Computational Biology, 2013
Abstract
动物会重复奖励的行为,但基于奖励的学习的生理基础仅得到了部分阐明。一方面,实验证据表明神经调节剂多巴胺携带有关奖励的信息并影响突触可塑性。另一方面,RL理论为基于奖励的学习提供了框架。奖励调节的脉冲时序依赖可塑性(R-STDP)的最新模型已迈出了弥合两种方法之间差距的第一步,但仍面临两个问题。首先,RL通常是在不适合自然情况描述的离散框架中制定的。其次,生物学合理的R-STDP模型需要精确计算奖励预测误差,但神经元如何计算该价值仍有待证明。在此,我们通过将Doya (2000)的连续时序差分(TD)学习扩展到以连续时间操作的具有连续状态和动作表征的actor-critic网络中脉冲神经元的情况,以提出这些问题的解决方案。在我们的模型中,critic学会了实时预测期望未来奖励。它的活动以及实际奖励,决定了向其自身和actor传递神经调节性TD信号的能力,而后者负责选择动作。在仿真中,我们通过许多与报道的动物表现相符的试验,证明了这种架构可以解决类似Morris水迷宫般的导航任务。我们还使用我们的模型来解决Acrobot和Cartpole问题这两个复杂的运动控制任务。我们的模型提供了一种计算大脑奖励预测误差的合理方法。此外,从分析得出的学习规则与多巴胺调节的STDP的实验证据是一致的。
Author Summary
每只狗的主人都知道,动物会重复能够获得奖励的行为。但是,基于奖励的学习所基于的大脑机制是什么?实验研究指出,神经元之间的突触连接具有可塑性,神经调节剂多巴胺起着重要作用,但是在学习过程中突触活动和神经调节之间相互作用的确切方式尚不清楚。在这里,我们提出一个模型,解释奖励信号如何与突触可塑性相互作用,并使用该模型解决仿真的迷宫导航任务。我们的模型从RL理论中扩展了一个概念:一组神经元形成一个"actor",负责选择动物的运动方向。另一组神经元,即"critic",其作用是预测智能体将获得的奖励,它利用实际奖励与期望奖励之间的不匹配来指导两组输入的突触。我们的学习智能体学会可靠地走迷宫,以找到奖励。值得注意的是,我们从理论考虑中得出的突触学习规则与基于实验证据的先前规则相似。
Introduction
动物行为学习的许多实例,例如觅食中的寻路,或者Morris水迷宫导航(一个更加人工的例子),可以解释为探索和试错学习。在两个例子中,动物最终学会的行为都是导致高奖励的行为。这些可以是食欲奖励(即食物)或更间接的奖励,例如在水迷宫中寻找平台的解救。
在了解如何在哺乳动物的大脑中学习这种行为方面已取得重要进展。一方面,RL框架[1]为稀疏奖励事件的学习提供了一种理论和算法。RL的一种特别吸引人的形式是TD学习[2]。在标准设置中,该理论假设智能体通过在离散时间步骤中选择适当的动作来在其环境中的状态之间移动。奖励是在状态和动作的某些结合中给出的,智能体的目的是选择其动作,以最大化其所获得的奖励。已经开发了几种算法来解决该问题的标准格式,其中一些算法已与SNN一起使用。这些包括REINFORCE [3,4]和部分可观察的Markov决策过程[5,6],以防智能体对自己的状态不完全了解。
另一方面,实验表明,当发生奖励或奖励预测事件时,与愉悦相关的神经递质多巴胺会释放到大脑中[7]。多巴胺已被证明可以在定时非特定方案中调节可塑性的诱导[8-11]。多巴胺最近还显示出可调节STDP,尽管尚不清楚诱导长期增强(LTP)和长期抑制(LTD)的确切时机和多巴胺的要求[12–14]。
将生物神经网络与RL联系起来的一个关键问题是RL的典型表述依赖于状态,动作和时间的离散描述,而脉冲神经元会在连续时间内自然进化,并且生物学合理的"时间步骤"很难预见。较早的研究表明,可能涉及外部复位[15]或theta振荡[16],但尚无证据支持这一点,并且尚不清楚为什么进化会在连续决策机制中更倾向于较慢的决策步骤。实际上,生物学决策通常是通过连续时间中的整合过程来建模的[17],其中当整合值达到阈值时触发实际决策。
在这项研究中,我们提出了一种方法,可以通过使用状态,动作和时间的连续表征,以及通过得出生物学合理的突触学习规则,来缩小RL模型与脉冲时序依赖的突触学习规则族之间的概念差距。更准确地说,我们使用Actor-Critic结构的一种变体[1,18]进行TD学习。从Doya [19]的连续TD公式开始,我们得出了奖励调节的STDP学习规则,该规则使脉冲神经元模型的网络可以有效地解决导航和运动控制任务,并具有连续状态,动作和时间表征。这可以看作是早期工作的扩展[20,21]到连续动作,连续时间和脉冲神经元。我们证明了这种系统的性能与真实动物相当,并且它为神经调节剂(如多巴胺)的影响提供突触可塑性的新见解。
Results
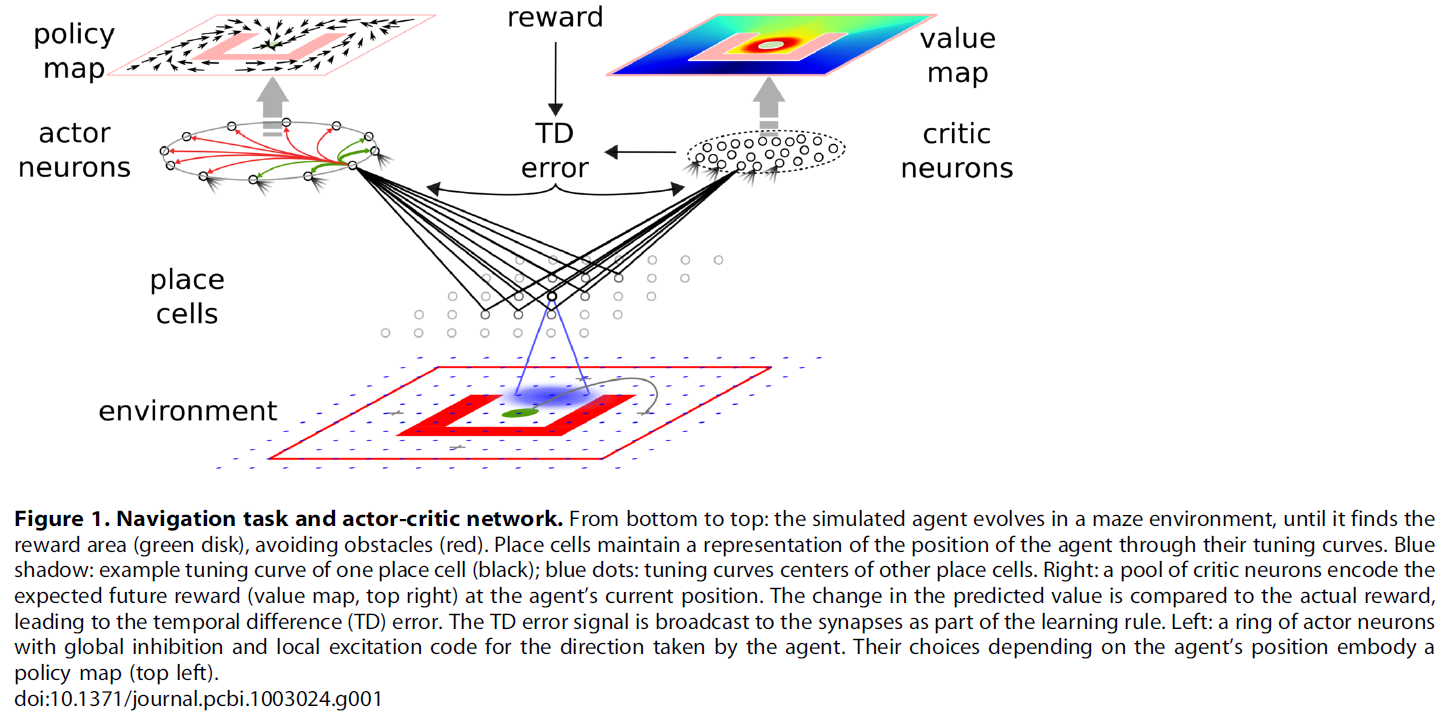
动物如何学会通过迷宫找到自己的路?这种学习和计算基础是什么样的神经回路?它们所依赖的突触可塑性规则是什么?我们通过研究仿真动物(或智能体)如何解决类似于Morris水迷宫的导航任务来解决这些问题。我们的智能体必须在迷宫中导航,寻找一个(隐藏的)平台来触发奖励交付并结束试验。我们假设我们的智能体可以依靠位置单元[22]来表示其在迷宫中的当前位置(图1)。
TD学习方法提供了一种理论,解释了智能体如何与环境互动以最大化其所获得的奖励。TD学习建立在马尔可夫决策过程的形式基础上。接下来,我们将在连续时间,状态和动作下重新构造马尔可夫决策过程的框架,然后转向actor-critic神经网络和用于解决迷宫任务的学习规则。
让我们考虑一个穿越迷宫的学习智能体。我们可以将其在时间 t 的位置描述为![]() ,对应于标准RL框架中状态的连续版本。状态的时间演变由智能体的动作
,对应于标准RL框架中状态的连续版本。状态的时间演变由智能体的动作![]() 决定,如下所示:
决定,如下所示:
![]()
其中 f 描述了环境的动态。在整个本文中,我们使用点符号来表示项相对于时间的导数。
我们将位置单元建模为简单的脉冲过程(非齐次泊松,请参见Models),仅当智能体接近其各自的中心时才会触发。中心排列在网格上,均匀覆盖迷宫的表面。
奖励以奖励率r(x(t), a(t))的形式分配给智能体。在单个位置x0处的局部奖励R0将对应于极限![]() ,其中δD表示狄拉克δ函数。但是,由于任何现实的奖励(例如一块巧克力或在水迷宫中的隐藏平台)都具有有限的范围,因此我们更倾向于使用时序拓展的奖励。在我们的模型中,奖励是基于空间精确的事件来分配的,但奖励交付是时序扩展的(请参见Models)。智能体到达目标平台会受到奖励,而撞到墙壁会受到惩罚(负奖励)。
,其中δD表示狄拉克δ函数。但是,由于任何现实的奖励(例如一块巧克力或在水迷宫中的隐藏平台)都具有有限的范围,因此我们更倾向于使用时序拓展的奖励。在我们的模型中,奖励是基于空间精确的事件来分配的,但奖励交付是时序扩展的(请参见Models)。智能体到达目标平台会受到奖励,而撞到墙壁会受到惩罚(负奖励)。
智能体遵循策略π,该策略确定在状态x下采取动作a的概率:
![]()
智能体的总体目标是找到可以确保长期获得最高奖励的策略π。
已经提出了几种算法来解决上述强化问题的离散版本,例如Q学习[23]或Sarsa [24]。这两个都使用每个状态-动作对的Q值形式的未来奖励表征。然后,将Q值用于评估当前策略(评估问题)和选择下一个动作(控制问题)。正如我们在Models中所显示的,当人们希望在保持生物学合理性的同时转向连续表征时,Q值会带来困难。相反,这里我们使用一种称为"Actor-Critic"[1,8,21]的方法,其中将主体分为两部分:控制问题由actor解决,评估问题由critic解决(图1)。
Results的其余部分结构如下。首先,我们来看看连续时间中的TD形式。接下来,我们展示脉冲神经元如何实现critic,以表示和学习期望未来奖励。第三,我们讨论了脉冲神经元actor,以及它如何代表和学习策略。最后,仿真结果表明我们的网络成功学习了仿真任务。
Continuous TD
RL智能体的目标是最大化其未来奖励。按照Doya [19],我们将连续时间价值函数![]() 定义如下:
定义如下:

其中括号表示对所有未来轨迹xπ以及未来动作选择aπ的期望,这取决于策略π。参数τr表示奖励折扣时间常数,类似于离散RL的折扣因子。它的作用是使不久后的奖励比远期奖励更具吸引力。诸如水迷宫任务之类的任务的τr的典型值约为几秒。公式3表示在时间 t 且遵循策略π的位置x(t)中的智能体可以预期的折扣奖励总和。应该选择策略,以使Vπ(x(t))对于所有位置x都最大化。取公式3关于时间的导数产生自一致性公式(需要注意V是期望未来奖励,随着时间推移,V中原本较远的奖励的折扣率会按比例提升,但需要减去当前步骤的奖励)[19]:
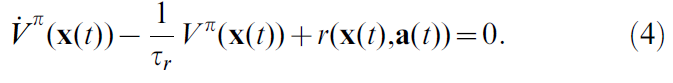
计算Vπ需要了解奖励函数r(x, a)和环境动态 f (公式1)。但是,这些对于智能体是未知的。通常,智能体能做的最好的事情就是维持"真"价值函数Vπ(x(t))的参数估计量V(x(t))。该估计不完美,不能保证满足公式4。相反,TD误差δ(t)被定义为自一致性不匹配:
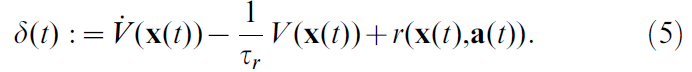
这类似于离散TD误差[1,19]:
![]()
其中奖励折扣因子γ的作用类似于奖励折扣时间常数τr。更准确地说,对于短步骤![]() ,
,![]() (利用洛必达法则或者泰勒展开)[19]。
(利用洛必达法则或者泰勒展开)[19]。
如果对于所有的 t,TD误差δ(t)都接近于零,则估计值V可以说是Vπ的良好近似值。这提出了一种学习价值函数估计器的简单方法:通过以下方式对TD平方误差进行梯度下降:

其中η是学习率参数,且w = (w1, w2, ... , wn)是控制价值函数估计V的一组参数(突触权重)。这种称为残差梯度[19,25,26]的方法产生的学习规则在形式上是正确的,但是在我们的案例中,存在Models中所示的噪声偏差。
相反,我们使用了不同的学习规则,Sutton and Barto[1]针对离散情况提出了建议。在连续框架中进行转换,其优化方法的目的是使价值函数近似值V(x(t))与真实价值函数Vπ(x(t))相匹配。这等效于最小化目标函数:
![]()
E(t)的梯度下降学习规则导出:
![]()
当然,由于Vπ未知,所以这不是特别有用的学习规则。另一方面,使用公式4,这成为:
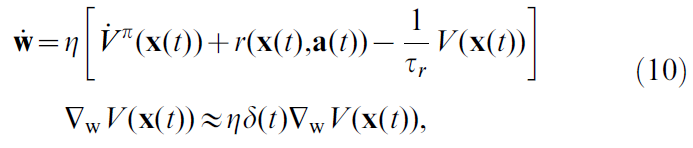
其中我们将1/τr合并到学习率η中(公式10中的η等价于原本公式9中的η乘以τr),而没有通用性的损失。在最后一步中,我们用其估计值的导数替换了真实价值函数导数,即![]() ,然后使用公式5中δ(t)的定义。
,然后使用公式5中δ(t)的定义。
在公式10中用![]() 替换
替换![]() ,这是一个近似值,通常不能保证两个价值相似。但是,所得学习规则的形式表明,它朝着减小TD误差δ(t)的方向发展。例如,如果δ(t)在时间 t 为正,则沿公式10建议的方向更新参数w,这会增加V(t)值,从而减少δ(t)。
,这是一个近似值,通常不能保证两个价值相似。但是,所得学习规则的形式表明,它朝着减小TD误差δ(t)的方向发展。例如,如果δ(t)在时间 t 为正,则沿公式10建议的方向更新参数w,这会增加V(t)值,从而减少δ(t)。
在[19]中,使用启发式捷径直接从残差梯度(公式7)转到公式10。如Doya [19]所述,公式10中学习规则的形式是具有函数近似的离散TD(λ)[1,27]的连续形式(此处λ=0)。即使在无限(但可数)状态空间的情况下,也可以证明它的收敛概率为1 [28,29]。对于任意小的时间步骤(例如,连续系统的计算机仿真中通常使用的有限步骤[19])也必须是这种情况,因此,即使迄今为止尚无证明,在合理的假设下,连续版本也收敛似乎是合理的。
RL中的一个重要问题是时序信度分配的概念,即如何及时传播有关奖励的信息。在TD学习的框架中,这意味着在时间 t 传播TD误差,从而可以更早地更新价值函数。学习规则公式10本身并不能解决这个问题,因为δ(t)的表达式在时间 t 仅显式涉及V和![]() 。因此,δ(t)不会传达有关其他时间
。因此,δ(t)不会传达有关其他时间![]() 的信息,并且最小化δ(t)不会先验影响价值V(x(t′))和
的信息,并且最小化δ(t)不会先验影响价值V(x(t′))和![]() 。这与TD误差的离散版本(公式6)相反,其中δt的表达式显式链接到Vt-1,因此TD误差在随后的学习试验中反向传播。
。这与TD误差的离散版本(公式6)相反,其中δt的表达式显式链接到Vt-1,因此TD误差在随后的学习试验中反向传播。
但是,如果假设价值函数V(t)是连续且连续可微的,则更改V(x(t))和![]() 的值意味着在 t 的有限范围内更改这些函数的值。如果人们对V使用参数化形式,即光滑核的加权混合形式(如我们在此处所做,请参见下一节),则尤其如此。因此,价值函数的函数近似的结合(光滑核的线性组合形式)确保了在连续情况下TD误差δ(t)在时间上得以传播,从而解决了时序信度分配问题。
的值意味着在 t 的有限范围内更改这些函数的值。如果人们对V使用参数化形式,即光滑核的加权混合形式(如我们在此处所做,请参见下一节),则尤其如此。因此,价值函数的函数近似的结合(光滑核的线性组合形式)确保了在连续情况下TD误差δ(t)在时间上得以传播,从而解决了时序信度分配问题。
Spiking Neuron Critic
现在,我们通过假定价值函数估计是由发放率为ρ(t)的脉冲神经元执行的,将上述推导更进一步。一种自然的方式是:
![]()
其中V0是与无脉冲活动对应的价值,v是单位为[奖励单位] x s的比例因子。尽管发放率ρ始终为正,但选择V0 < 0仍可得到负价值V(x)。我们称此神经元为critic神经元,因为它的作用是维持对价值函数V的估计。
此时应讨论几个方面。首先,由于公式11中的价值函数必须取决于智能体的状态x(t),我们必须假设神经元收到一些有关智能体状态的有意义的突触输入。在下文中,我们假设此输入是从位置单元到(脉冲)critic神经元的前馈。
其次,虽然价值函数在理论上仅是时间 t 处状态的函数,但脉冲神经元实现(例如我们在此处使用的简化模型,请参见Models)将以由它获得的兴奋性突触后电位(EPSP)的形状决定的方式反映最近的过去。这是所有处理具有有限突触延迟的感觉输入的神经回路所共有的限制。在本研究的其余部分中,我们假设与EPSP的宽度相比,智能体状态的演化缓慢。在此限制下,critic神经元在时间 t 的发放率实际上反映了该智能体在该时间的位置。
第三,单个脉冲发放神经元的发放率ρ(t)本身是一个模糊的概念,可能有多种定义。让我们从其脉冲序列![]() 开始(其中
开始(其中![]() 是神经元脉冲时间的集合,而δD是Dirac delta,不要与TD信号混淆)。期望
是神经元脉冲时间的集合,而δD是Dirac delta,不要与TD信号混淆)。期望![]() 是多次重复中神经元发放的统计均值。从理论上讲,这是发放率的定义,但实际上,在生物学合理的情况下,单次试验中尚无此定义。相反,常见的解决方法是使用时序均值,例如通过使用核Κ对脉冲序列进行滤波:
是多次重复中神经元发放的统计均值。从理论上讲,这是发放率的定义,但实际上,在生物学合理的情况下,单次试验中尚无此定义。相反,常见的解决方法是使用时序均值,例如通过使用核Κ对脉冲序列进行滤波:
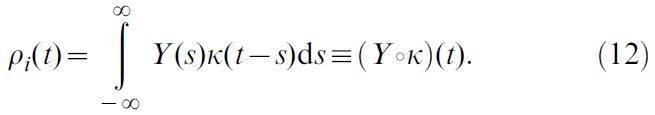
本质上,这相当于在时序精度和发放率函数的平滑度之间进行折衷,其中极端情况分别是脉冲序列Y(极高的时序精度)和具有平滑边界的长时间窗口上简单的脉冲计数(无时序信息,极度平滑)。在选择核K时,应保持![]() ,因此每个脉冲被计数一次,并且人们经常希望核是因果的(
,因此每个脉冲被计数一次,并且人们经常希望核是因果的( ![]() ),因此当前的发放率完全取决于过去的脉冲,并且独立于未来的脉冲。
),因此当前的发放率完全取决于过去的脉冲,并且独立于未来的脉冲。
神经元发放率的另一个常见近似值是,在许多编码相同值的神经元上,用群体均值代替统计均值。假设它们在统计上彼此独立(例如,如果神经元未直接连接),则在单个试验中对它们的响应求平均就等于在相同数目的试验中对单个神经元的响应求均值。
在此,我们结合了时序平均和群体平均,将价值函数重新定义为Ncritic = 100个神经元的平均发放率:
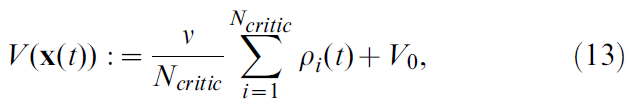
其中神经元 i 的瞬时发放率由公式12定义,使用其脉冲序列Yi和由下式定义的核K:
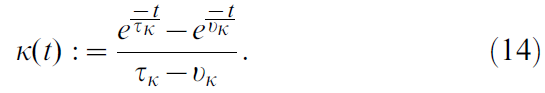
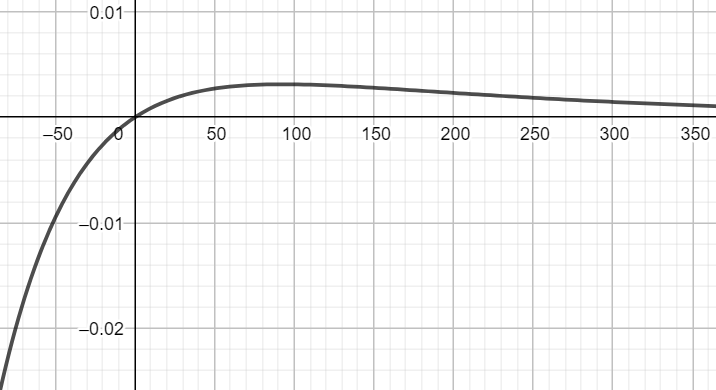
该核以时间常数vk = 50 ms上升,并以时间常数τk = 200 ms衰减到0 (当x<0时,核函数为0;当x≥0时,核函数曲线如上图所示)。公式12的定义的优点之一是神经元 i 的发放率相对于时间的导数只是:

因此,计算发放率的导数只是用核K的导数![]() 对脉冲序列进行滤波的问题。这样,公式5的TD误差δ可以表示为:
对脉冲序列进行滤波的问题。这样,公式5的TD误差δ可以表示为:
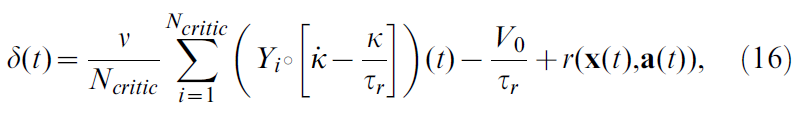
其中,Yi仍表示critic神经元池中神经元 i 的脉冲序列。
假设前馈权重wij从critic神经元群体中的状态表征神经元 j 到神经元 i。critic神经元可以通过改变突触权重来学习近似价值函数吗?这个问题的答案是通过结合公式10与公式13, 16获得的,这导致权重更新:
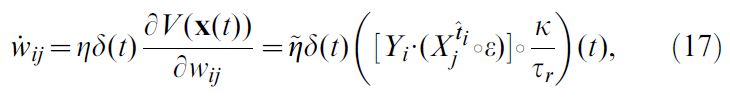
其中ε是EPSP的时间过程,![]() 是突触前神经元 j 的脉冲序列(仅限突触后神经元 i 最后脉冲时间
是突触前神经元 j 的脉冲序列(仅限突触后神经元 i 最后脉冲时间![]() 之后的脉冲)。为简单起见,我们将所有常量合并为新的学习率
之后的脉冲)。为简单起见,我们将所有常量合并为新的学习率![]() 。在Models中可以找到更正式的推导。
。在Models中可以找到更正式的推导。
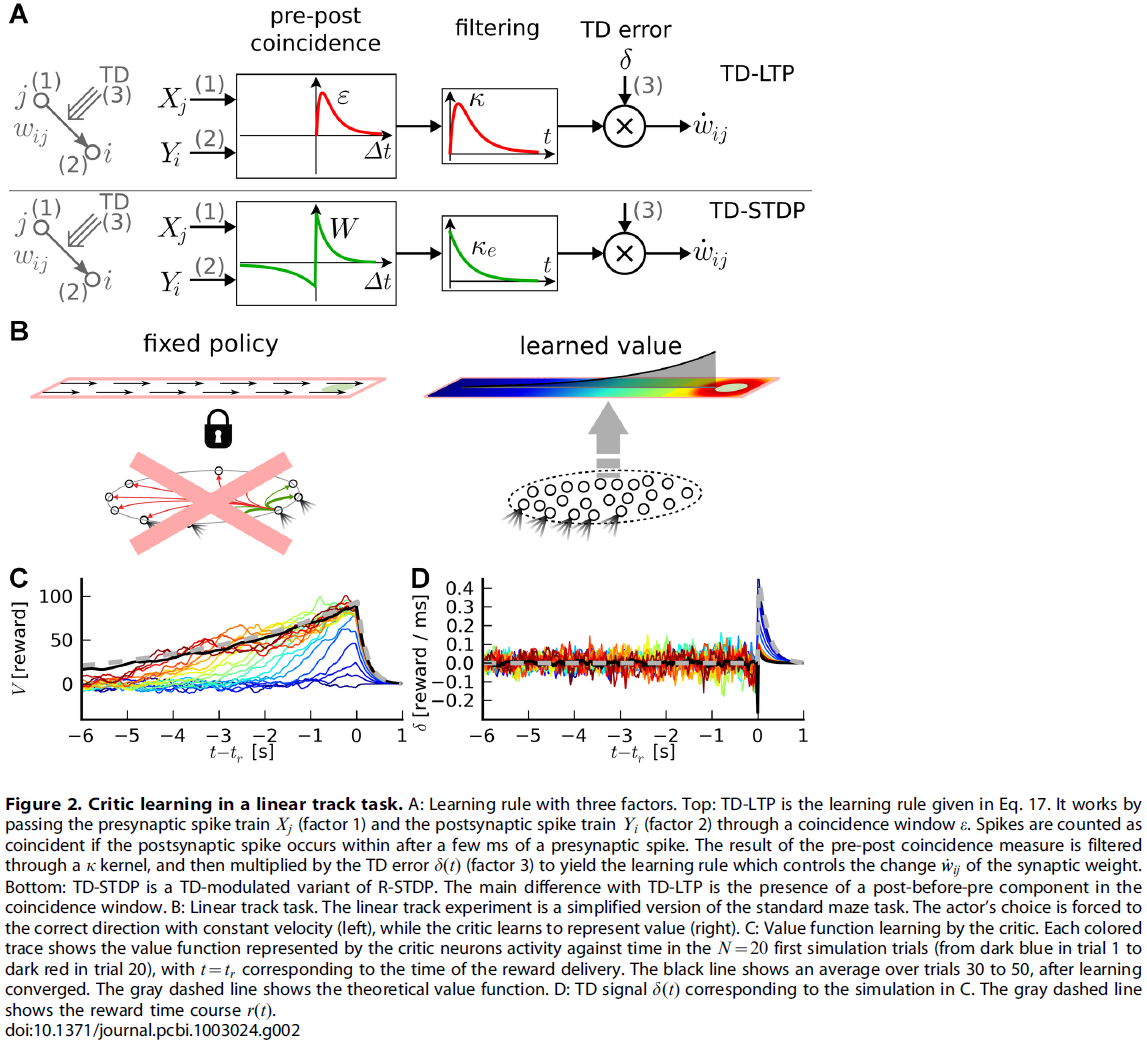
现在,让我们仔细看看公式17提出的学习规则的形状。有效学习率由参数![]() 给出。学习规则的其余部分由两个项的乘积组成。第一个是TD误差项δ(t),对于所有突触{i, j}都是相同的,因此可以认为是全局因子,可能是由一个或多个神经调节剂传递的(图1)。该神经调节剂向网络中的所有神经元广播有关奖励r(t)和critic神经元群体编码的价值函数之间的不一致信息。第二项是突触特定的,反映了由神经元 j 的突触前脉冲和神经元 i 的突触后脉冲引起的EPSP的重合。突触后项Yi是神经元模型中使用的指数非线性的结果(请参见Models)。这个巧合,"Hebbian"项又通过核K进行滤波,这对应于突触后脉冲对V的影响。它反映了突触在最新价值函数中的作用。这两个项共同形成一个三因素规则,其中突触前和突触后活动与全局信号δ(t)结合以修改突触强度(图2A, 顶部)。由于它的格式大致为"TD误差信号 x Hebbian LTP",因此我们将此学习规则称为TD-LTP。
给出。学习规则的其余部分由两个项的乘积组成。第一个是TD误差项δ(t),对于所有突触{i, j}都是相同的,因此可以认为是全局因子,可能是由一个或多个神经调节剂传递的(图1)。该神经调节剂向网络中的所有神经元广播有关奖励r(t)和critic神经元群体编码的价值函数之间的不一致信息。第二项是突触特定的,反映了由神经元 j 的突触前脉冲和神经元 i 的突触后脉冲引起的EPSP的重合。突触后项Yi是神经元模型中使用的指数非线性的结果(请参见Models)。这个巧合,"Hebbian"项又通过核K进行滤波,这对应于突触后脉冲对V的影响。它反映了突触在最新价值函数中的作用。这两个项共同形成一个三因素规则,其中突触前和突触后活动与全局信号δ(t)结合以修改突触强度(图2A, 顶部)。由于它的格式大致为"TD误差信号 x Hebbian LTP",因此我们将此学习规则称为TD-LTP。
