郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
ANN是通向AI的一种流行方法,它已经通过成熟的模型,各种基准,开源数据集和强大的计算平台获得了非凡的成功。SNN是一类有前途的模型,可以模拟大脑的神经元动态,已受到脑启发计算的广泛关注,并已广泛部署在神经形态设备上。但是,很长一段时间以来,关于SNN在实际应用中的价值的争论和怀疑不断。除了从脉冲驱动处理中获得的低功率属性外,SNN的性能通常比ANN差,特别是在应用精度方面。最近,研究人员试图通过借鉴ANN的学习方法(例如反向传播)来解决此问题,以训练高精度SNN模型。随着该领域的快速发展,随着网络规模的不断扩大,SNN的结果不断取得惊人的发展,其发展路径似乎与深度学习相似。尽管这些方法赋予SNN逼近ANN精度的能力,但由于使用面向ANN的工作量和简化的评估指标,SNN的天然优势和优于ANN的方面可能会丢失。
在本文中,我们将视觉识别任务作为案例研究,以回答“什么样的工作量最适合SNN,如何评估SNN才有意义”的问题。我们使用不同类型的数据集(面向ANN和面向SNN),不同的处理模型,信号转换方法和学习算法,设计了一系列对比测试。我们提出了有关应用程序精度以及内存和计算成本的综合指标,以评估这些模型,并进行广泛的实验。我们证明了这样一个事实,即在面向ANN的工作量上,SNN无法击败其ANN对应体。而在面向SNN的工作量上,SNN可以充分发挥更好的性能。我们进一步证明,SNN在应用程序精度和执行成本之间存在折衷,这将受到仿真时间窗口和发放阈值的影响。基于这些丰富的分析,我们为每种情况推荐最合适的模型。据我们所知,这是第一项使用系统比较明确揭示“直接将工作量从ANN迁移到SNN是不明智的”的工作(尽管许多工作都在这样做),并且进行全面评估确实很重要。最后,我们强调迫切需要为SNN建立具有更多任务,数据集和指标的基准框架。
1. Introduction
ANN(LeCun, Bengio, & Hinton, 2015)能够通过深度层次结构从大量输入数据中学习高级功能。这种强大的表征在无数的AI应用程序中带来了惊人的成功。例如,研究人员报告了基于MLP或基于CNN的图像识别(He, Zhang, Ren, & Sun, 2016),语音识别(Abdel-Hamid et al., 2014),语言处理(Hu, Lu, Li, & Chen, 2014;Young, Hazarika, Poria, & Cambria, 2018),物体检测(Redmon & Farhadi, 2017),太阳辐射估计(Jahani & Mohammadi, 2018),医疗诊断(Esteva et al., 2017),游戏(Silver et al., 2016)等,基于RNN的语音识别(Lam et al., 2019),语言处理(Ghaeini et al., 2018),状态控制(Graves et al., 2016)等,有时还包括CNN和RNN的组合(Caglayan & Burak Can, 2018;Zhang, Bai, & Zhu, 2019;Zoph, Vasudevan, Shlens, & Le, 2018)。除了各种模型和学习算法之外,大数据资源(例如用于图像识别的ImageNet数据集(Deng et al., 2009))和高性能计算平台(例如GPU)进一步促进了ANN的发展。上述成功激发了对ANN特定加速器的众多研究(Chen et al., 2014;Chen, Krishna, Emer, & Sze, 2017;Jouppi et al., 2017;Yin et al., 2017)。
SNN(Ghosh-Dastidar & Adeli, 2009;Maass, 1997)紧密地模拟了生物神经回路的行为。它们以连续的时空动态和事件驱动的发放活动(0-无事件或1-脉冲事件)进行操作。由于采用了异步发放机制,SNN在基于事件的场景中显示出了优势,例如光流估计(Haessig, Cassidy, Alvarez, Benosman, & Orchard, 2017),脉冲模式识别(Wu et al., 2019)和SLAM(Vidal, Rebecq, Horstschaefer, & Scaramuzza, 2018)。此外,他们还有望解决一些有趣的问题,例如概率推断(Maass, 2014),启发式解决NP难题(Jonke, Habenschuss, & Maass, 2016)或快速解决优化问题(Davies et al., 2018),稀疏表示(Shi, Liu, Wang, Li, & Gu, 2017)和机器人技术(Hwu, Isbell, Oros, & Krichmar, 2017)。此外,SNN已广泛部署在神经形态设备中,用于脑启发计算(Davies et al., 2018;Furber, Galluppi, Temple, & Plana, 2014;Merolla et al., 2014;Shi et al., 2015)。鉴于关于SNN作为AI和神经形态计算领域中的一种计算工具的实用价值,长期以来一直存在争论(Davies et al., 2018),特别是与ANN相比。在过去的几年里,这些怀疑减慢了神经形态计算的发展,而深度学习的迅速发展使这种形态被赶上了台。研究人员试图通过诸如训练算法设计之类的手段来增强SNN,从根本上缓解这一问题。
与成熟而有效的训练算法(例如用于ANN的误差反向传播(BP))不同,SNN研究中最困难的问题之一是复杂的动态和不可分的脉冲活动导致的训练难度。即使我们使用简单的LIF(Gerstner, Kistler, Naud, & Paninski, 2014)神经元模型,该案例仍然具有挑战性。为了提高SNN应用的精度,可以通过添加横向抑制和自适应阈值(Diehl & Cook, 2015)或奖励机制(Mozafari, Ganjtabesh, Nonzari-Dalini, Thorpe, & Masquelier, 2018)来改进常规的脉冲时序依赖可塑性(STDP)无监督学习规则。其他一些工作则对经过适应的ANN进行了训练,并将其转换为SNN(Cao, Chen, & Khosla, 2015;Diehl et al., 2015;Hu, Tang, Wang, & Pan, 2018;Hunsberger & Eliasmith, 2016;Rueckauer, Lungu, Hu, Pfeiffer, & Liu, 2017;Sengupta, Ye, Wang, Liu, & Roy, 2019)。ANN中的适应通常包括移除偏差,使用ReLU激活函数(或其变体),将最大池化更改为平均池化等,以增强与SNN模型的兼容性。从ANN到SNN的转换通常会引起权重/激活归一化,阈值调整,采样误差补偿等,以保持精度。最近,借用了ANN中的监督BP学习来直接训练准确的SNN(Jin, Li, & Zhang, 2018;Lee, Delbruck, & Pfeiffer, 2016;Pengjie Gu & Tang, 2019;Shrestha & Orchard, 2018;Wu, Deng, Li, Zhu, & Shi, 2018;Wu et al., 2019)。梯度可以在执行BP时通过汇聚时间维度上的脉冲而仅沿空间方向传播,或者可以通过直接计算每个时间步骤的膜电位与脉冲活动的导数而沿时空维度传播。BP和STDP学习的组合也存在,例如在每次训练迭代中在BP更新之后应用STDP更新(Tavanaei & Maida, 2017),或者在STDP预训练之后应用BP微调(Lee, Panda, Srinivasan, & Roy, 2018)。简而言之,通过上述努力,SNN在视觉识别任务中逐渐接近ANN级别的应用程序精度。
由于缺乏针对SNN的专门基准测试工作量,因此大量工作直接将测试工作量从ANN领域迁移以验证SNN模型(Cao et al., 2015;Diehl & Cook, 2015;Diehl et al., 2015; Hu et al., 2018;Hunsberger & Eliasmith, 2016;Jin et al., 2018;Lee et al., 2016, 2018;Mozafari et al., 2018;Rueckauer et al., 2017;Sengupta et al., 2019;Tavanaei & Maida, 2017;Wu et al., 2018)。例如,将用于ANN验证的图像数据集简单地转换为脉冲版本,以进行SNN训练和测试。这似乎是合理的,因为在运行SNN时,输入数据被编码为脉冲。而ANN的原始数据集只是静态图像,即使转换为脉冲模式,也无法充分利用SNN的时空优势。此外,应用程序精度仍然是主要的评估指标,但是众所周知,就绝对识别精度而言,我们的大脑通常比当前的AI机器性能更差。这表明我们需要更全面,更公平的指标来评估脑启发的SNN。简而言之,由于工作量和评估指标不当,当前的SNN无法胜过ANN。因此,有两个悬而未决的问题,即“什么样的工作量最适合SNN,如何评估SNN才有意义”。
在本文中,我们尝试回答上述问题,并将视觉识别任务作为案例研究。在Hunsberger and Eliasmith(2016)将预训练的具有软LIF神经元和带噪活动的ANN转换为SNN的过程中,定义并比较了SNN和ANN的效率。在SNN算法领域中,这是为数不多的考虑精度以外的度量指标并研究精度与效率之间的权衡的工作之一。通过更系统的建模方法和实验分析,我们将此路径扩展到了更深入的反思。具体而言,通过使用不同领域的数据集,不同的处理模型,信号转换方法和学习算法设计一系列对比测试,我们比较了ANN和SNN(具有rate编码)的性能。我们提出了有关应用程序精度,内存成本和计算成本的综合指标,以评估这些模型并进行广泛的分析。我们证明了这样一个事实:就精度而言,在面向ANN的工作量上,SNN不能在相同的网络规模上击败ANN,但具有进行有效处理的潜力。在面向SNN的工作量上,SNN可以充分发挥更好的性能。我们进一步证明,仿真时间窗口和发放阈值的变化将在应用程序精度和执行成本之间产生折衷。基于这些分析,我们建议最适合每种情况的模型。这项工作的主要贡献概括如下:
- 通过考虑应用程序精度和执行成本之间的权衡,我们提出了急需的SNN和ANN综合评估指标。我们使用各种基准数据集,处理模型,信号转换和学习算法进行广泛的实验和分析。我们还展示了各种比较方法和可视化手段。
- 根据以上结果,我们建议针对每种工作量的最优模型,该模型提供了有见地的建模指导。
- 我们指出,尽管许多工作正在这样做,但将工作量从ANN直接迁移到SNN是不合适的,至少是不明智的。我们进一步强调,对于SNN领域而言,迫切需要创建更多面向SNN的数据集并建立具有更广泛任务的基准框架。这将阐明SNN研究的未来机会。
2. Preliminaries