我们想指出的是TD-LTP学习规则与奖励调节的脉冲时序依赖可塑性规则(我们称为R-STDP [6,16,30-32])的相似性。在R-STDP中,经典STDP [33–36]的效果存储在指数衰减的中间项(时间常数τe ~ 0.1 – 0.5 s),突触特定存储器,称为资格迹。仅当将全局神经调节成功信号d(t)发送到突触时,此迹才被印入到实际突触权重中。在R-STDP中,神经调节信号d(t)是奖励减去基准,即d(t) = r(t) - b。研究表明[32],为了使R-STDP最大化奖励,基准必须与平均(或期望)奖励精确匹配。从这个意义上讲,d(t)是奖励预测误差信号;需要一个计算该信号的系统。由于TD误差也是奖励预测误差信号,因此使用δ(t)代替d(t)似乎很自然。这会将奖励调节的学习规则R-STDP转换为TD误差调节的TD-STDP规则(图2A, 底部)。在这种形式下,TD-STDP与TD-LTP非常相似。两者之间的主要区别是post-before-pre脉冲配对对学习规则的影响:尽管在TD-LTP中忽略了这些配对,但它们对TD-STDP中的一致性检测产生了负面影响。
引入的滤波核K用来将脉冲序列滤波为可微分的发放率,其作用类似于R-STDP以及离散TD(λ)[1]中的资格迹。如前一节所述,这是价值函数的平滑参数化函数近似(每个critic脉冲贡献形状K到V)与来自公式10的学习规则的形式相结合的结果。滤波核K对于TD误差的反向传播至关重要,因此对于解决时序信度分配问题也至关重要。
Linear Track Simulation
在展示了脉冲神经元如何表示和学习价值函数之后,我们接下来通过仿真测试这些结果。但是,在actor-critic框架中,actor和critic是协作学习的,这使得难以区分两者学习的效果。为了隔离critic的学习并忽略actor的潜在问题,我们通过使用强制动作设置暂时避开了这一难题。我们将水迷宫转换为线性轨迹,并将动作选择"截断"到一个价值,该价值使智能体直接获得奖励。换句话说,不仿真actor神经元,请参见图2B,而智能体只是"奔跑"到目标。在时间tr到达时,将获得奖励并结束试验。
图2C显示了critic使用上述学习规则学习到的N = 20种颜色编码试验(从蓝色到红色)的价值函数。第一次运行(深蓝色迹线)时,critic神经元对奖励太幼稚,因此代表零价值函数(的带噪版本)。达到目标后,TD误差(图2D)与奖励时间过程相匹配,δ(t) ≈ r(t)。根据公式17中的学习规则,这会增强最近在奖励之前经历pre-post活动的突触(由核K定义的"最近")。这在第二次试验中(当正好在奖励变为正之前的V(t)值时)已经可见。
在下一个试验中,将重复这种作用,直到TD误差消失为止。假设在一个特定的试验中,奖励是从智能体达到目标的时间tr开始的。根据TD误差的定义,在所有时间t < tr上,仅当![]() ——或等效地
——或等效地![]() 时,V值才是自一致的。图2C中的灰色虚线表示理论价值函数的时间过程;在许多次重复中,代表不同试验中的价值函数的彩色迹线越来越接近理论价值。学习收敛后,图2C中的黑线表示20个最近试验的平均价值函数:它与理论价值完全匹配。
时,V值才是自一致的。图2C中的灰色虚线表示理论价值函数的时间过程;在许多次重复中,代表不同试验中的价值函数的彩色迹线越来越接近理论价值。学习收敛后,图2C中的黑线表示20个最近试验的平均价值函数:它与理论价值完全匹配。
在图2C中出现的一个有趣的点是,以价值函数形式表示的有关奖励信息的清晰可见的反向传播。在最初的试验中,价值函数V(t)仅在奖励时间之前的短时间内上升。在下面的试验中,这会导致更早的TD误差。随着试验的进行,对应于更早时间的突触权重增加。经过图2C中的~10次试验后,价值函数与刚好在tr前的理论价值大致匹配,但没有更早。在随后的试验中,不匹配点被及时推迟。
这种反向传播现象是TD学习算法的特征。这里应注意两点。首先,反向传播发生的速度取决于学习规则的Hebbian部分中核K的形状。它在RL中起着等同于资格迹的作用:它在经历pre-before-post活动后以衰减的迹"标记"突触,该迹仅在全局确认信号δ(t) ≠ 0到达时合并为权重变化。K的这种"资格迹"作用不同于其在δ项中的原始作用,在δ项中它被用来平滑critic神经元的脉冲活动(公式12)。因此,可能会试图更改学习规则中K项的衰减时间常数,以便控制反向传播速度,同时保持δ信号的"其他"K固定。在单独的仿真中(未显示),我们发现这种临时方法并未导致学习性能的提高。
其次,我们通过构造知道奖励信息的这种反向传播是由TD误差信号δ(t)驱动的。但是,图2D的视觉检查显示了与图2C中的实验相对应的δ(t)迹线,并未发现TD误差有任何清晰的反向传播。对于t > tr,在早期迹线(蓝线)中可见一个反映奖励信号r(t)(灰色虚线)的大峰值,并且随着价值函数正确地学习期望奖励而迅速消退。对于t < tr,δ以快速噪声为主,掩盖了误差信号的任何反向传播(即使正确学习了价值函数的事实表明这确实存在且有效)。有人可能会推测,如果一个生物系统正在使用带有脉冲神经元的TD误差学习系统,并且如果实验者要记录少数critic神经元,那么测量任何重要的TD误差反向传播将非常痛苦。这可能是因为在实验中未观察到反向传播信号这一事实。
我们已经讨论了R-STDP规则[6,30,31]的TD调节版本与TD-LTP的结构相似性。使用TD-STDP规则进行的线性轨道实验的仿真表明,它的行为与我们的学习规则相似(数据未显示),即,这两个规则之间的差异(重合检测窗口的post-before-pre部分,请参见图2A)在这种情况下似乎没有起到关键作用。
Spiking Neuron Actor
我们在上面已经看到,"critic"群体中脉冲神经元可以学会代表期望回报。接下来,我们要问一个脉冲神经元智能体如何选择其动作以最大化奖励。
在RL的经典描述中,动作(如状态和时间)是离散的。尽管可能会发生离散动作(例如当实验动物必须选择按下哪个杆时),但大多数运动动作(例如伸手或在空间中的运动)更自然地由连续变量来描述。即使动物仅具有有限数量的神经元,诸如群体向量编码[37]之类的神经编码方案也允许离散数量的神经元编码连续动作。
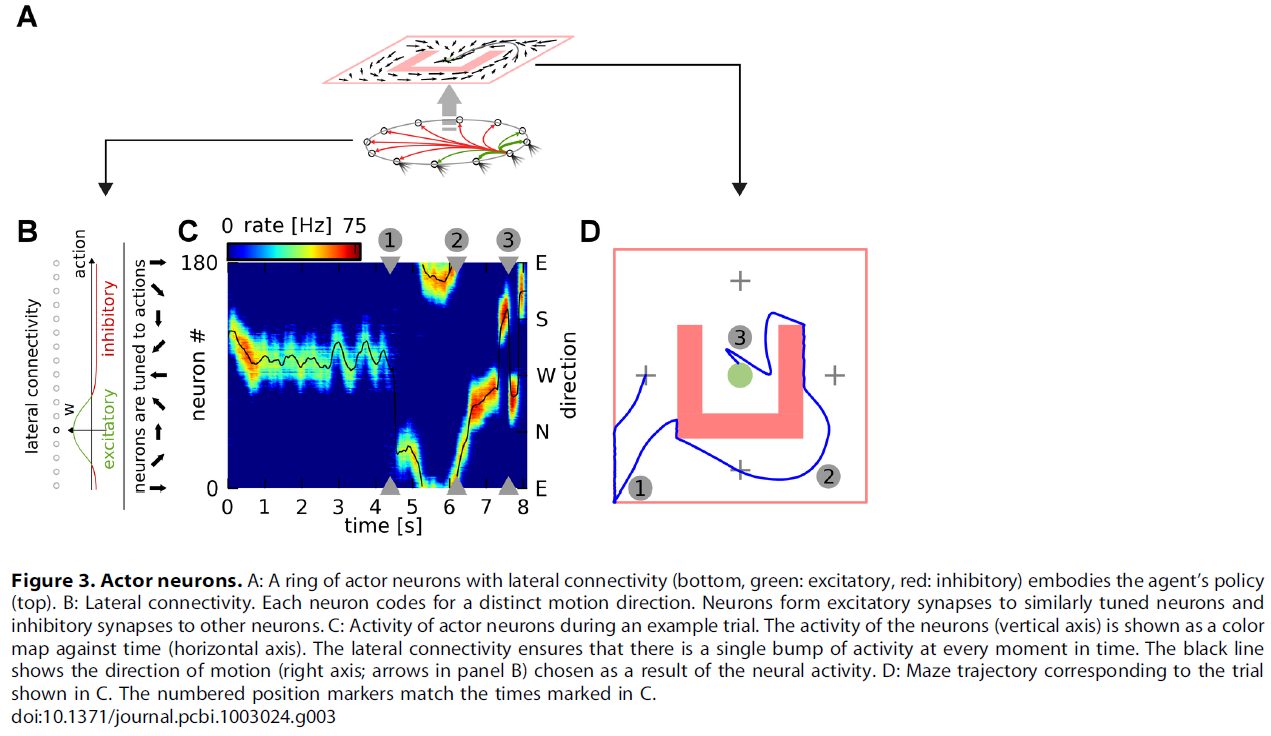
我们遵循群体编码方法,并将actor定义为一组Nactor = 180个脉冲神经元(图3A),每个神经元编码不同的运动方向。像critic神经元一样,这些actor神经元也从位置单元接收连接,代表智能体的当前位置。这些神经元产生的脉冲序列经过滤波以产生平滑的发放率,然后将其乘以每个神经元的首选方向(有关所有计算的详细信息,请参见Models)。最后,我们对这些向量求和,以获得该特定时间的实际智能体动作。为了确保明确选择动作,我们使用N-winner-take-all横向连接方案:每个神经元以类似的转向刺激神经元,并抑制所有其他神经元(图3B)。我们手动调整了连接强度,以使神经元的单个"隆起"(bump)始终处于活动状态。图3C给出了一个actor神经元池中的活动以及在(成功的)试验中相应的动作读数的例子。相应的迷宫轨迹显示在图3D中。
在RL中,成功的智能体必须权衡对未访问状态和动作的探索(以寻求新的奖励)以及先前成功策略的开发。在我们的网络中,探索/开发权衡是隆起动态的结果。看到这一点,让我们考虑一个幼稚的智能体,其特征在于从位置单元到actor神经元的均匀连接。对于这种智能体,隆起首先随机形成,然后在动作空间中不加选择地漂移。这对应于随机动作选择或完全探索。在为实现目标而奖励该智能体后,特定位置单元与特定动作联系起来的突触权重会被增强。这将增加下次为该动作形成隆起的可能性。因此,动作选择将变得更具确定性,并且智能体将利用其在先前试验中获得的知识。
在此,我们提出对actor神经元的突触使用与critic神经元相同的学习规则。原因如下。让我们看一下δ(t) > 0的情况:critic发出信号,即智能体最近采取的一系列动作导致了意外的奖励。这意味着应加强最近活跃的动作神经元与已收到其输入的状态神经元之间的关联,以便在下一次出现该状态时更有可能仍采取相同的动作。在强化信号为负的情况下,应减弱与最近活跃的动作神经元的连通性,以使得不太可能仍采取最近采取的动作,希望有更好的替代。这类似于从状态输入到critic神经元的突触应根据突触前和突触后活动而增强/减弱的方式。这表明动作神经元应该使用与公式17中相同的突触学习规则,现在Yi表示动作神经元的活动,但δ信号仍由critic活动驱动。这在生物学上是合理的,并且与我们的假设一致,即δ由神经调节剂传递,该神经调节剂在大脑的大部分区域中广播信息。
我们的N-winner-take-all横向连接方案有两个关键影响。首先,它确保只有编码相似动作的神经元才能同时活跃。由于学习规则中的Hebbian部分,这意味着只有那些直接负责动作选择的神经元才能受到强化(积极或消极的影响)。其次,通过迫使动作神经元的活动采取一组相似转向的神经元的形状,它有效地导致了跨动作的泛化:编码与所选动作相似的动作的神经元也将处于活跃状态,因此该动作的结果也将得到信度[16]。这类似于actor在非脉冲神经元actor-critic算法中的学习方式[18,19],其中只有实际采取的动作才被学习规则分配信度。因此,尽管在每个位置上可以执行无数个动作,但是智能体不必探索每个动作(一个无限长的任务!)来学习正确的策略。
actor和critic都使用相同的学习规则这一事实与Barto et al. [18]的actor-critic网络的原始表述形成了鲜明对比,其中critic学习规则的格式为"TD误差 x 突触前活动"。如上所述,critic学习规则为"TD误差 x Hebbian LTP"形式(这里使用的公式17)是神经元模型中使用的指数非线性的结果。对critic和actor使用相同的学习规则具有有趣的特性,即必须假定单个生物可塑性机制来解释这两种结构中的学习。
Water-Maze Simulation
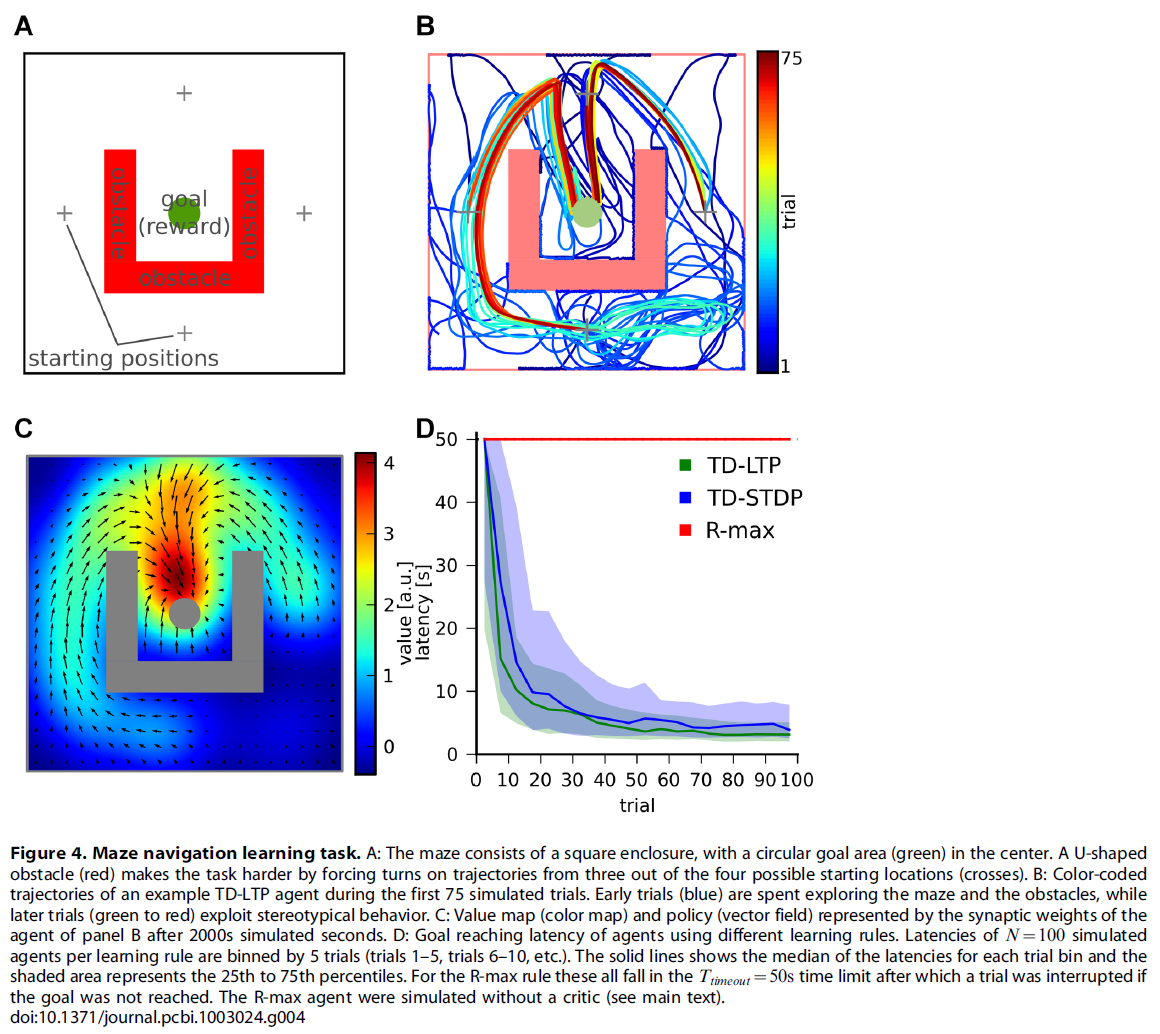