在本节中,我们将提供用于视觉识别的ANN和SNN的初步知识,包括神经元模型,网络拓扑和基准数据集。
神经元是基本的计算单元,它们通过大量的突触连接形成神经网络。如果将神经网络视为图,则每个神经元和突触可分别视为节点和边缘。如上所述,有两类神经网络:ANN和SNN,将在下面进行详细说明。
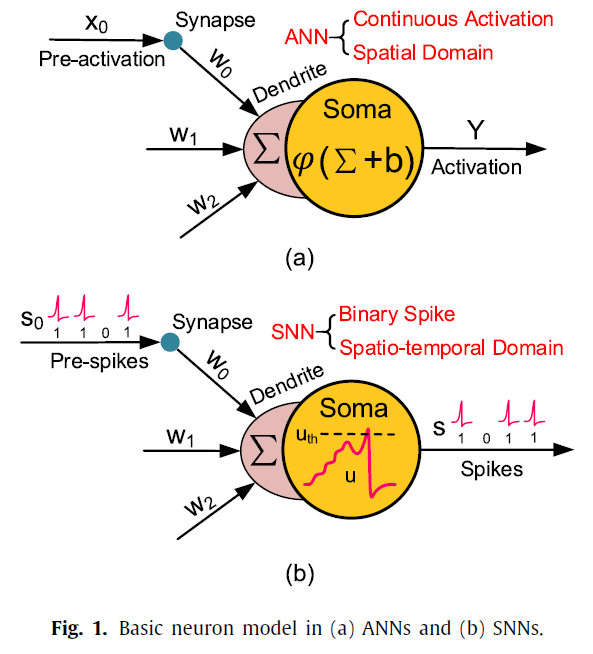
2.1. Artificial neural networks
图1(a)描绘了典型的人工神经元模型。计算过程受以下因素支配:

其中x,y,w和b分别是输入激活,输出激活,突触权重和偏差,而 j 是输入神经元的索引。ϕ(·)是非线性激活函数,例如 ϕ(x) = ReLU(x) = max(x, 0)。ANN中的神经元使用高精度和连续值编码的激活相互通信,并且仅在空间域(即逐层)中传播信息。从上面的等式可以看出,输入和权重的MAC(multiply-and-accumulate)运算是ANN中的主要操作。
2.2. Spiking neural networks
图1(b)显示了典型的脉冲神经元,与ANN神经元相比,它具有相似的结构但行为不同。 相比之下,脉冲神经元通过以二值事件编码的脉冲序列进行通信,而不是通过ANN中的连续激活进行通信。树突对输入脉冲进行积分,然后胞体进行非线性变换以产生输出脉冲序列。这种行为通常由流行的LIF模型(Gerstner et al, 2014)建模,描述为:
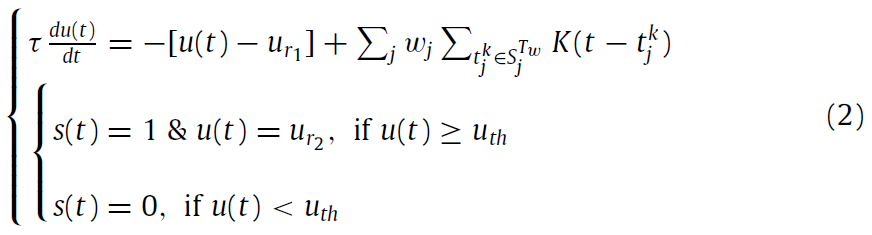
其中(t)表示时间步骤,τ是时间常数,u和s分别是膜电位和输出脉冲。ur1和ur2分别是静息电位和复位电位。wj是来自第 j 个输入神经元的突触权重,![]() 是第 j 个输入神经元的第k个脉冲在积分时间窗口Tw(总共
是第 j 个输入神经元的第k个脉冲在积分时间窗口Tw(总共![]() 的脉冲序列)内发放的时间,并且K(·)为描述时间衰减效应的核函数。uth是确定是否发放脉冲的发放阈值。除了LIF模型外,SNN中还存在其他神经元模型,例如Hodgkin and Huxley(1952)或Izhikevich(2003)的模型。但是,由于较高的复杂性,它们并未在实际的SNN模型中广泛使用。
的脉冲序列)内发放的时间,并且K(·)为描述时间衰减效应的核函数。uth是确定是否发放脉冲的发放阈值。除了LIF模型外,SNN中还存在其他神经元模型,例如Hodgkin and Huxley(1952)或Izhikevich(2003)的模型。但是,由于较高的复杂性,它们并未在实际的SNN模型中广泛使用。
与ANN不同,SNN以脉冲模式表示信息,每个脉冲神经元都经历丰富的动态行为。具体而言,除了信息在空间域中的传播之外,当前状态还受到时间域中过去的历史的紧密影响。因此,与ANN相比,SNN通常具有更多的时间通用性,但精度较低,主要是通过空间传播和连续激活来实现的。由于只有在膜电位超过阈值时才会发放脉冲,因此整个脉冲信号通常都很稀疏,并且可以通过事件驱动计算(仅当脉冲输入到达时才启用)。此外,由于脉冲是二值的,即0或1,因此如果积分时间窗口Tw等于1,则可以移除输入和权重之间的昂贵乘积(请参阅第3.5节)。由于上述原因,与具有密集计算的ANN相比,SNN通常可以实现更低的功耗。
2.3. Typical network topologies
用于构建神经网络的基本层拓扑是全连接(FC)层,循环层和卷积(Conv)层(以及池化层)。相应的网络分别命名为多层感知器(MLP),RNN和CNN。MLP和RNN仅包括堆叠的FC层,每层有/没有循环连接,分别如图2(a)和(b)所示。对于图2(c)所示的CNN,它们直接针对2D特征的处理,而不是针对MLP和RNN中的1D特征。卷积(Conv)层中的每个神经元仅接收来自上一层中所有特征图(FM)上的局部感受野(RF)的输入。每个神经元的基本计算与公式(1)或(2)相同。另外,CNN还通过输出每个RF的最大值(即最大池化)或平均值(即平均池化),使用池化层分别降低每个FM的大小,并使用FC层进行最终分类。

2.4. Benchmark datasets
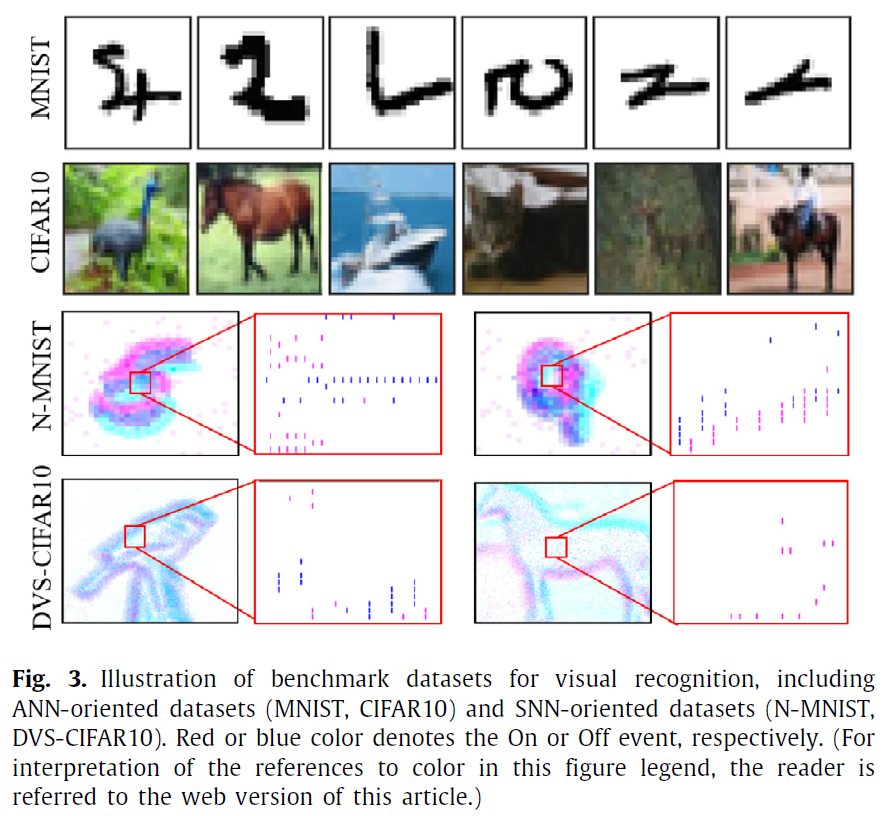
图3说明了我们用于视觉识别的两种不同类型的基准数据集。上面两行是从MNIST(LeCun, Bottou, Bengio, & Haffner, 1998)和CIFAR10(Krizhevsky & Hinton, 2009)数据集中采样的。由于它们是基于帧的静态图像,并且在ANN中得到广泛使用,因此我们将其称为面向ANN的数据集。下面两行分别从N-MNIST(Orchard, Jayawant, Cohen, & Thakor, 2015)和DVS-CIFAR10(Li, Liu, Ji, Li, & Shi, 2017)中采样。数据格式是脉冲事件,它是通过使用动态视觉传感器(DVS)扫描每个图像从上述静态数据集中转换而来的(Lichtsteiner, Posch, & Delbruck, 2008)。除了与面向ANN的数据集相似的空间信息外,它还包含更多的动态时间信息,并且脉冲事件与SNN中的信号格式自然兼容,因此我们将其称为面向SNN的数据集。
对于面向ANN的数据集,MNIST由包含60000个带标签的手写数字训练集和其他10000个带标签的数字测试集组成。每个数字样本是一个28×28的灰度图像。CIFAR10包含一个训练集,其中包含50000个带标签的训练图像以及周围环境中的自然物体和人造物体,以及其他10000个测试图像。每个样本都是32×32×3的RGB图像。
3. Benchmarking methodology
在本节中,我们首先介绍ANN和SNN域之间的信号转换。然后,我们设计了六个基准模型以及用于对比测试的训练算法,并提出了三个评估指标用于后续模型评估和比较。
3.1. Data signal conversion
通常,ANN接收基于帧的实值图像,而SNN接收事件驱动的脉冲信号。因此,有时有必要将相同的数据资源转换为其他形式以用于其他域中的处理。在这里,我们以视觉识别任务为例,主要介绍以下四种信号转换方法。
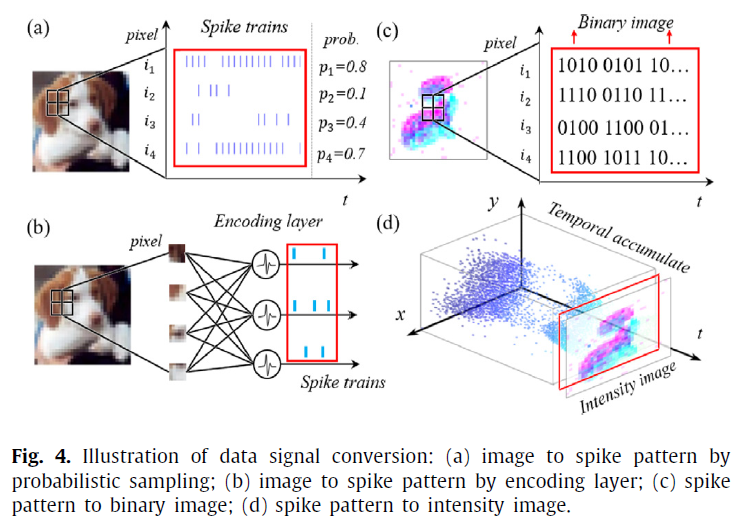
Image to spike pattern. 由于像素强度的实值信号不适用于基于脉冲的SNN,因此在面向ANN的数据集上测试SNN模型时,需要转换为脉冲序列。流行的策略之一是概率抽样。在每个时间步骤,它都会将原始像素强度(通常归一化为[0, 1])采样为二值,其中为1(发放脉冲)的概率等于强度值。采样遵循特定的概率分布,例如伯努利分布或泊松分布。例如,图4(a)中的i1神经元对应于左上角归一化强度为0.8的像素,它产生遵循伯努利分布B(0.8, T)的二值脉冲序列。这里T是给定的采样时间窗口。
在短时间窗口的情况下,上述逐元素采样通常会遭受精度损失(请参见第4.2节)。为了解决这个问题,现代工作(Esser et al., 2016)添加了一个编码层以全局生成脉冲信号,如图4(b)所示。该层中的每个神经元都接收多个像素的强度值作为输入(即,树突以正常的输入权重MAC操作在ANN模式下工作),而产生脉冲作为输出(即,具有LIF动态的Soma模式在SNN模式下工作)。尽管编码层是ANN-SNN混合层,而不是像网络中随后的层一样的完整SNN层,但其权重是可训练的,因为本文中我们对SNN的训练方法也对BP神经网络兼容(请参阅第3.4节)。由于神经元的数量可以灵活地自定义并且参数是可训练的,因此它可以适应总体优化问题,从而具有更高的准确性。
Spike pattern to image. 同样,要在面向SNN的数据集上测试ANN模型,我们需要将脉冲模式转换为基于帧的图像。存在两种可能的输出格式:(i)具有0/1像素的二值图像;(ii)具有实值像素的强度图像。将脉冲模式转换为二值图像的直观策略是首先沿时间维度从所有神经元位置扩展脉冲序列。然后,如图4(c)所示,扩展后的2D脉冲模式(位置索引 v.s. 时间)可以直接作为二值图像查看(每个脉冲事件都表示像素强度为1,否则像素强度为0)。原始记录时间长度T通常较长,可能会导致图像尺寸过大。因此,需要沿时间方向(例如,每1ms)定期汇聚或采样沿时间方向的脉冲事件。在这里,汇聚意味着如果在窗口中具有脉冲,则脉冲事件结果为1,否则为0。即使这样,将2D位置(图4(c)的左侧)展开为1D位置矢量( 图4(c)中右侧的Y轴)也会产生较大的图像尺寸。
为了转换为强度图像,需要脉冲事件的时间累积(计算脉冲数目)。图4(d)描绘了100ms内脉冲序列的累积过程。累积的脉冲数目将被归一化为具有适当强度值的像素。由于DVS的相对运动和固有噪声,生成的图像通常模糊不清,其边缘特征模糊不清。仅在以下强烈假设下才能进行此转换:每个脉冲位置都不应随着 t 的变化而移开其起始位置,否则将严重损害所得图像的质量。
3.2. ANN-oriented workloads
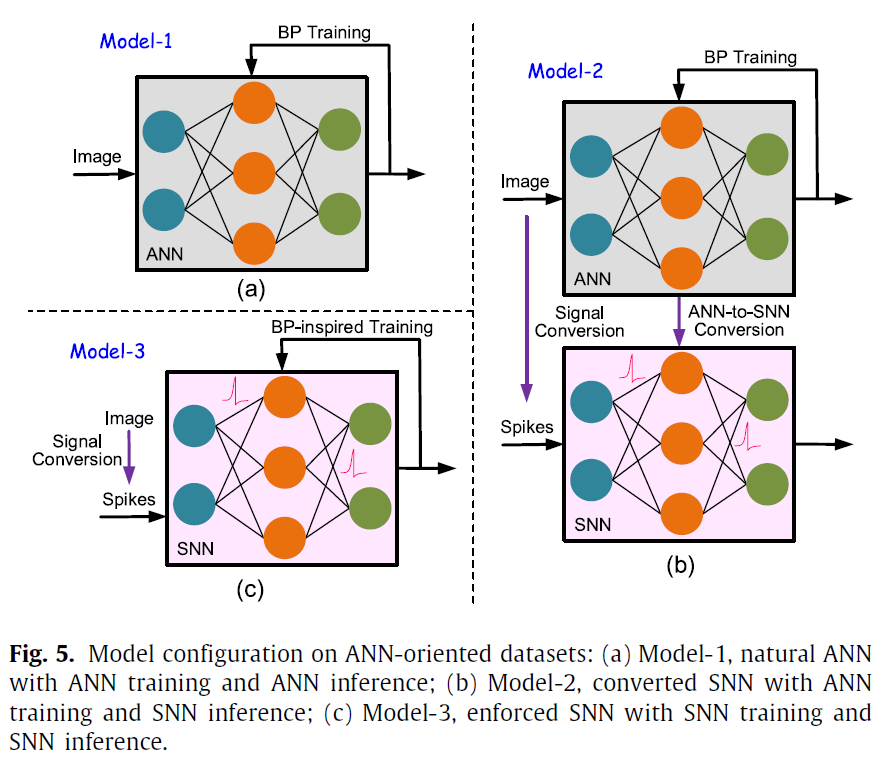
这里的“面向ANN的工作量”意味着目标是识别基于帧的数据集(例如MNIST和CIFAR10)中的图像,该图像已在ANN领域中广泛使用。为了处理这种类型的工作量,我们引入了三种基准模型。如图5(a)所示,最直接的解决方案是带有“ANN训练和ANN推断”的自然ANN。它使用强度图像在ANN模式(等式(1))中完全训练网络,然后在同一域中进行推断。训练遵循了ANN领域中使用最广泛的BP算法。
此外,SNN领域中的许多工作也使用这些数据集来测试SNN的性能(Diehl et al., 2015;Hu et al., 2018;Lee et al., 2016;Sengupta et al., 2019;Wu et al., 2018, 2019)。由于在这些情况下,网络工作在SNN模式下,因此需要将输入数据从基于帧的图像转换为脉冲事件,如图4(a)或(b)所示。信号转换后,我们进一步提供了两个建模分支。如图5(b)所示,其中首先使用BP算法在原始图像数据集上训练ANN,然后以相同的结构但不同的神经元模型,将经过预训练的ANN与其SNN对应物相适应。转换SNN在推断阶段接收带有脉冲事件的数据集变体。另一个是如图5(c)所示的强制SNN,其中直接从零开始在转换后的脉冲数据集上训练SNN模型,并在同一域中对其进行测试。如第1节所述,新兴的BP启发式训练SNN的监督算法通常比无监督算法具有更高的准确性。实际上,他们使用不同的学习方法。例如,在Shrestha and Orchard(2018)的误差反向传播框架下,突触权重和轴突延迟都是可训练的变量,Wu et al.(2018)和Wu et al.(2019)使用时空反向传播(STBP)方法直接导出每个位置和时间的梯度,而在Pengjie Gu and Tang(2019)中进一步提出了基于时间的损失函数来解决时空责任分配问题。考虑到Pytorch中的开源代码,我们选择STBP来直接训练SNN。总之,为清晰起见,面向ANN的工作量的三个基准模型表示为模型1/2/3。请注意,在本文中,我们在SNN域中使用了rate编码方案,这是因为先前的工作表明它具有更高的精度。