在Morris水迷宫中,一只老鼠在不透明的水池中游泳,寻找被淹没的平台。假定动物对水有轻微的不适,并且正在平台上积极寻求避难,它的到达是一种积极的(奖励)事件。在我们的仿真导航任务中,学习智能体(对动物进行建模)被随机放置在四个可能的起始位置之一,并在代表水池的二维空间中移动(图4A)。其目标是达到目标区域(占总区域的~1%),从而触发奖励信号的传递并结束试验。由于actor神经元池中的吸引子动态使智能体很自然地遵循一条直线,因此通过用U型障碍物围绕目标,使得从四个开始位置中的三个开始,智能体必须至少旋转一次来达到目标,从而使问题变得更加棘手。当接触到迷宫中的障碍物时会造成惩罚(负奖励)。类似于动物实验中的惯例,当不成功的试验超过最大持续时间Ttimeout = 50 s时,试验便会中断(不提供奖励)。
在试验期间,突触根据学习规则(公式17)不断更新其权重。试验结束时,我们通过抑制所有位置单元的活动来仿真从水池中捡起的动物。这导致所有神经活动迅速消失,导致学习规则中已滤波的Hebbian项消失,学习有效停止。在3s的试验间隔之后,将智能体定位在新的随机位置,开始新的试验。
图4B显示了典型仿真智能体的颜色编码轨迹。幼稚的智能体花费大部分的早期试验(蓝色迹线)来学习如何避免墙壁和障碍物。然后,智能体首先通过探索随机地遇到目标,然后通过强化成功的轨迹反复地达到目标。后来的试验(黄色到红色迹线)表明,该智能体主要利用已学到的定型轨迹来达到目标。
通过检查从位置单元到actor或critic神经元的突触权重,我们可以有趣地洞悉在图4B所示的试验中学到的东西。图4C显示了针对critic神经元的输入强度,作为该智能体每个可能位置的颜色图。这实际上是一个"价值图":智能体将其分配给迷宫中每个位置的价值。在同一张图中,通过表示"策略偏好图"的矢量场来说明actor神经元的突触权重。这只是一个偏好图,而不是真实的策略图,因为来自位置单元的输入(由箭头表示)与actor网络的横向动态竞争,后者是历史依赖的(未表示)。
所获悉的价值和策略图取决于经验,并且对于每个智能体都是唯一的:图4B和C中所示的智能体首先发现如何从"北"(N)起始位置达到目标。然后发现如何从起始位置E和W到达N位置,最后从S到达W。但是,它还没有发现从S到E的方式。因此,它归因于SE区域的值是低于对称等效区域的SW。同样,SE区域的策略基本上没有定义,而SW区域的策略显然指向正确的方向。
图4D显示了针对100个智能体的时延分布(达到目标所需的时间)与试验的关系。幼稚的智能体的试验在平均~40 s后结束(Ttimeout = 50 s后中断试验)。对于使用TD-LTP学习规则(绿色)的智能体,此价值会迅速降低,因为他们在大约~20个试验中学会了可靠地获得奖励。
我们之前曾评论过,公式17的TD-LTP规则类似于TD-STDP,R-STDP规则的TD调节版本[6,30,31],至少在形式上类似于TD-STDP。为了弄清它们在效果上是否也相似,我们使用TD-STDP学习规则(针对critic和actor突触)对智能体进行仿真。图4D中的蓝线表明性能仅比TD-LTP规则稍差,这证实了我们在线性轨道上的发现,即两个规则在函数上是等效的。
策略梯度法[5]采用了非常不同的方法来强化TD方法的学习。一种用于脉冲神经元的策略梯度方法是R-max [4,6,32,38,39]。简而言之,R-max通过计算Hebbian pre-before-post活动和奖励之间的协方差来工作。由于此计算依赖于对许多试验求均值,因此R-max是一个固有的缓慢规则,通常会学习数百或数千次试验。因此,人们会期望它无法与TD-LTP或TD-STDP的学习速度相提并论。R-max与其他学习规则的另一个不同之处在于,它不需要critic[32]。因此,我们使用仅具有一个actor的R-max仿真一个智能体,并用奖励![]() 替换了TD信号。图4的红线表明,正如所期望的,R-max智能体的学习速度比先前仿真的智能体慢得多,如果有的话:学习实际上是如此缓慢,与该学习规则的通常时间尺度一致,因此不能在图中展示,因为这将需要更长的仿真时间。
替换了TD信号。图4的红线表明,正如所期望的,R-max智能体的学习速度比先前仿真的智能体慢得多,如果有的话:学习实际上是如此缓慢,与该学习规则的通常时间尺度一致,因此不能在图中展示,因为这将需要更长的仿真时间。
有人可能会反对在没有critic的情况下使用R-max规则是不公平的,并且可能会像我们对R-STDP所做的那样,通过将奖励项替换为δ误差,将其转化为R = TD的R-max规则,从而从中受益。但这忽略了两点。首先,不能使用这样的"TD-max"规则来学习critic:从构造上讲,它将倾向于使TD误差最大化,这与critic必须实现的目标相反。其次,即使有人要使用另一条规则(例如TD-LTP)来学习critic,也无法解决缓慢的时间尺度问题。我们对使用"TD-max" actor的智能体进行了实验,同时为critic保留TD-LTP,但是找不到使用R-max actor的智能体的显著改进(数据未显示)。
Acrobot Task
展示了我们的actor-critic系统可以学习导航任务之后,我们现在解决需要更高时间精度和更高维度状态空间的任务。我们专注于体操机器人(Acrobot)起摆任务,这是强化控制文献中的标准控制任务。在此,目标是在重力的影响下将双摆的最外端提升到一定水平以上,仅在关节处使用一个弱扭矩(图5A)。这个问题类似于体操运动员悬挂在单杠下方的问题:她的手围绕杠自由旋转,而引起运动的唯一方法是扭动臀部。尽管一个健壮的运动员可以通过一次动作将双腿抬起,但我们的Acrobot实在太虚弱,无法应对。取而代之的是,成功的策略包括来回移动双腿以开始摆动运动,积累能量,直到双腿达到足够的高度为止。
Acrobot的位置由两个角度θ1和θ2完整描述(请参见图5A)。但是,解决任务所需的摆动运动意味着,即使在相同的角度位置,也可能需要不同的动作(扭矩),具体取决于系统当前是向左摆动还是向右摆动。因此,角速度![]() 和
和![]() 也是重要的变量。这四个变量共同表示智能体的状态,即导航任务中x-y坐标的四维等效项。就像在水迷宫的情况下一样,将位置单元的发放率调整到四维空间中的特定点。
也是重要的变量。这四个变量共同表示智能体的状态,即导航任务中x-y坐标的四维等效项。就像在水迷宫的情况下一样,将位置单元的发放率调整到四维空间中的特定点。
类似于迷宫导航,动作的选择(在这种情况下,施加在摆关节上的扭矩)由actor神经元的群体向量编码。这与水迷宫中actor仅有的两个区别是 (i) 动作由单个标量描述;(ii) 动作神经元吸引子网络不再位于闭合环上,而是位于开放段上,在-Fmax ≤ F ≤ Fmax的范围内编码扭矩F。
有几个因素使Acrobot任务比水迷宫导航任务难。首先,状态空间更大(四维相对于二维)。因为我们用来表示智能体状态的位置单元的数量随状态空间的大小呈指数增长,所以这是一个关键点。大量的位置单元意味着智能体不常访问每个位置单元,从而使学习变慢。在甚至更高的维度上,在某些情况下,位置单元方法也会失败。但是,我们想证明它仍然可以在四维里取得成功。
第二个困难来自Acrobot系统相对于神经网络动态的更快动态。尽管在仿真中我们可以完全控制导航和Acrobot动态的时间尺度,但我们希望将它们保持在动物自然可能发生的范围内。因此,Acrobot模型需要快速控制,精度约为100毫秒。最后,Acrobot表现出复杂的动态,在无控制的情况下混乱。导航任务的最优策略是选择一个动作(即一个方向)并坚持下去,而解决Acrobot任务则需要精确定时的动作才能使摆成功地摆脱重力。
尽管存在这些困难,但使用TD-LTP学习规则的actor-critic网络仍能够解决Acrobot任务,如图5B所示。我们将性能与近乎最优的轨迹进行了比较[40]:尽管我们的智能体通常以两倍的时间达到目标,但它们仍在学习合理的解决方案。由于这些智能体以轻度随机的初始突触权重开始(请参见Models),并且具有随机性,因此它们的历史以及其性能也会有所不同。最优智能体的性能接近最优控制器的性能(图5B中的蓝色轨迹)。

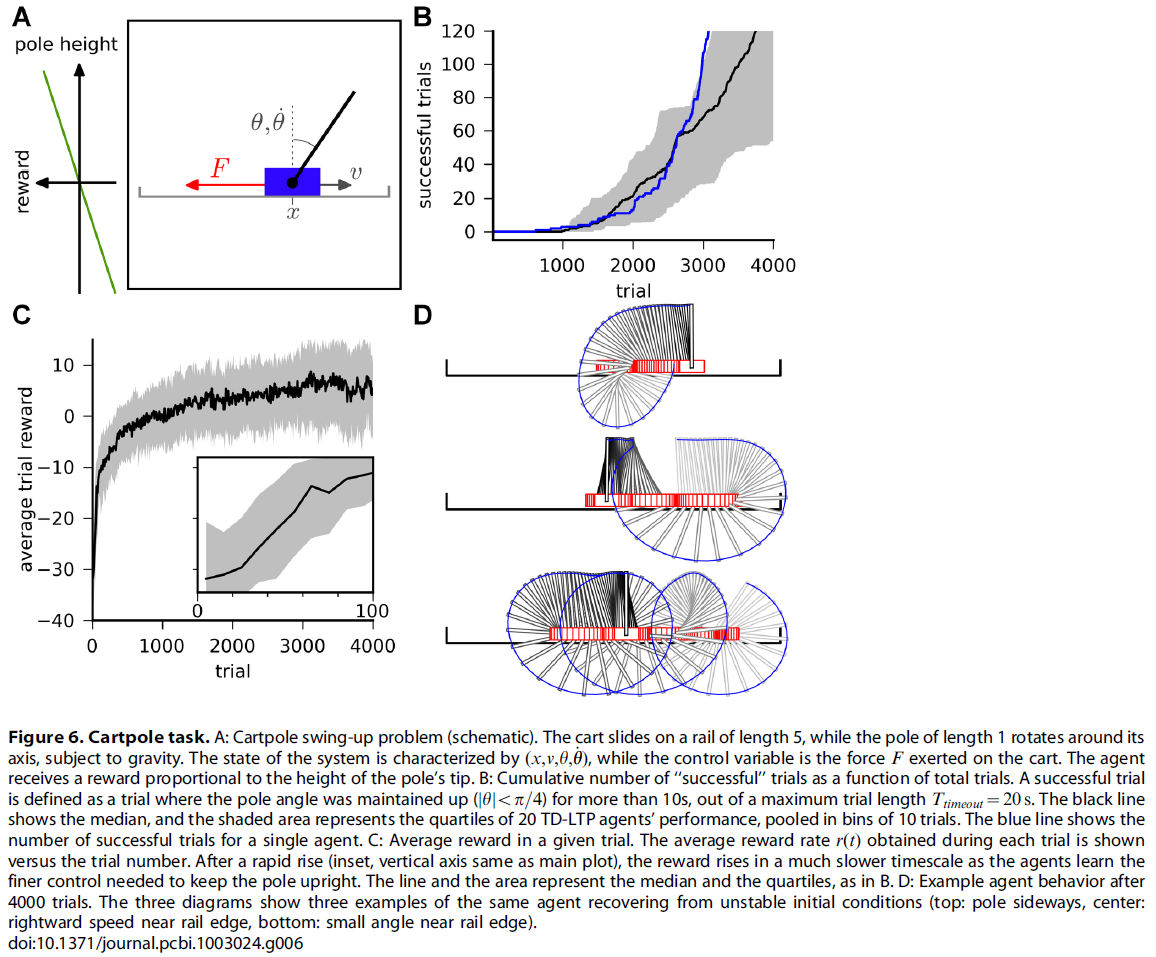
Cartpole Task
接下来,我们将在更困难的控制任务(车杆摆动任务)[19]上执行脉冲神经元actor-critic网络。这是车杆平衡任务的困难版扩展,它是机器学习中的标准任务[18,41]。在此,一根杆附在有轮小车上,它本身可以在有限长度的轨道上自由移动。杆可以绕其轴自由摆动(不与轨道碰撞)。目标是将杆垂直摆动,理想情况下,将其尽可能长时间地保持在该位置。可以施加在系统上的唯一控制是小车上的力F(图6A)。像在Acrobot任务中一样,需要四个变量来描述系统:小车的位置x,其速度v,杆的角度θ和角速度![]() 。我们将成功的试验定义为将杆保持直立状态(|θ| < π/4)超过10 s,而不超过Ttimeout = 20 s的最大试验长度的试验。试验被中断,并且智能体因撞到轨道边缘(|x| > 2.5)或"过度旋转"(|θ| > 5π)而受到惩罚。智能体以奖励率r(t) = 50 cos(θ)受到奖励(或惩罚)。
。我们将成功的试验定义为将杆保持直立状态(|θ| < π/4)超过10 s,而不超过Ttimeout = 20 s的最大试验长度的试验。试验被中断,并且智能体因撞到轨道边缘(|x| > 2.5)或"过度旋转"(|θ| > 5π)而受到惩罚。智能体以奖励率r(t) = 50 cos(θ)受到奖励(或惩罚)。
Cartpole任务比Acrobot任务和导航任务困难得多。在后两者中,智能体只需到达状态空间的特定区域(迷宫中的平台,或Arcobot的特定高度)即可获得奖励并导致试验结束。相反,控制Cartpole系统的智能体必须到达状态空间中与直立的杆(不稳定的流形)相对应的区域,并且必须学会对抗不利的动态以保持在该位置。
因此,要成功地控制Cartpole系统,需要进行大量的尝试。在图6B中,我们显示了成功试验的次数与试验次数的函数关系。"智能体中位数"(黑线)需要进行3500次试验才能得到100次成功试验。这种情况稍差一些,但与[19]的(非脉冲神经元)actor-critic的数量级相同,后者需要~2750次试验才能达到该性能。