3.3. SNN-oriented workloads
这里的“面向SNN的工作量”意味着目标是识别无帧脉冲数据集中的图像(例如N-MNIST和DVS-CIFAR10),该图像在SNN领域得到了广泛使用。像上述面向ANN的工作量一样,这里我们还介绍了三种基准模型。前两个工作在ANN模式下(参见图6(a)),其中输入数据被转换为图像。使用常规BP算法为ANN训练模型,并在ANN领域中进行测试。从脉冲事件到图像的数据转换有两种方法:(i)通过直接接收展开的脉冲模式的二值图像;(ii)通过压缩沿时间维度的脉冲模式的强度图像,分别如图4(c)和(d)所示。图6给出了在自然SNN模式下工作的另一个基准模型。该网络使用原始的脉冲数据集直接进行了训练和测试,并且如模型3所述,学习算法仍然受BP启发。同样,面向SNN的工作量的三个基准模型表示为模型4/5/6。

3.4. Training algorithms
在上一节中,我们针对六个基准模型提到了两种训练算法:(i)ANN的BP;(ii)BP启发式SNN。BP算法被广泛应用于神经网络的训练中。这可以简单地描述为:
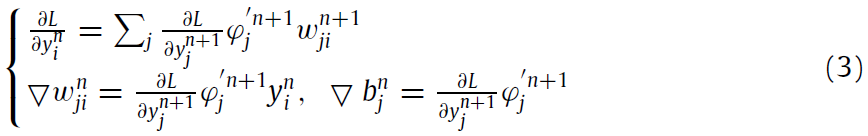
其中 i 和 j 分别是前一层n和当前层(n + 1)中的神经元索引,![]() 是层(n +1)中第 j 个神经元的激活导数,L是优化的损失函数。通常,我们可以简单地使用均方误差(MSE)作为要最小化的成本,即令
是层(n +1)中第 j 个神经元的激活导数,L是优化的损失函数。通常,我们可以简单地使用均方误差(MSE)作为要最小化的成本,即令![]() 。在这里,Y和Ylabel分别是实际输出和真实标签。
。在这里,Y和Ylabel分别是实际输出和真实标签。
如前所述,由于卓越的精度和开源代码,我们选择STBP(Wu et al, 2018, 2019)来训练我们的SNN。它基于等式(2)中原始LIF模型的迭代版本。具体来说,它产生下式:
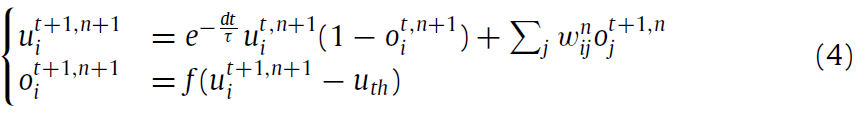
其中dt是仿真时间步骤的长度,o表示神经元脉冲输出,t和n分别是时间步骤和层索引。![]() 反映了膜电位的衰减作用。f(·)是一个阶跃函数,当x≥0时满足f(x) = 1,否则f(x) = 0。这种迭代LIF格式合并了原始神经元模型中的所有行为,包括积分,发放和重置 。请注意,为简单起见,这里我们在原始LIF模型中设置
反映了膜电位的衰减作用。f(·)是一个阶跃函数,当x≥0时满足f(x) = 1,否则f(x) = 0。这种迭代LIF格式合并了原始神经元模型中的所有行为,包括积分,发放和重置 。请注意,为简单起见,这里我们在原始LIF模型中设置![]() 和K(·) ≡ 1。在给定迭代LIF模型的情况下,梯度会沿时间和空间维度传播,因此可以如下得出参数更新:
和K(·) ≡ 1。在给定迭代LIF模型的情况下,梯度会沿时间和空间维度传播,因此可以如下得出参数更新:

为了解决不可微问题,Wu et al.(2018)引入了一个辅助函数来计算![]() 时近似阶跃函数f(·)的导数。这满足下式:
时近似阶跃函数f(·)的导数。这满足下式:

其中参数a确定梯度宽度。当x > 0时,sign(x) = 1;当x = 0时,sign(x) = 0。损失函数L衡量在给定的时间窗口T内,真实值与最后一层N的平均发放率之间的差异。同样,可以将其定义为类似于ANN中的MSE格式,即![]() 。
。
3.5. Evaluation metrics
众所周知,就绝对识别精度而言,基于SNN的大脑通常无法击败当前的基于ANN的AI系统,而真正的大脑在其他指标(例如操作效率)上性能更好。鉴于在最近的工作中,识别精度仍然是判断哪种模型(ANN或SNN)更好的主流指标,尤其是在算法研究中。这是不够公平的,因为ANN和SNN具有非常不同的特征。例如,ANN中的数据精度远高于SNN,这使得在相同网络规模下ANN更容易获得更好的识别精度。所有这些表明模型评估需要更全面的指标。除了常见的精度比较之外,我们在这里进一步介绍存储和计算成本作为补充评估指标。请注意,这仅仅是一个开始,将来还会有更多有见地的指标(请参阅第5.2节中的讨论)。
Recognition accuracy. 在这里,我们使用top-1精度。 在ANN中,此精度表示正确识别的样本的百分比。如果标签类别与激活值最大的模型预测的类别相同,则对当前样本的识别正确。在SNN中,我们首先计算给定时间窗口T内输出神经元的发放率(脉冲数目)以进行rate编码,然后根据发放率值确定预测的类别![]() 。结果精度计算与ANN相同。广泛接受的解码方法可以被定义如下:
。结果精度计算与ANN相同。广泛接受的解码方法可以被定义如下:

其中![]() 表示第t个时间步骤的最后一层N中第 i 个神经元的脉冲输出。
表示第t个时间步骤的最后一层N中第 i 个神经元的脉冲输出。
注释:在介绍内存和计算成本之前,我们需要澄清,在本文中,我们仅在推断阶段考虑成本。一方面,在等式(5)下用时空梯度传播路径训练SNN比推断阶段复杂。复杂性将削弱这项工作的可读性,因为由于各种信号转换,建模方法,工作量和评估指标,它已经很复杂。另一方面,大多数支持SNN的神经形态设备仅执行推断阶段。因此,最好将重点放在可以在当前硬件平台中快速应用的推断阶段。
Memory cost. 通常,在嵌入式设备上部署模型时,内存占用量非常重要。在ANN中,存储成本包括权重存储和激活存储。激活函数的开销被忽略,但是如果使用查找表实现,则应将其计算在内。在SNN中,存储成本包括权重存储,膜电位存储和脉冲存储。其他参数(例如,发放阈值uth和时间常数τ)可以忽略不计,因为它们可以由同一层或整个网络中的所有神经元共享。脉冲内存开销仅在脉冲发放时发生。总之,可以通过以下方式计算内存成本:

其中Mw,Ma,Mp和Ms分别表示权重,激活,膜电位和脉冲的存储成本。与由网络结构确定的Mw,Ma和Mp的静态值相比,Ms由某个时间步骤的脉冲事件的最大数量动态决定。在此为清楚起见,除1比特脉冲数据外,所有数据均假定以32比特存储。请注意,在具有数据量化的模型(Banner, Hubara, Hoffer, & Soudry, 2018;Deng, Jiao, Pei, Wu, & Li, 2018)或在专用设备上(Davies et al., 2018;Jouppi et al., 2017;Merolla et al., 2014),可以减小位宽以节省存储成本。对于一些通过矩阵/张量分解(Novikov, Podoprikhin, Osokin, & Vetrov, 2015)或稀疏化(Li, Kadav, Durdanovic, Samet, & Graf, 2016;Liu et al., 2018)技术来压缩模型而言,也可以减少存储成本。但是,这些超出了本文的范围。
Compute cost. 计算开销对于运行时延和能耗至关重要。在ANN中,计算成本主要由等式(1)中的MAC操作决定,这被广泛用于ANN加速器中(Chen et al., 2014, 2017)。在SNN中,主要的计算开销是等式(2)中的脉冲驱动输入积分。应当强调与ANN的两个区别:(i)如果Tw = 1并且K(·) ≡ 1实际上满足简单性,则由于二值脉冲输入可以移除高成本的乘法,因此树突积分没有乘法运算,即![]() (如果sj' = 1);(ii)集成是事件驱动的,这意味着如果没有收到脉冲,则不会进行任何计算。计算成本可以通过下式计算:
(如果sj' = 1);(ii)集成是事件驱动的,这意味着如果没有收到脉冲,则不会进行任何计算。计算成本可以通过下式计算:

其中Cmul和Cadd分别是乘法和加法的计算成本。
胞体中的计算开销(例如ANN中的激活函数以及SNN中的膜电位更新和发放活动)被忽略,这是神经网络设备中的常见方式(Akopyan et al., 2015;Jouppi et al., 2017)。请注意,在SNN中,Cadd在整个rate编码周期(例如T)内考虑了所有加法运算,这与脉冲事件的总数成比例。类似于存储成本评估,数据量化可以将复杂的高精度MAC替换为有效的低精度MAC,并且压缩技术(例如分解和稀疏化)可以额外减少操作量。鉴于此,它们并不是建立全面评估框架的出发点。
4. Experimental results
4.1. Experimental setup
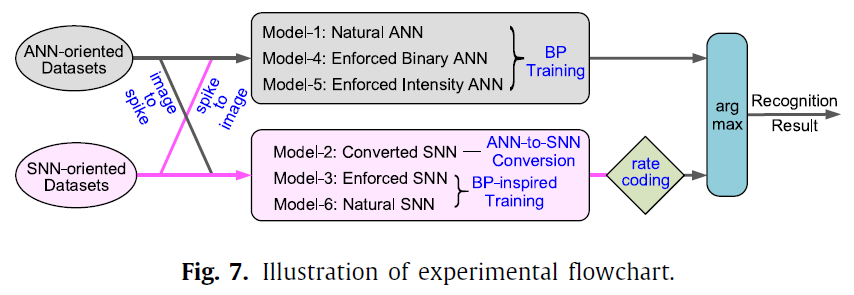
在我们的实验中,我们全面评估了几种ANN和SNN模型在不同类型的基准工作量(面向ANN和面向SNN)上的视觉识别性能。首先,为了简单起见,我们将讨论更多关于MLP和(纯)CNN的结果,并仅在最后提供面向SNN的工作量的其他模型(例如RNN和时序CNN)的结果。在面向ANN的工作量上,我们评估MNIST和CIFAR10数据集上模型1/2/3的性能。由于MLP无法处理较大规模的CIFAR10,我们仅在此数据集上显示CNN结果。在面向SNN的工作量上,我们在上述数据集的神经形态版本(即N-MNIST和DVS-CIFAR10)上评估了模型4/5/6的性能。请注意,为什么我们主要比较自己实现的模型1-6的结果,是因为我们可以轻松地控制许多因素(例如,网络结构和大小,训练技术,学习超参数等)以保证公平性。否则,由于该领域的建模多样性,很难与其他人进行公平的比较。
图7给出了整个实验流程图,表1给出了主要的网络结构。此外,表2和3分别提供了面向ANN和SNN的工作量的参数配置。由于这些工作量通常具有用于输入转换的不同编码格式,因此为了清楚起见,我们仅显示隐含层的参数配置。在所有卷积层中,我们将填充值设置为1。由于模型4的输入量较大,因此我们在此处将步长值设置为2,在其他模型中将步长值设置为1。在所有SNN模型(模型2/3/6)中,池化层中的每个单元都是一个独立的神经元,这保证了池化层的输出仍为脉冲格式。此池化配置与以前的工作不同(Wu et al., 2018, 2019)。在模型3/6中,我们使用等式(4)中描述的完整LIF神经元模型,而在模型2中,我们使用的是IF神经元模型(没有LIF中的泄漏项),这是先前转换SNN的一种流行选择(Diehl et al., 2015;Sengupta et al., 2019)。
我们在Pytorch框架中实现所有模型。在MNIST和N-MNIST数据集上,我们采用具有默认参数设置(α = 0.0001,β1 = 0.9,β2 = 0.999,ϵ = 10-8)的Adam(自适应矩估计(Kingma&Ba, 2014))优化器;而在CIFAR10和DVS-CIFAR10数据集上,我们使用SGD(随机梯度下降)优化器,其初始学习率r = 0.1,动量为0.9,其中每35个训练周期,r就衰减10倍。