通过试验得出的平均奖励的演变(图6C)表明,智能体开始于一个相对较快的进展阶段(插图),这与智能体学会避免撞入轨道边缘的直接危险相对应。其次是学习缓慢,因为智能体学会了越来越好地摆杆和控制杆。为了减短漫长的学习过程,我们对actor和critic在Cartpole任务上都采用了可变的学习率:我们使用最近获得的平均奖励来选择学习率(请参见Models)。更准确地说,当奖励较低时,智能体使用的学习率较高,但是当性能提高时,智能体能够以较低的学习率学习更精细的控制策略。最终,智能体可以进行精细控制,并且可以轻松地从不稳定的情况中恢复(图6D)。对仿真结果的详细分析表明,我们的学习智能体在网络的actor部分受到噪声的困扰,妨碍了保持杆直立所需的精细控制。例如,图6D中的智能体已经学会了如何从下降的杆中恢复(顶部和中间图),但偶尔需要花费比使杆垂直停顿(底部图)严格所需的更多时间。在我们的脉冲神经元实现中,额外的脉冲发放噪声可能解释了与[19]中的actor-critic的性能差异。
Discussion
在本文中,我们研究了奖励调节的脉冲时序依赖的学习规则,以及可以在其中使用的神经网络。我们推导出了一个针对actor-critic网络的脉冲时序依赖的学习规则,并表明该规则可以解决水迷宫式学习任务,以及既需要掌握困难控制问题的Acrobot和Cartpole摆动任务。推导的学习规则具有很高的生物学可塑性,并且类似于先前研究的R-STDP规则族。
Biological Plausibility
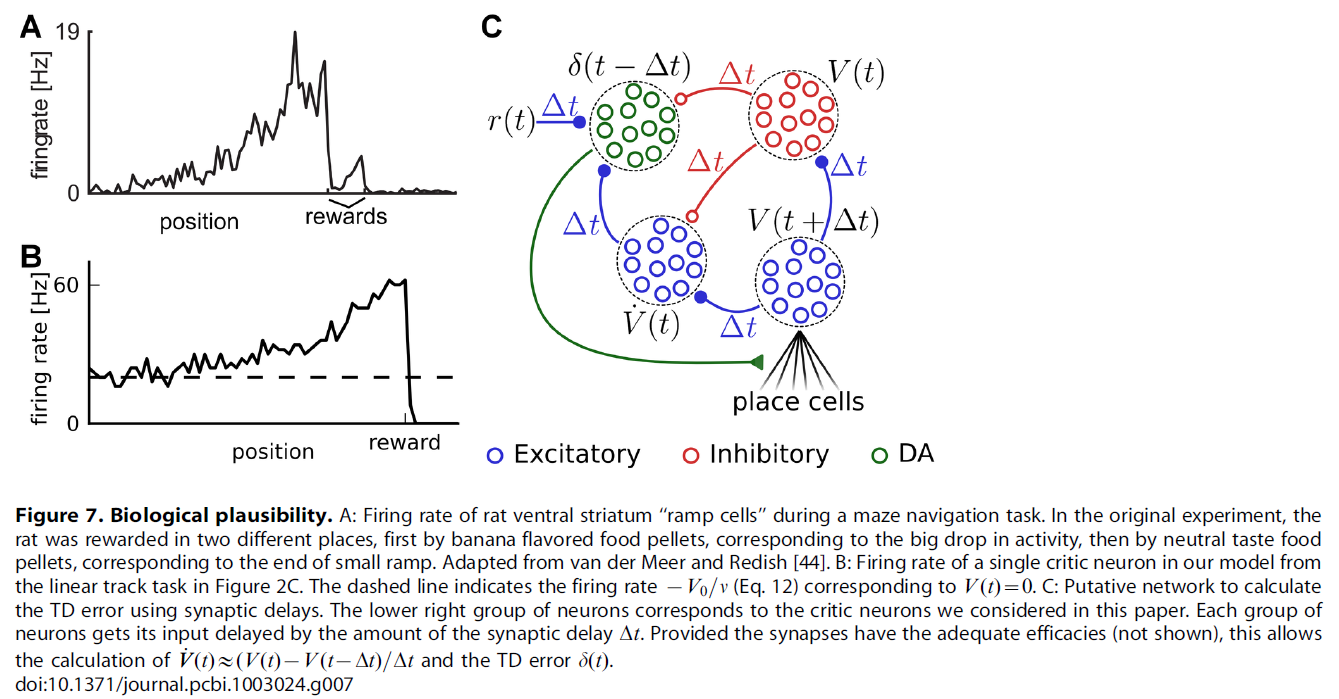
在整个研究过程中,我们试图在模型简单性和生物学合理性之间保持平衡。对于actor-critic结构,我们的网络模型应尽可能简单且通用。我们不想将其映射到特定的大脑结构,但是已经提出了候选映射[42,43]。尽管它们未描述特定的大脑区域,但我们网络的大多数组件都类似于大脑结构。我们的位置单元与海马体位置细胞非常接近,甚至受其启发[22]。在此,我们假设编码到位置单元的信息可供大脑的其余部分使用。调节到特定动作并通过群体向量编码与动物水平动作相关的actor神经元类似于运动或运动前皮质的经典模型[37]。长期以来,腹侧纹状体的所谓"斜坡"神经元一直被认为是critic神经元的候选者:他们在奖励方式上的斜坡活动与理论critic的活动相吻合。如果将实验数据(例如,图7A,改编自van der Meer and Redish [44])和典型的critic神经元的活动(图7B)进行比较,则令人惊讶。将全局TD误差信号传递到突触的主要神经调节候选者是多巴胺:多巴胺能神经元长期以来表现出类似TD的活动模式[7,45]。
用多巴胺浓度表示TD误差的问题是,虽然理论上定义的δ误差信号既可以是正值也可以是负值,但多巴胺浓度值[DA]自然会绑定到正值[46]。可以通过在两个值(例如δ = log[DA])之间建立一个非线性关系(以δ范围内的灵敏度变化为代价)来避免这种情况。甚至更简单的分段线性方案δ = [DA] - b (其中b是基准多巴胺浓度)也足够,因为只要TD误差的符号正确,学习就可以进行。
另一种可能是,多巴胺将TD误差带入正范围,而其他一些神经调节剂将TD误差带至负范围。血清素在逆向学习中似乎起着与负TD误差相似的作用[47],是一种候选者。另一方面,在学习任务期间实验性记录背侧5-羟色胺神经元的活动严重挑战了5-羟色胺的这种作用[48,49],该实验记录未能显示出与TD逆信号相对应的活动模式。
我们的actor-critic模型的一个方面,不是通过脉冲神经元直接实现,而是通过算法实现的,其中之一就是TD信号的计算,它取决于奖励,价值函数及其导数。在我们的模型中,此计算对于整体功能至关重要。奖励和价值函数的加减可以通过同时对一组神经元进行兴奋性和抑制性输入来完成。类似地,价值函数的导数可以通过信号直接激励并通过同一信号延迟(例如通过额外的突触)抑制来完成(请参见图7C中的示例)。这种回路是否可以有效地用于计算有用的TD误差,还有待观察。无论如何,从腹侧纹状体(可能的critic)到黑质致密性黑质(可能的TD信号发送者)的连接都显示出许多兴奋性和抑制性途径,特别是通过苍白球,可能恰好具有此功能[50]。
Limitations
我们方法的一个关键局限性是我们依赖相对低维的状态和动作表征。因为两者都使用类似的调整/位置单元表征,所以表示这些空间的神经元数量必须随维度数量呈指数增长,这是维数灾难的一个例子。虽然我们证明了我们仍然可以成功地解决有关多维状态描述的问题,但是随着维数的增加,这种方法迟早会失败。取而代之的是,解决方案可能在于对状态空间进行"智能"预处理,以描绘有用且与奖励相关的低维流形,可以在其上调整位置单元。确实,可以使用标准无监督的Hebbian学习规则,通过具有数千个"视网膜"像素的视觉输入来学习位置单元的表征[20,51,52]。
此外,TD-LTP是在稀疏神经编码的假设下得出的,其中神经元具有狭窄的调整曲线。这与基于协方差的学习规则[53](例如R-max [4,6,38,39])相反,该规则在理论上可以与任何编码方案一起使用,尽管代价是学习数量级变慢 。
Synaptic Plasticity and Biological Relevance of the Learning Rule
尽管存在许多针对STDP与多巴胺神经调节之间关系的实验研究[11-14,54],但人们仍在为这两种机制在大脑中如何相互作用而得出准确的结论感到痛苦。因此,很难从实验数据中提取精确的学习规则。另一方面,我们可以根据实验结果检查我们的TD-LTP学习规则,并查看它们是否匹配,即执行TD-LTP的生物突触是否会产生观察到的结果。
在皮质-纹状体突触处结合多种形式的多巴胺或多巴胺受体操纵与高频刺激方案的实验提供了多巴胺与突触可塑性之间相互作用的证据[8-11]。尽管这些实验过于粗糙,无法解决脉冲时序依赖性,但它们形成了多巴胺依赖性的图景:似乎在高浓度下,多巴胺与高频刺激相结合的作用是诱导长期增强(LTP),而在较低浓度下,会观察到长期抑制(LTD)。在"基准"水平处于中等水平时,未观察到任何变化。如果假设多巴胺浓度DA与TD误差之间的关系DA(t) = δ(t) + baseline,则此图片与TD-LTP或TD-STDP一致。
TD-LTP和TD-STDP之间的主要区别在于,在post-before-pre脉冲配对上规则的行为。尽管TD-LTP忽略了这些,但TD-STDP导致LTD(LTP)进行正(负)神经调节。重要的是,对于规则的学习能力而言,这似乎并没有扮演重要角色,即,pre-before-post是唯一重要的部分。鉴于Zhang et al. [13]在海马体突触上的研究,这很有趣,发现细胞外多巴胺泡可以逆转学习窗口的post-before-pre侧,同时增强pre-before-post侧。这与以下事实兼容:学习窗口的post-before-pre侧极性对于基于奖励的学习不是至关重要的,并且可以起到另一种作用。
TD-LTP和TD-STDP所预测的结果之一,据我们所知,尚未通过实验观察到,是在负奖励预测误差信号下的pre-before-post信号反转。这可能是降低多巴胺浓度而不达到多巴胺抑制的病理水平所需要的实验挑战的结果。然而,基于高频刺激的实验表明,确实发生了长期可塑性整体极性的逆转[8,11]。此外,Seol et al. [54]的研究在不同的神经调节剂(不幸的是,不是多巴胺能的)下的STDP诱导方案显示,STDP学习窗口的两侧在极性和强度上都可以改变。这表明,pre-then-post脉冲配对的影响的符号变化至少在突触分子机器可及的范围内。
来自当前工作的另一个预测是资格迹的存在,弥补了STDP快速时间要求与延迟奖励之间的时序差距。资格迹的概念在RL中得到了很好的探索[1,5,55,56],并且先前已经提出了针对奖励调节的STDP规则[6,30]。尽管我们对TD-LTP的推导通过一条不同的路径(对脉冲信号进行滤波,而不是明确地解决时序信度分配问题)达到资格迹,但在功能上是相同的。特别是,我们提出的资格迹的时间尺度大约为数百毫秒,与奖励调节STDP模型中提出的尺度相同[6,30]。仍然没有直接的资格迹的实验证据,但它们使人联想到突触标记机制[57]。标记的数学模型[58],使用具有不同时间尺度的分子级联,提供了如何在生理上实现资格迹的示例。
Insights for Reward-Modulated Learning in the Brain
我们研究的一个有趣结果是,尽管我们的TD信号正确地"教导"critic神经元价值函数,并将奖励信息反向传播到更远的点,但在TD信号本身的时间过程中很难看到反向传播。原因是信号在快速波动中淹没。如果要记录代表TD误差的单个神经元,则除非在相同条件下具有极高的重复次数,否则可能无法重建无噪声信号。这可能是对以下事实的解释:即使多巴胺神经元似乎编码了这样的信号,Schultz及其同事的研究(例如[45])也多次未能显示TD误差的反向传播。
在这项研究中,TD-STDP(和TD-LTP)以"门控Hebbian"的方式使用:如果A和B之间的突触见证了pre-before-post配对,并且随后的TD信号为正,则应加强这种突触。这与[32]中的学习规则(R-STDP)的奖励调节版本的角色根本不同,其中该规则用于进行基于协方差的学习:平均而言,如果A和B之间的突触在pre-before-post配对与成功信号之间呈正相关,则应该增强这种突触。这样的结果之一就是学习的时间尺度:虽然基于TD的学习需要进行数十次试验,但是基于协方差的学习通常需要数百或数千次试验。硬币的另一面是,基于协方差的学习独立于神经编码方案,而基于TD的学习则需要神经调整曲线以在学习之前映射相关特征。在两种情况下,学习规则的数学结构(即,第三个因子"调节"pre-post一致的影响的三因子规则[59])是相同的,这一事实是显著的,并且可以看到大脑可能必须开发这种多功能工具(一种突触可塑性的"瑞士军刀")的优势。
Models
Neuron Model
对于actor和critic神经元,我们仿真了简化的脉冲响应模型(SRM0, [60])。该模型是LIF神经元的随机变体,其中神经元 i 的膜电位由下式给出:
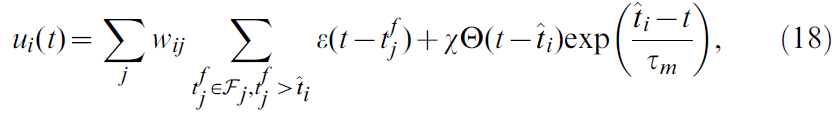
其中wij是从神经元 j 到神经元 i 的突触权重,Fj是神经元 j 发放时间的集合,τm = 20 ms是膜时间常数,![]() 缩放了不应期效应,Θ是Heaviside阶跃函数(单位阶跃函数)且