4.2. Accuracy analysis
表4列出了针对面向ANN的工作量的不同模型的精度结果。在MNIST上,直接的自然ANN(模型1)可以实现最优精度,即MLP的98.60%和CNN的99.31%,因为它们与基于帧的数据集自然兼容。基于预训练的ANN(模型2)转换SNN的精度评分是可比的,但比自然ANN的精度评分稍差。由BP启发的算法在转换后的脉冲数据集上训练的强制SNN(模型3)达到最差的精度。 请注意,尽管我们还观察到强制SNN有时可能会超过转换SNN(例如在CNN结构上),但它从未比自然ANN更好。
MNIST上不同模型之间的微小差异可能是由于它是一项简单的任务。为此,我们将继续在更大的数据集(即CIFAR10)上进行测试。在这种情况下,精度差异变得更加明显,其遵循的是“自然ANN(模型1)⇒ 转换SNN(模型2)⇒ 强制SNN(模型3)”从最优到最差(即78.16% ⇒ 76.81% ⇒ 63.19%)。即使通过使用额外的编码层(图4(b))将强制SNN的精度提高到74.23%,它仍然无法击败自然ANN。
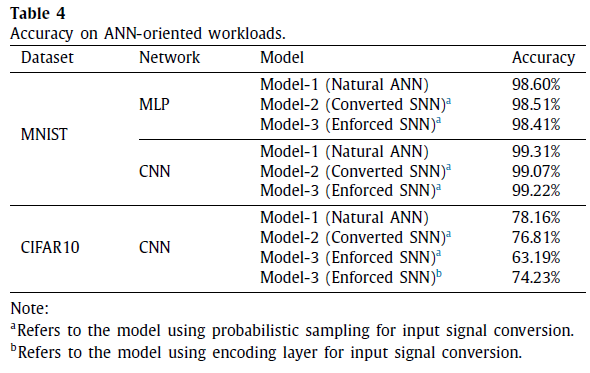
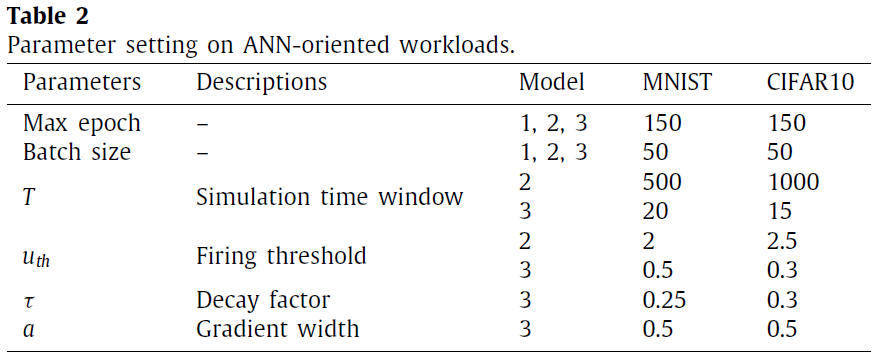
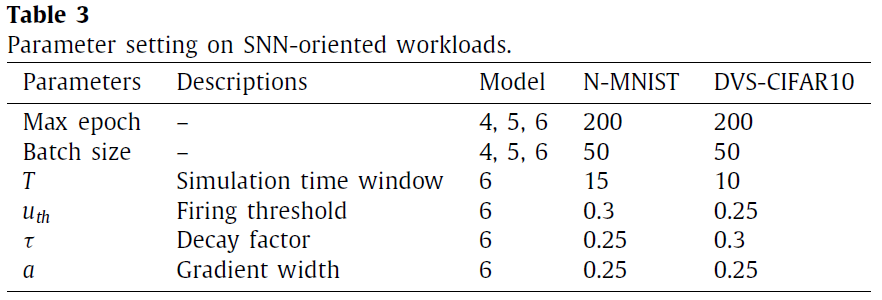
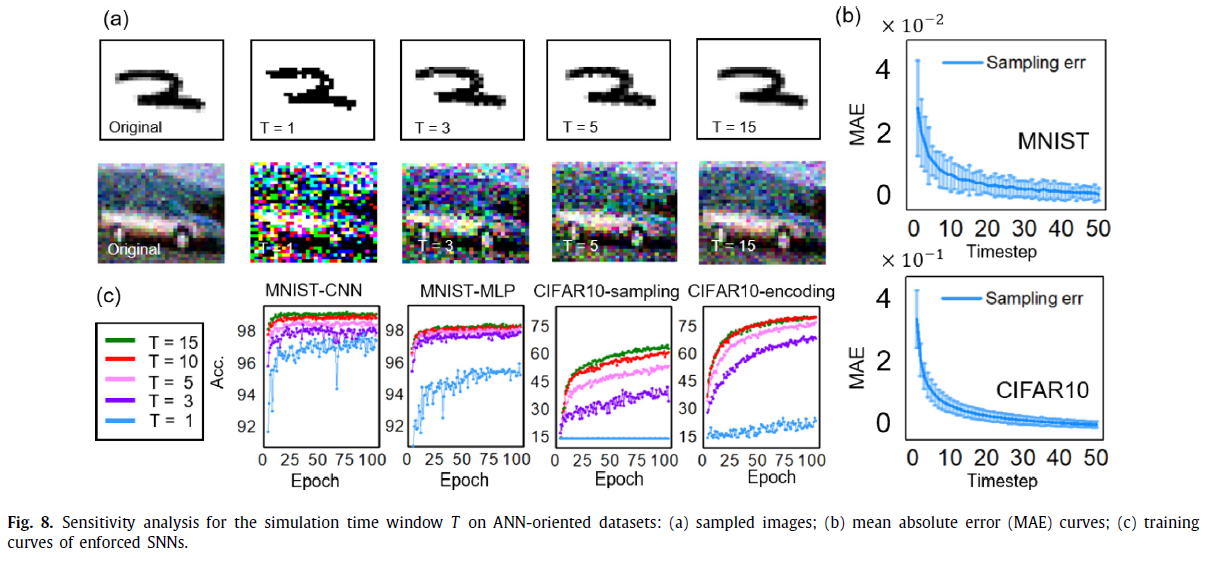
从表4中,您可以找到证据表明,转换SNN和强制SNN无法胜过自然ANN。现在,我们尝试揭示造成此精度差距的根本原因。图8(a)展示了将原始图像转换为脉冲信号以进行随后的SNN处理时的信息损失(在模型2和模型3中)。这里我们以图4(a)中的概率抽样为例。我们首先计算在仿真时间窗口T内每个像素的概率采样所产生的脉冲总数,然后将其归一化为图像后可视化脉冲数目。随着T的增加,图像变得更清晰,这表明信号转换中的精度损失较小。但是,T太大会导致较长的仿真时间。在我们的实验中,我们将T设置为15,但是,信号转换的精度损失仍然存在。图8(b)描绘了原始像素值和归一化脉冲数目之间的平均绝对误差(MAE),以及由于不确定采样导致的MAE方差。最后,我们研究了T如何影响训练收敛,这由不同T配置下的训练曲线表明。通常,更长的T会产生更快的收敛速度和更好的最终精度,这主要是由于输入信号转换期间的精度损失较小。总之,从图像到脉冲的信号转换会导致信息损失,并使SNN模型失去在面向ANN的工作量上胜过自然ANN的机会。此外,仿真时间窗口的长度T显著影响模型的收敛性。
接下来,让我们分析为什么与自然ANN相比,转换SNN也会失去精度。转换SNN基于预训练的ANN模型。为了与转换后的最终IF模型兼容,预训练的ANN通常会添加一些约束,称为约束ANN。限制条件包括移除偏差,仅允许ReLU激活函数,将最大池化更改为平均池化等(Diehl et al. (2015)以及Hunsberger and Eliasmith (2016))。这些约束通常导致精度损失,如图9(a)所示。然后,从预训练的ANN到转换SNN的转换将在上述信号转换和新出现的参数自适应(例如权重/激活归一化和阈值调整)期间遭受进一步的精度损失。在CIFAR10上,模型转换的精度损失明显大于小型MNIST。仿真时间窗口T的影响如图9(b)所示,其中较小的T会产生较大的精度损失。因此,转换SNN通常需要更长的T才能恢复精度。总之,由于受约束的预训练和有损模型转换,转换SNN无法胜过自然ANN。越来越多的最新工作使用转换SNN在面向ANN的数据集上对SNN性能进行基准测试(Diehl et al., 2015;Hu et al., 2018;Sengupta et al., 2019)。尽管这种方式表明SNN在这些面向ANN的工作量上仍然可以很好地工作,但这也使SNN失去了成为赢家的机会。
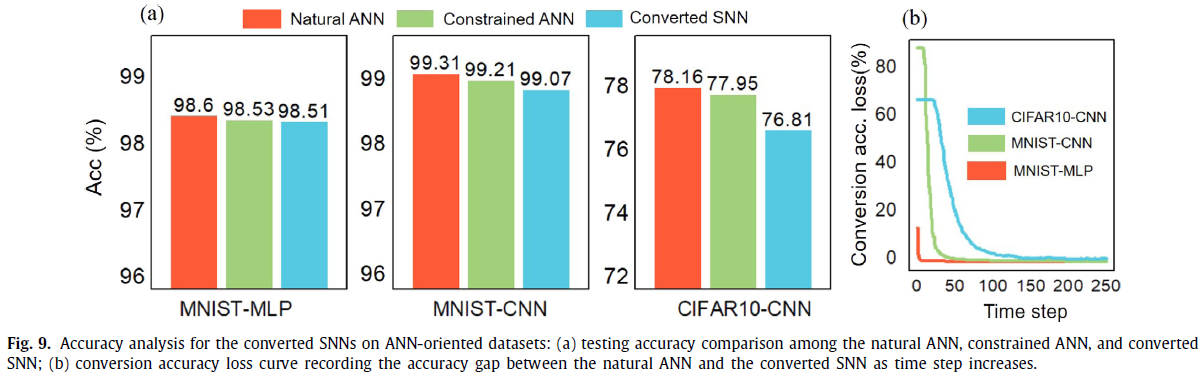
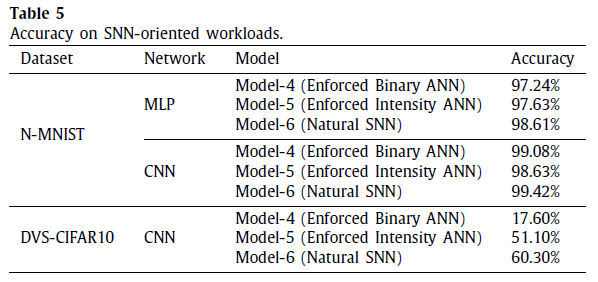
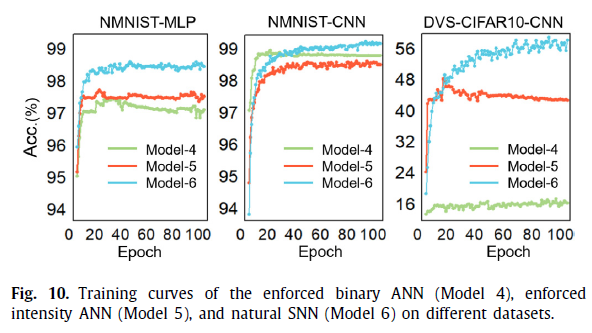
表5列出了针对面向SNN的工作量的不同模型的精度结果。在这些网络和数据集上,自然SNN(模型6)始终可以达到最优精度(N-MNIST上的MLP为98.61%,N-MNIST上的CNN为99.42%,DVS-CIFAR10上的CNN为60.30%),由于与无帧脉冲事件具有自然兼容性。在强制ANN中,基于图像强度的ANN(模型5)通常比基于二值图像的ANN(模型4)性能更好,除了在N-MNIST的CNN上偶尔出现的情况。原因与面向ANN的工作量相似,因为N-MNIST的相对简单性缩小了不同模型之间的精度差距。表5中所有模型的相应训练曲线如图10所示。总的来说,在这些面向SNN的工作量上,自然SNN的收敛能力比其他转换到在ANN领域上处理的模型更好。
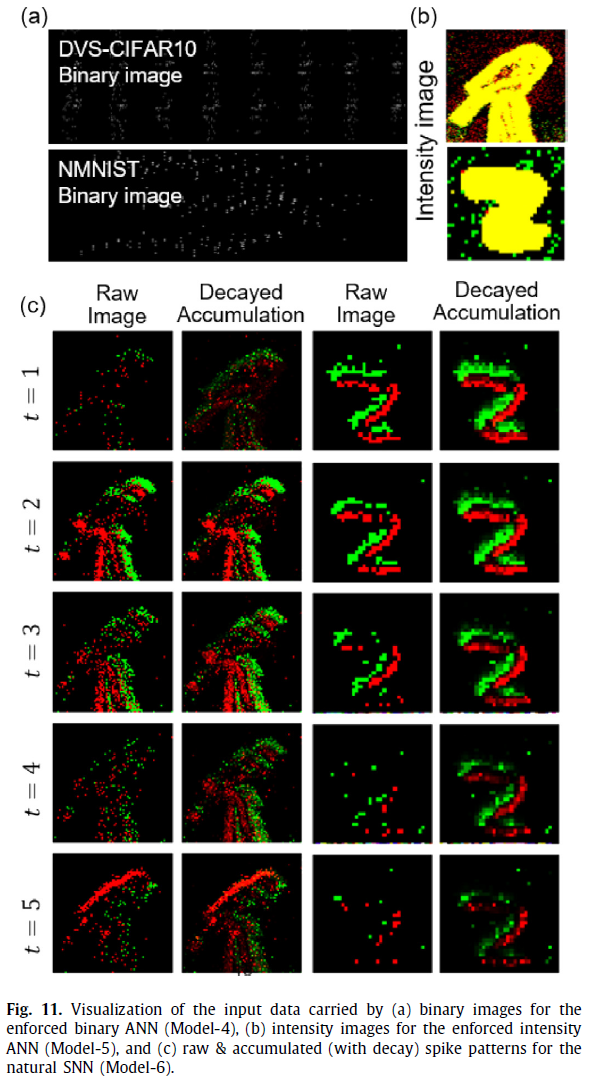