缩放了不应期效应,Θ是Heaviside阶跃函数(单位阶跃函数)且![]() 是 t 之前神经元 i 的最后脉冲时间。
是 t 之前神经元 i 的最后脉冲时间。
用时间过程描述EPSP:
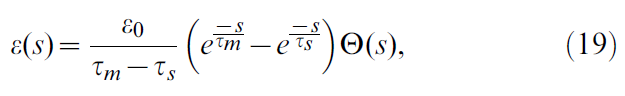
其中τs = 5 ms是突触上升时间,ε0 = 20 mV·ms是缩放常数,τm是膜时间常数,如公式18。给定膜电位ui,SRM0中的脉冲发放是非齐次泊松过程:根据瞬时发放率,神经元在每个时刻都有可能发放脉冲。

其中ρ0 = 60 Hz,θ = 16 mV和Δu = 2 mV是与实验值一致的常数[61]。在极限Δu → 0中,SRM0成为确定性的LIF神经元。
Navigation Task
Morris水迷宫池由二维平面建模,二维平面由正方形墙界定。智能体在平面上的位置x服从:
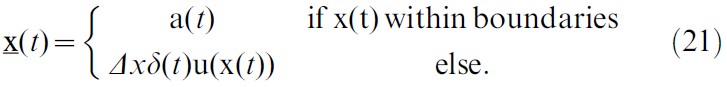
当智能体在边界内时,它以速度a(t)移动,这由actor神经元的活动定义(公式29)。每当智能体碰到墙时,它会立即沿统一向量u(x(t))"反弹"回距离Δx = 0.1,该向量向内指向垂直于障碍物的表面。墙上的每一次"碰撞"都会伴随着惩罚性的负奖励Robst = -1交付(请参见下面的奖励交付动态)。
我们使用了导航任务的两种变体。线性轨迹是一个以原点为中心,大小为(40 x 4)的狭窄矩形,在x = (-17.5, 0)中具有一个起始位置,在相反侧具有较宽的目标区域(x1 ≥ 16)。因为此设置的目标是研究critic学习,所以将动作截断到一个固定值a(t) = (5, 0),以便智能体以固定的速度向目标运行。
第二个变体是带有障碍物的导航迷宫。它由一个以原点为中心,大小为(20 x 20)的正方形区域组成,四个起始位置为x ∈ {(±7.5, 0), (0, ±7.5)}。目标区域是一个以迷宫中间为中心,半径rgoal = 1的圆。目标的三个侧面都被U形障碍物包围(每段宽度:2,长度:10)。
在这两种变体中,位置单元中心xj都放置在网格上(图1中的蓝点),间距σPC = 2与位置场的宽度一致。最外面的中心位于迷宫边界之外的距离为σPC。这确保了整个状态空间的平滑覆盖。在迷宫的情况下,位置单元网格由13 x 13个中心组成。对于线性轨道设置,网格具有43 x 5个中心。
试验中智能体的起始位置x从四个可能的起始位置中随机选择。用 j 索引的位置单元是非齐次泊松过程。试验开始后,位置单元的瞬时发放率将更新为:

其中ρPC = 400 Hz是调节位置单元活性的常数,σPC = 2是位置单元分离距离,xj是位置单元中心。位置单元中的突触前活动在critic和actor的突触后神经元中产生活动,其中由于EPSP的上升时间而引起的延迟很小。
根据公式12和13,使用参数V0 = -40[奖励单位]和v = 2[奖励单位] x s来计算价值函数V。由于V被K核的上升时间τb延迟,因此在试验开始时,TD误差δ(t)会受到较大的边界效应瞬变的影响。为了消除这些伪影,我们在每次试验的第一个Tclamp = 500 ms中将TD误差截断为δ(t) = 0。我们使用奖励折扣时间常数τr = 4 s。
智能体的目的是到达圆形区域,该圆形区域代表水迷宫的浸没平台。当智能体到达该平台时,会收到Rgoal = 100的正奖励,试验结束且智能体被置于所谓的"中性状态",这建模了从实验区域移除动物的过程。这样的效果是:(i) 迷宫所对应的位置单元变得沉默,大概被其他(未建模)位置单元所替代;(ii) 动物的期望变得中性,因此其价值函数变为零。因此,在试验结束时,我们将关闭位置单元活动(ρj = 0),并且不再由公式13给出价值函数,但该值呈指数衰减并在试验结束时衰减至0 (时间常数τk的影响)。重要的是,在试验结束后,突触可塑性仍会继续,因此Rgoal的作用会影响突触权重,即使其递送以中性状态进行也是如此。此外,试验可以在没有到达平台的情况下结束:如果试验超过时间限制Ttimeout,则宣布试验失败,并且如同成功的情况一样,智能体被置于中性状态而被中断,但是没有奖励交付。
根据公式3,将奖励作为奖励率给予智能体。这反映出一个事实,即"自然"奖励和奖励消耗是随时间而不是点状事件分布的。因此,我们将绝对奖励(R)转换为奖励率(r(t)),该奖励率的计算方式是服从动态变化的两个衰减"迹线"之差:
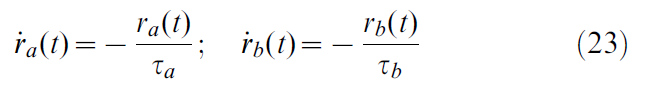
即:
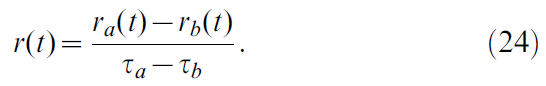
在大多数情况下,奖励接近于0。仅在发生某些事件(达到目标或与障碍物碰撞)时才提供奖励。奖励R的传递通过轨迹的瞬时更新发生:
![]()
产生的结果是随后r(t)的正偏移,上升时间τb = 10 ms,下降时间τa = 200 ms,随着时间推移,积分等于R。
Acrobot Task
在Acrobot任务中,摆的位置由两个角度描述:θ1是摆的第一段和垂直线之间的角度,θ2是第二段和第一段的假想延长线之间的角度(图5A)。当θ1 = θ2 = 0时,钟摆垂下。角速度![]() 和
和![]() 对解决任务也很关键。与迷宫导航情况一样,调整到特定中心的位置单元用于表示Arcobot的状态。我们对角速度进行变换
对解决任务也很关键。与迷宫导航情况一样,调整到特定中心的位置单元用于表示Arcobot的状态。我们对角速度进行变换![]() 。这可以在小速度下实现精细的分辨率,同时以少量的位置单元保持较高速度的表征。状态x由四个变量x = (θ1, θ2, λ1, λ2)表示。
。这可以在小速度下实现精细的分辨率,同时以少量的位置单元保持较高速度的表征。状态x由四个变量x = (θ1, θ2, λ1, λ2)表示。
位置单元中心位于由索引(m, n, p, q)定义的4维网格上,那么![]() ,其中
,其中
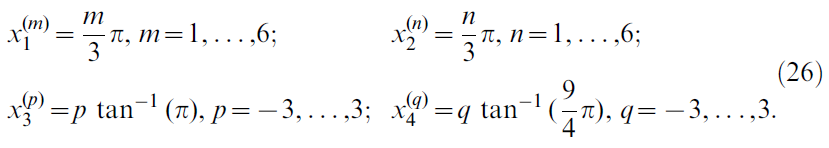
这总共产生6 x 6 x 7 x 7 = 1764个中心。中心为x(m, n, p, q)的位置单元的活动定义为:
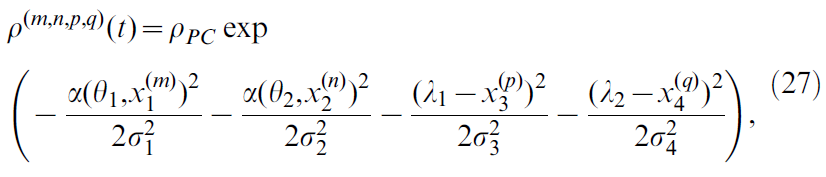
其中α是一个函数,该函数返回两个角度之差mod 2π(范围为(-π, π])和位置单元宽度σ1至σ4对应于网络间距,如公式26所示。
Arcobot动态遵循以下公式[1]:
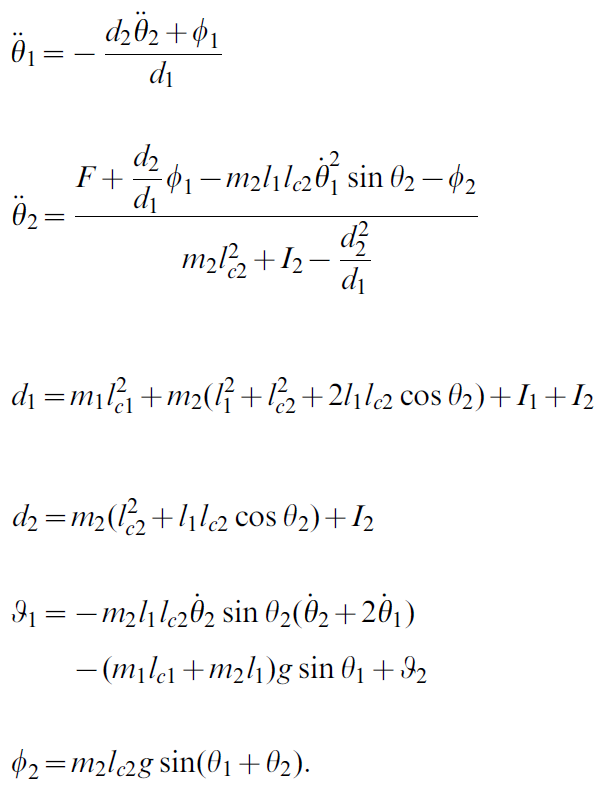
此处,d1, d2, Φ1和Φ2是便利变量,F是施加到关节上的扭矩,![]() 是质量m1 = m2 = 1的段的长度,惯性矩
是质量m1 = m2 = 1的段的长度,惯性矩![]() ,到达质心的长度lc1 = lc2 = 0.5 (在重力g = 9.8 s-2的影响下)。除时间以外的所有维度均无单位。
,到达质心的长度lc1 = lc2 = 0.5 (在重力g = 9.8 s-2的影响下)。除时间以外的所有维度均无单位。
目标是使Acrobot的尖端在轴上达到hgoal = 1的高度,即满足条件![]() 。一旦发生这种情况,或达到最大试验时间Ttimeout = 100,试验就会结束。为了诱使Acrobot做某事,我们对未达到奖励的智能体给予持续的惩罚rpenalty = -10 s-1,并与目标处获得的奖励Rgoal = 100进行比较。与水迷宫一样,我们使用奖励折扣时间常数τr = 4 s。
。一旦发生这种情况,或达到最大试验时间Ttimeout = 100,试验就会结束。为了诱使Acrobot做某事,我们对未达到奖励的智能体给予持续的惩罚rpenalty = -10 s-1,并与目标处获得的奖励Rgoal = 100进行比较。与水迷宫一样,我们使用奖励折扣时间常数τr = 4 s。
由于大数量的位置单元,我们使用的critic和actor神经元要比迷宫情况少,分别是Ncritic = 50和Nactor = 60,以减少突触的数量和计算负荷。
为了将智能体的性能与"最优"策略进行比较,我们使用直接搜索方法[40]。该方法背后的主要思想是在了解Acrobot动态的情况下,寻找可最大化系统总能量的动作序列。为了使搜索在计算上易于处理,进行了一些简化:将动作限制为替代{-Fmax, Fmax},仅以100 ms的步长执行动作,一次仅考虑后续10个步长的窗口,并且每个窗口中的动作开关的数量限制为2个。因此,仅需检查55个动作序列,就可以选择最大化在窗口上达到的总能量或更快达到目标高度的序列。选择该序列中的第一个动作作为下一步的动作,并重复整个过程,同时将窗口移动一个步骤。用此方法发现的达到目标高度的时延为7.66 s (图5B中的红线)。
Cartpole Task
Cartpole系统的位置由杆位置x,杆速度v,杆与垂直线θ的夹角(θ = 0对应于指向上方的杆)和角速度![]() 来描述;这些形成状态向量
来描述;这些形成状态向量![]() 。与Acrobot类似,用于Cartpole问题的位置单元规则地放置在7 x 7 x 15 x 15 = 11025个单元的四维网格上。索引为(m, n, p, q)的位置单元为
。与Acrobot类似,用于Cartpole问题的位置单元规则地放置在7 x 7 x 15 x 15 = 11025个单元的四维网格上。索引为(m, n, p, q)的位置单元为![]() ,其中
,其中
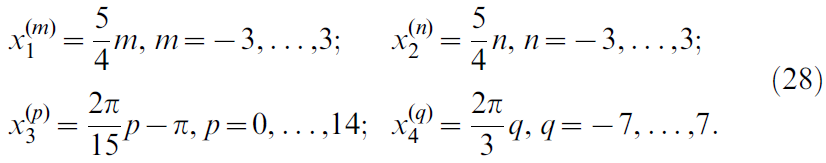
位置单元的活动以类似于公式27的方式定义。高斯位置场的方差是对角线![]() ,其中σk对应于维度k中的网格间距。
,其中σk对应于维度k中的网格间距。
Cartpole的动态是[62]:
![]()

这里![]() 是小车的加速度,l = 0.5是杆的长度的一半,µc = 5·10-4和μp = 2·10-6分别是小车在轨道上的摩擦系数和杆旋转。质量为mc = 1的小车和质量为mp = 0.1的杆受到重力加速度g = 9.8 s-2。与Acrobot情况一样,除时间以外的所有维度都是无单位的。
是小车的加速度,l = 0.5是杆的长度的一半,µc = 5·10-4和μp = 2·10-6分别是小车在轨道上的摩擦系数和杆旋转。质量为mc = 1的小车和质量为mp = 0.1的杆受到重力加速度g = 9.8 s-2。与Acrobot情况一样,除时间以外的所有维度都是无单位的。
根据[19],根据杆的当前高度以r(t) = 50 cos θ连续奖励智能体,奖励折扣时间常数设置为τr = 1 s。如果小车偏离轨道(|x| > 2.5)或过度旋转(|θ| > 5π),则试验结束,并给出负奖励R = -50。Ttimeout = 20 s后,试验结束且没有奖励。当新的试验开始时,系统的位置用随机的θ ∈ [-π, π)和![]() 初始化。
初始化。
Actor Dynamics
在群体向量编码中,每个actor神经元k都会通过发放动作电位来在动作空间中对其首选动作ak"投票"。通过将瞬时发放率ρk(t)(参见公式12)与每个神经元的动作向量的乘积求平均得到动作向量,即:
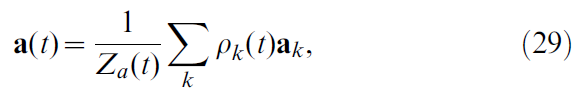
其中ρk被定义为:
![]()
其中滤波器:
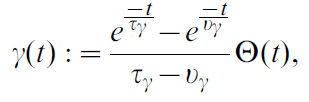
其中τγ = 50 ms和νγ = 20 ms是滤波时间常数。公式29中的Za(t)项是归一化项。在导航任务(二维动作)的情况下,它等于actor神经元的数量Za(t) = Nactor。对于Acrobot和Cartpole任务(标量动作),Za(t) = Σk ρk(t)。
我们通过在动作神经元之间施加"横向"连接,在动作神经元上强制实施N-winner-takes-all机制:编码相似动作的动作神经元相互激发,而它们抑制编码不相似动作的神经元。两个动作神经元k和k'之间的突触权重为:
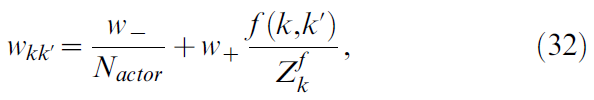
其中,f 是横向连接函数。对于k = k',f 为零;对于k = k' ± 1,f 为峰值,并且 f 随着ak和ak'的发散而单调地向0减小。![]() 是归一化常数。手动调整调节循环连接的参数w- = -60和w+ = 30:横向连接性必须足够强,以使每当动作神经元收到一些位置细胞的激励时,总是存在一个相似转向神经元"隆起"激活,但强度不足以完全控制来自位置单元的前馈输入。
是归一化常数。手动调整调节循环连接的参数w- = -60和w+ = 30:横向连接性必须足够强,以使每当动作神经元收到一些位置细胞的激励时,总是存在一个相似转向神经元"隆起"激活,但强度不足以完全控制来自位置单元的前馈输入。
动作神经元的首选向量ak和函数 f 取决于学习任务。对于迷宫导航任务,首选的动作向量是![]() ,其中a0 = 1.8是代表每个发放率单位的智能体速度的常数,并且
,其中a0 = 1.8是代表每个发放率单位的智能体速度的常数,并且![]() (对于k = 1, ... , Nactor。f 函数被选为:
(对于k = 1, ... , Nactor。f 函数被选为:
![]()
其中ζ = 8 (PS:根据 f 的描述,我们可以猜测出:对于k = k',δkk' = 1;对于k ≠ k',δkk' = 0)。
在Acrobot和Cartpole任务的情况下,动作向量为![]() 。对于Acrobot,Fmax = 0.75表示智能体可以施加的最大扭矩,对于Cartpole任务,Fmax = 10是施加在小车上的最大力。两种情况下的横向连通性函数 f 被选为:
。对于Acrobot,Fmax = 0.75表示智能体可以施加的最大扭矩,对于Cartpole任务,Fmax = 10是施加在小车上的最大力。两种情况下的横向连通性函数 f 被选为:

其中λ = 0.5。另外,我们在算法上将智能体施加的扭矩限制到域F ∈ [-Fmax, Fmax]。这可以建模智能体"肌肉"的有限力量。
Other Reward-Modulated Synaptic Learning Rules
在R-STDP [6,30–32]中,经典STDP的效用由神经调节信号调节![]() ,其中
,其中![]() 为常数基准。通过将d(t)替换为δ(t),我们将奖励调节的R-STDP转换为TD调节规则TD-STDP。TD-STDP规则可以写为:
为常数基准。通过将d(t)替换为δ(t),我们将奖励调节的R-STDP转换为TD调节规则TD-STDP。TD-STDP规则可以写为:
![]()
其中STDP学习窗口为:
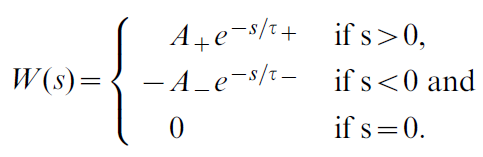
资格迹核Ke是指数衰减的结果,即![]() ,其中时间常数τe = 500 ms。正常数A+ = 0.75和A- = 0.375分别控制学习窗口的pre-before-post和post-before-pre部分的大小,而时间常数τ+ = 20 ms和τ- = 40 ms决定了它们的时间要求。
,其中时间常数τe = 500 ms。正常数A+ = 0.75和A- = 0.375分别控制学习窗口的pre-before-post和post-before-pre部分的大小,而时间常数τ+ = 20 ms和τ- = 40 ms决定了它们的时间要求。
R-max [4,6,32,38]是从策略梯度规则[5]派生的奖励调节学习规则。可以写成:
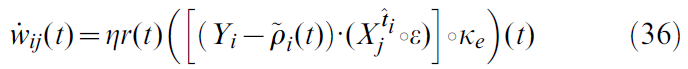
其中![]() 是神经元 i 的瞬时发放率,如公式20中所定义的。
是神经元 i 的瞬时发放率,如公式20中所定义的。
Simulation Details
从均值μw = 0.5和标准差σw = 0.1的正态分布中随机抽取critic和actor的突触权重的初始值。这些值确保了学习之前的初始价值函数V(t) ≈ 0和合理的动作神经元活动。
对于所有学习规则,通过算法将突触权重限制在0 ≤ w ≤ 3范围内,以避免负值或失控权重。手动调整学习率值(一个值给actor,另一个值给critic的突触),使其达到最优性能(通过在2000秒的仿真时间内完成的试验次数来衡量)。表1中列出了导航和Acrobot任务的这些值。对于Cartpole任务,使用可变学习率可以更快地学习。
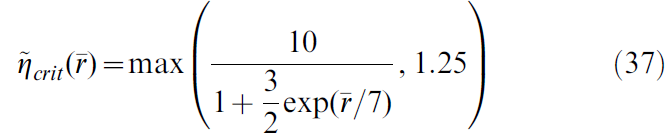
对于critic,其中![]() 是过去奖励率r(t)的运行平均值,是通过使用时间常数为50s的指数窗口对r(t)进行滤波而得出的。actor学习率是
是过去奖励率r(t)的运行平均值,是通过使用时间常数为50s的指数窗口对r(t)进行滤波而得出的。actor学习率是![]() 。
。
所有仿真都是使用Euler方法以时间步骤Δt = 0.2 ms进行的,除了Acrobot和Cartpole动态仿真是使用4阶Runge-Kutta (Δt = 0.01 ms)进行仿真的。
Derivation of δV/δwij
在本节中,我们计算推导公式17所需的项![]() 。使用公式12–13,并关注从 j 到 i 的突触权重wij,我们发现
。使用公式12–13,并关注从 j 到 i 的突触权重wij,我们发现
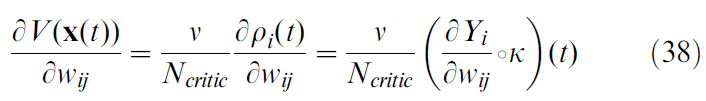
其中我们使用![]() 独立于wij的事实(对于i' ≠ i)。脉冲序列的导数
独立于wij的事实(对于i' ≠ i)。脉冲序列的导数![]() 是不确定的:在我们的随机神经元模型中,脉冲序列本身与突触权重无关。取决于权重的只是神经元实际发出脉冲序列的概率。因此,我们用
是不确定的:在我们的随机神经元模型中,脉冲序列本身与突触权重无关。取决于权重的只是神经元实际发出脉冲序列的概率。因此,我们用![]() 代替
代替![]() ,前者是脉冲序列Yi在输入X上的条件期望值。这导致:
,前者是脉冲序列Yi在输入X上的条件期望值。这导致:
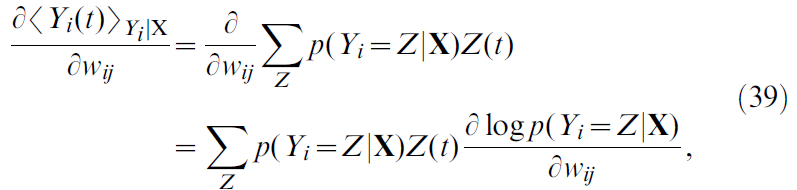
这是所有可能的脉冲序列Z的总和,且p(Yi = Z|X)为脉冲序列Yi等于Z的概率密度。该脉冲序列Z(从0持续到 t)由一个接收输入X的SRM0神经元产生,其概率密度为[38](具体推导见文末):
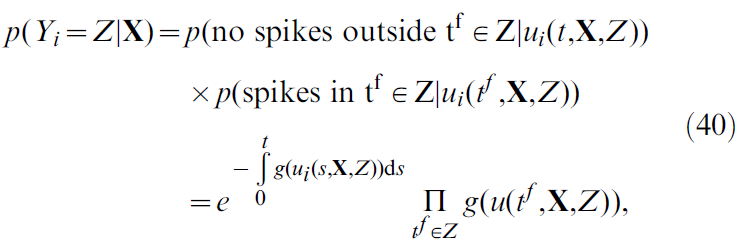
其中ui是膜电位(公式18),并且我们已使用公式20。结合公式39和40导出:

积分反映了这样一个事实,即神经元在时间 t 发出脉冲的概率不仅取决于最近的突触前脉冲,还取决于神经元 i 的最后脉冲时间,而神经元 i 的最后脉冲时间又取决于神经元的整个历史。
在我们的情况下,尚不清楚这种对历史的依赖是否是理想的结果。已经有两个设备考虑了脉冲序列的历史。首先,TD框架中价值函数V的定义仅取决于当前状态,而不取决于长期历史(这源于TD根源的Markov决策过程)。其次,以K进行滤波的脉冲序列已经确保了记住短期历史,从而使历史上的积分变得冗余。
由于这些原因,我们选择忽略神经元的历史,并执行以下替换:
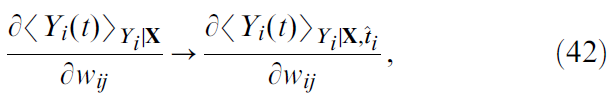
即,我们将神经元 i 的最后脉冲时间![]() 作为给定值,并询问在时间 t 处的平均脉冲如何随突触权重wij的变化而变化。因此,我们有:
作为给定值,并询问在时间 t 处的平均脉冲如何随突触权重wij的变化而变化。因此,我们有:
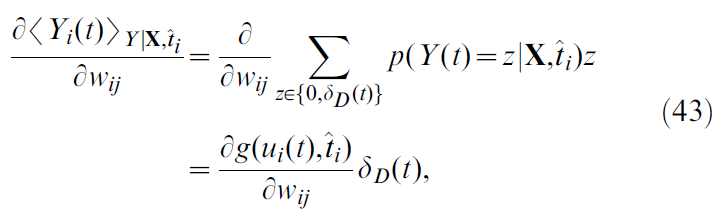
在此我们使用了神经元发放率的定义,公式20,而δD是Dirac分布。使用公式18导出:

其中![]() 是神经元 j 的脉冲序列(仅保留发放时间在神经元 i 的最后脉冲时间之后的脉冲),即
是神经元 j 的脉冲序列(仅保留发放时间在神经元 i 的最后脉冲时间之后的脉冲),即![]() ,其中Θ表示Heaviside阶跃函数(单位阶跃函数)。总结从公式38和42–44的步骤,我们终于有了:
,其中Θ表示Heaviside阶跃函数(单位阶跃函数)。总结从公式38和42–44的步骤,我们终于有了:
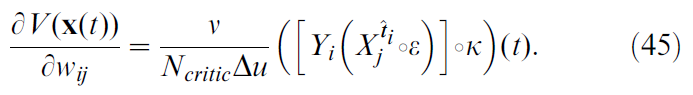
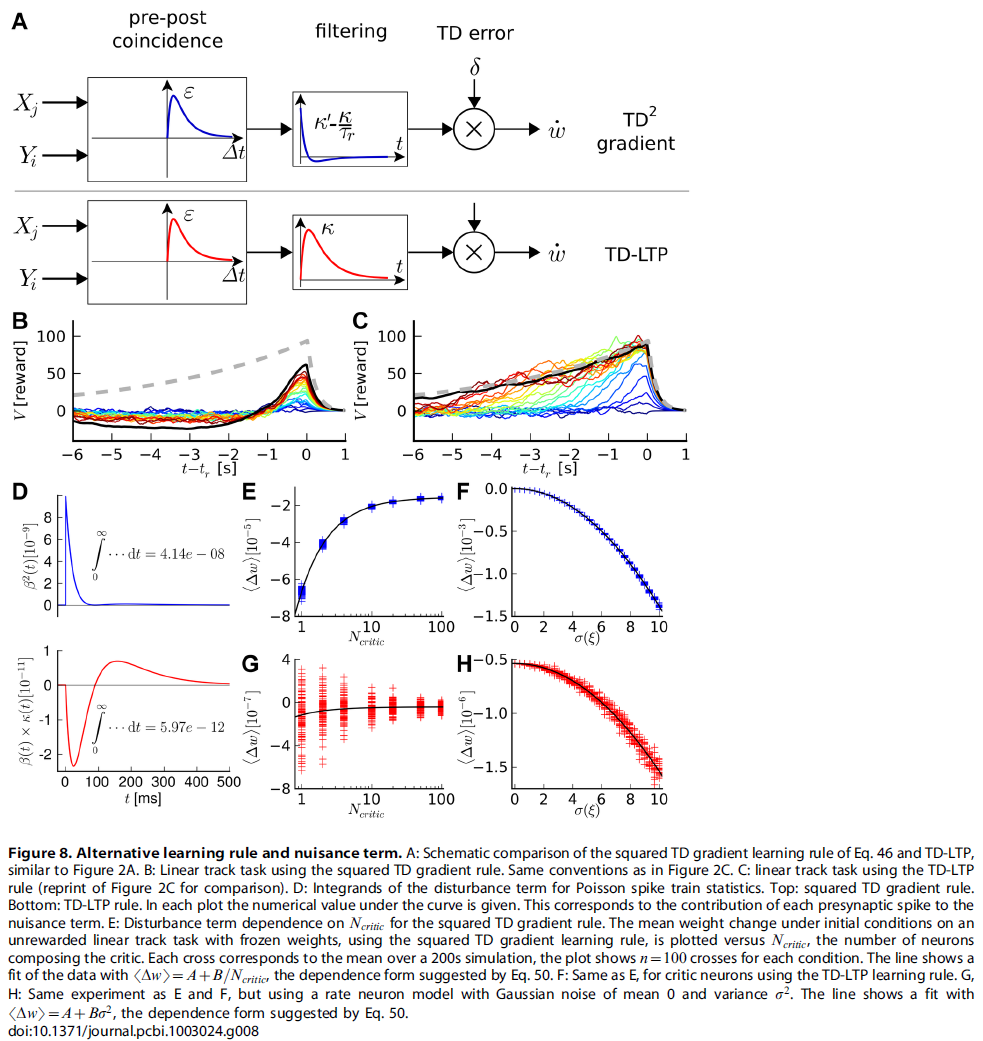
Derivation of the Squared TD Gradient Learning Rule
在Result这节,我们从公式10导出一个学习规则。我们还提出从平方TD误差(公式17)的梯度下降开始,应产生有效的学习规则。在此,我们得出这样的学习规则。结合公式10,TD误差的定义(公式5)和上一节的结果(公式45),我们发现:
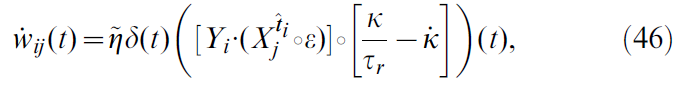
其中![]() 是突触前神经元 j 的脉冲序列。该学习规则具有与TD-LTP规则相同的一般形式(公式17):首先对"Hebbian" pre-before-post一致项进行时序滤波,然后将TD误差与一项相乘(图8A)。区别在于滤波器中的额外
是突触前神经元 j 的脉冲序列。该学习规则具有与TD-LTP规则相同的一般形式(公式17):首先对"Hebbian" pre-before-post一致项进行时序滤波,然后将TD误差与一项相乘(图8A)。区别在于滤波器中的额外![]() ,它来自
,它来自![]() 项。如图8所示,
项。如图8所示,![]() 项在K / τr上占主导地位。这是我们选择长折扣时间常数(τr = 4 s)和短(~200 ms)K核的结果。
项在K / τr上占主导地位。这是我们选择长折扣时间常数(τr = 4 s)和短(~200 ms)K核的结果。
Noise Correlation Problem
在此,我们在分析和仿真中都显示出公式46的平方TD梯度学习规则遭受噪声偏差问题。这是由于单个神经元中的噪声估计价值函数而引起的,严重到足以阻止学习。为了看到这一点,我们首先将神经元的脉冲序列Yi(t)分解为均值和噪声项,即:
![]()
其中我们定义了![]() ,其中括号<·>Y|X表示期望值,即对以突触前神经活动X为条件对critic神经元活动Y的所有可能结果进行平均。有了这个定义,我们可以重写公式46为:
,其中括号<·>Y|X表示期望值,即对以突触前神经活动X为条件对critic神经元活动Y的所有可能结果进行平均。有了这个定义,我们可以重写公式46为:
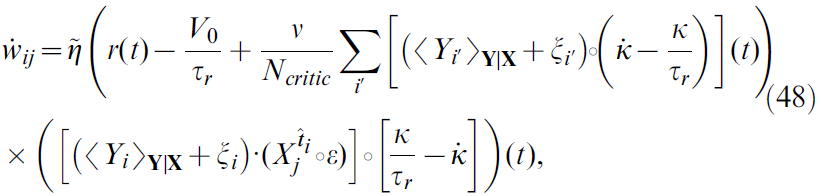
其中δ误差已显式列出(公式5, 13和12)。公式48表明,噪声中的二次项![]() 可能在学习规则中起作用。确实,分布式和事实
可能在学习规则中起作用。确实,分布式和事实![]() 和
和![]() 的使用(对于i ≠ i')得出:
的使用(对于i ≠ i')得出:
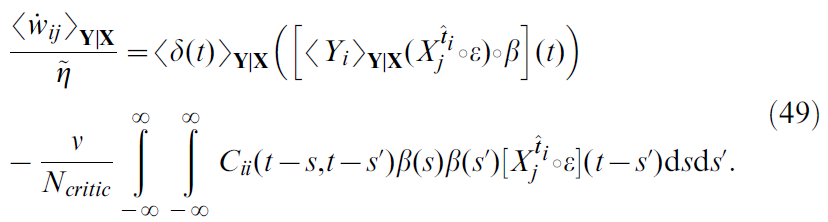
在此,我们定义了噪声项![]() 的自相关,以及
的自相关,以及![]() (简洁起见)。
(简洁起见)。
公式49右边的第一项与公式46类似,其中![]() 代替Yi(t),
代替Yi(t),![]() 代替δ(t)。实际上,这是学习规则的"均值"版本:这就是将模型中的随机脉冲神经元替换为具有类似指数激活函数的模拟无噪声单元而得到的结果。
代替δ(t)。实际上,这是学习规则的"均值"版本:这就是将模型中的随机脉冲神经元替换为具有类似指数激活函数的模拟无噪声单元而得到的结果。
第二项来自TD项δ(t)中神经元噪声与学习规则的Hebbian分量的相关性。该项是突触后神经元的自相关函数的函数。这仅包含有关突触后发放的间接信息(因此,也包含当前价值函数V(x(t))),而不包含有关奖励 r 的信息。因此,我们推测第二个要素是一个可能有问题的项,我们称其为扰动项。通过使用学习规则公式46的线性轨道仿真可以证实这一假设,如图8B所示。这些表明,学习规则无法学习任务,这与TD-LTP相反(图8C, 与图2B相同)。更准确地说,通过平方TD梯度规则学习的价值函数遭受负"拖动"项的困扰。
接下来,我们尝试使用扰动项来识别此负"拖动"。尽管没有Cii(s, s')的闭式表达式,但人们可以将Poisson过程的统计信息用作一阶近似值。在这种情况下,![]() (δD是狄拉克分布)且公式49成为:
(δD是狄拉克分布)且公式49成为:
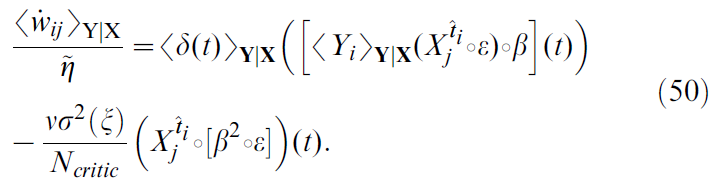
公式50右侧的最后一项表示,平均而言,神经元 j 中每个突触前脉冲都会使突触权重wij降低固定量。该量随噪声过程的方差σ2(ξi)的增加而增加,在这种情况下,非齐次泊松过程驱动SRM0神经元,而与critic神经元的数量Ncritic相反。突触前脉冲效应的时间过程由![]() 决定,其绘制在图8D的顶部面板中。单个突触前脉冲对Δwij的总干扰效应与
决定,其绘制在图8D的顶部面板中。单个突触前脉冲对Δwij的总干扰效应与![]() 随时间的积分成正比。
随时间的积分成正比。
在图8E中,我们在数值仿真中探索了扰动项对Ncritic的依赖性。公式50建议平均学习规则项应服从以下形式的关系:
![]()
其中A是学习规则中"有用"部分的结果,而B > 0包含扰动项的所有其他依赖项。我们通过在线性轨迹场景中仿真具有可变数量的critic神经元的智能体来测试Ncritic依赖性。设置与图2相似,不同之处在于权重已冻结,即我们在每个时间步骤都收集了学习规则的值,但实际上并未更新权重。在图8E中,将仿真的200s平均学习规则结果与critic神经元数量进行了比较。黑线显示通过公式51拟合的数据:两者相吻合。
从公式50中,我们看到扰动项还取决于噪声过程的方差σ2(ξ)。在不改变发放率和学习规则结果的情况下,很难控制脉冲神经元噪声过程的方差。为了避免这种困难,我们转向发放率模型,其中单个critic神经元的发放率为:
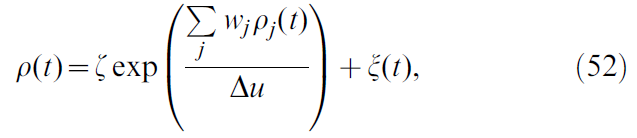
其中ζ是一个常数,在公式22中定义了位置单元发放率ρj(x(t))。图22和ξ(t)是白噪声过程。与上述步骤类似,δ2(t)上的梯度下降产生以下形式的学习规则:

由于ρ中的噪声成分,学习规则遭受了与脉冲形式相同的噪声驱动干扰。这取决于噪声的方差σ2(ξ),因此平均权重变化服从:
![]()
其中B > 0。在图8F中,我们在与图8E相同的"冻结权重"线性跟踪方案中使用基于发放率的模型和规则。这次,我们研究了平均权重变化如何随噪声方差变化。此外,通过用公式54(黑线)拟合可以很好地匹配数据,表明扰动项的行为符合预期。
Noise Correlation in the TD-LTP Rule
在上一节中,我们发现平方TD梯度学习规则中的噪声相关扰动使其无效。但是,实际上这同样适用于TD-LTP规则。确实,如果我们重复以上导致公式50的步骤(对于学习规则TD-LTP),我们得到:
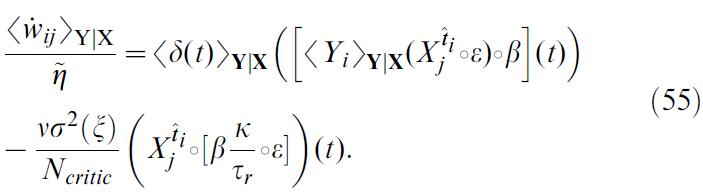
唯一的区别是扰动项的时间过程,这是![]() (对于平方TD梯度) vs
(对于平方TD梯度) vs ![]() (对于TD-LTP)。图8D显示了两个表达式的图:由于TD-LTP表达式小得多,因此将它们绘制在不同的轴上。如前所述,扰动的积分与这些时间过程成正比(如图8D所示)。TD-LTP的项比平方TD梯度规则小三个数量级。
(对于TD-LTP)。图8D显示了两个表达式的图:由于TD-LTP表达式小得多,因此将它们绘制在不同的轴上。如前所述,扰动的积分与这些时间过程成正比(如图8D所示)。TD-LTP的项比平方TD梯度规则小三个数量级。
在图8G和H中,我们分别重复图8E和F的实验。这些表明TD-LTP学习规则也受扰动项的困扰,但是它比平方TD梯度规则要小几个数量级。如图8C和Results这节中所示,这种扰动不足以防止TD-LTP正确学习价值函数V。
The Trouble with Continuous Q-Learning
在Results这节,我们断言基于Q值的算法(例如Sarsa [24]和Q-Learning [23])很难在神经网络设置中扩展到连续时间。在此,我们提出这个论点。
在离散Sarsa算法中,智能体会维持对状态-动作Q值的估计。对于遵循策略π的智能体,从时间步骤 t 上的状态st开始执行动作at,将其定义为对未来奖励R的折扣总和:
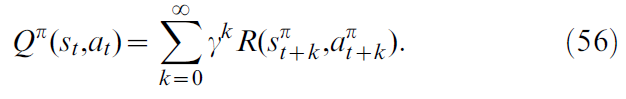
其中γ ∈ (0, 1)是一个折扣因子,而![]() 和
和![]() 表示智能体根据策略π访问的未来状态和动作。为了学习实际Qπ(s, a)的Q值近似Q(s, a),Sarsa提出在时间步骤t + 1使用以下更新规则:
表示智能体根据策略π访问的未来状态和动作。为了学习实际Qπ(s, a)的Q值近似Q(s, a),Sarsa提出在时间步骤t + 1使用以下更新规则:
![]()
其中TD误差δt被定义为:
![]()
如果要提出一个连续时间版本的Sarsa,则可以通过将状态-动作价值函数Q(x(t), a(t))重新定义为连续时间 t 来开始,类似于公式3的价值函数:
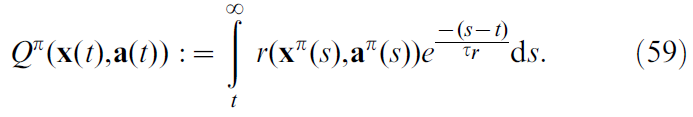
在此,τr现在扮演折扣因子γ的角色。正如我们对公式5所做的那样,我们通过取公式59的导数来定义Q值上的TD误差:
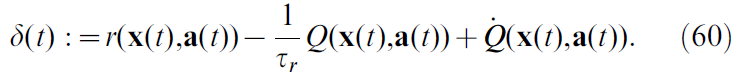
因此,要计算TD误差,需要将公式60中的三个项结合起来。我们假设奖励r(x(t), a(t))由环境给出。通常在[16,20]中,基于Q值的RL的神经网络实现由多个"动作单元"神经元 j 组成,每个神经元均调整为特定的动作aj并为状态-动作价值进行发放率编码:
![]()
其中ρj(t)是神经元 j 的发放率。因此,在那种情况下,读出价值Q(x(t), a(t))仅是读取神经元 j 的活动编码在时间 t 选择动作aj = a(t)的问题。
在那种情况下,很难读出时序导数![]() ,因为当前选择的动作一直在随时间发展。对于小Δt,我们可以近似:
,因为当前选择的动作一直在随时间发展。对于小Δt,我们可以近似:
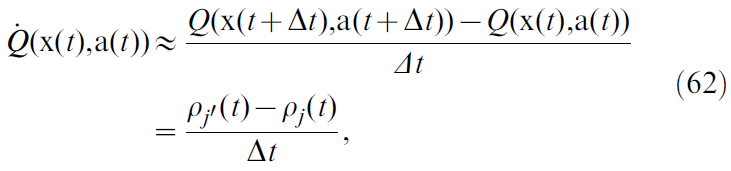
其中我们也用公式61,并确定了动作神经元j'调整为动作![]() 。
。
评估公式62中出现的困难如下。它需要一个能够跟踪两个最近动作a(t)和a(t + Δt),识别相关神经元 j 和 j' 并计算其发放率差异的系统。在生物学合理的环境中很难想象这一点。actor-critic结构的使用通过始终对基于状态的价值V(x(t))进行单一群体编码来解决此问题。