我们尝试以全面的方式解释精度结果。图11将在面向SNN的工作量上送入三个模型(模型4/5/6)的不同输入可视化。对于前两个模型,分别根据图4(c)或(d)中的信号转换方法将脉冲事件转换为二值图像或强度图像。由于模型4直接将每个脉冲模式(0/1)接收为二值图像,因此这些特征不直观且过于稀疏,如图11(a)所示。不同地,模型5沿时间维度累积每个像素的脉冲,然后将脉冲数目归一化为强度值。如图11(b)所示,可以在很大程度上保持物体轮廓,但是,详细的尖锐特征变得模糊。与上述两个基于帧的模型相比,模型6自然会收到脉冲事件。在图11(c)的奇数列中可以看到每个时间步骤的原始脉冲模式(实际上,它仍必须汇聚每3ms的脉冲事件以缩小整个仿真时间长度)。调用等式(4),如果我们为简单起见忽略了发放后的电位复位,则SNN中的膜电位实际上会以时间衰减因子累计所有先前的输入。为了模拟最终送入到膜电位上的等效输入,我们绘制了每个时间步骤的先前脉冲模式的衰减累积,并在图11(c)的偶数列中显示了它们。可以看出,自然SNN(模型6)能够很好地保留脉冲事件中包含的细节特征,这是解释为什么它可以在面向SNN的工作量上表现更好的原因之一。
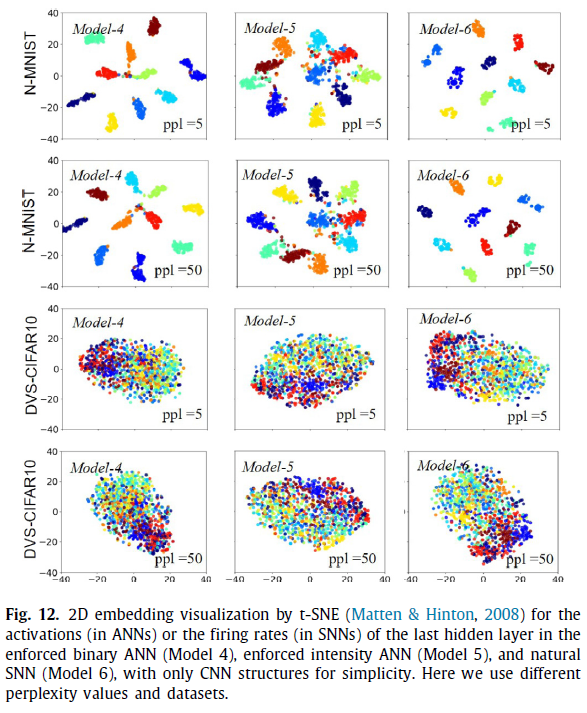
除了可视化输入信号外,我们还可视化了激活(在ANN中)和发放率(在SNN中),以比较这三个模型的识别能力。图12提供了由非线性降维算法,t分布随机邻居嵌入(t-SNE)生成的2D嵌入结果(Matten&Hinton, 2008)。它可以将高维嵌入投影到低维嵌入,以进行数据可视化。由于t-SNE对困惑度(ppl)值的敏感性,我们根据Matten and Hinton(2008)建议的范围在每个数据集上采用两个ppl值(ppl = 5,ppl = 50)。通过这种方式,我们将最后一个隐含层的256维激活或发放率投影到二维。颜色相同的点具有相同的标签,颜色不同的点属于不同的类别。因此,相同颜色的更多集中点和不同颜色的更多发散点反映了模型更好的分类性能。尽管不同的ppl设置确实会导致模式变化,但是随着ppl值的变化,三个模型之间的相对聚类效果仍然保持一致。在N-MNIST上,三个模型都能够将来自不同类别的数据投影到不同的点簇中。与模型4和模型5相比,模型6可以更紧凑地吸引每个类中的点,并进一步推动类,这表明模型6性能最优。在DVS-CIFAR10上,所有模型都存在较大的聚类重叠。这意味着无法获得与简单的N-MNIST任务类似的精度评分。显然,从模型4到模型6的聚类效果逐渐增强。结合N-MNIST和DVS-CIFAR10上的结果,可以确认模型6在面向SNN的工作量上的优越性,这与表5中的结果一致。请注意,表4和5中已经展示了模型的分类性能,而t-SNE模拟只是可视化的一种辅助方式,可以更好地理解(不是本文的重点)。这就是为什么我们仅在面向SNN的数据集上显示模型4/5/6的表5的t-SNE结果,而不重复模型1/2/3的表4的相同实验的原因。
4.3. Cost analysis
在本小节中,我们计算表4和表5中所有模型的存储和成本。成本计算根据等式(8)–(9)进行。结果示于表6,其中成本值是推断期间所有测试样品的平均结果。

Memory cost analysis. 对于所有ANN模型,存储成本主要包括权重存储和激活存储。为了简单起见,这里我们省略了一些可能的中间变量(例如部分和),因为它们与硬件架构设计(例如数据流映射)有关。我们还忽略了偏差的存储成本,因为它仅占总内存的一小部分,尤其是在CNN中。在面向ANN的工作量上,SNN的存储成本与ANN相当。具体来说,SNN中的膜电位与激活中的膜电位相同,但是SNN的额外脉冲仍会消耗内存。幸运的是,脉冲是二值格式,即只有一位,其存储成本可以忽略不计。对于面向SNN的工作量,除了模型4(强制二值ANN)之外,可以得出类似的结论。模型4的输入大小比模型5/6的输入大小大得多(请参见图4),这大大增加了特征图的大小和内存/计算成本。请注意,如果考虑偏差存储,则ANN的存储成本将增加,尤其是在MLP网络的情况下。
Compute cost analysis. 与由具有最大内存成本的时间步骤确定的内存成本不同,计算成本考虑了整个仿真时间窗口(T)中所有时间步骤的总操作。观察到两个主要结论:(1)所有SNN都可以免除昂贵的乘法运算(在上述Tw = 1的条件下),这对降低功耗和能耗非常有帮助;(2)SNN中的加法运算的数目可能超过ANN或至少在相同的水平,因为SNN需要处理持续时间,即T,以在rate编码方案下完成实际任务。第一个结论不包括带编码层的模型3,其第一层在ANN-SNN混合模式下工作,从而导致额外的乘法运算和更多的加法运算。第二个结论与常识相反,即SNN的发放活动非常稀疏,即应该是低成本的,这有点违反直觉。正确的是,每个时间步骤的脉冲事件都很稀疏,这导致基于SNN的设备具有低功耗特性。但是,此处的计算成本是由所有时间步骤中的总活动确定的,它更接近于能耗而不是功耗。
在面向ANN的工作量上,由于提到了rate编码的时间窗口,因此SNN的加法运算量要高于ANN。具体来说,我们发现强制SNN的模型3比转换SNN的模型2消耗更少的加法。这是因为模型2需要更长的时间窗口(最多66.7倍,请参见表2)来恢复模型转换后的精度损失。在面向SNN的工作量上,强制二值ANN的模型4会消耗较大的计算成本,这是因为前面提到了较大的特征大小。自然SNN的模型6免除了昂贵的乘法;此外,它比强制强度ANN的模型5的额外消耗更少,与模型1/2/3的情况相比,它的观察结果相反。这表明神经形态数据集的脉冲序列(例如N-MNIST和DVS-CIFAR10)比转换后的面向ANN的数据集(例如MNIST和CIFAR10)要稀疏得多。因此,神经形态数据集上的SNN模型可以抑制由rate编码窗口引起的额外成本。
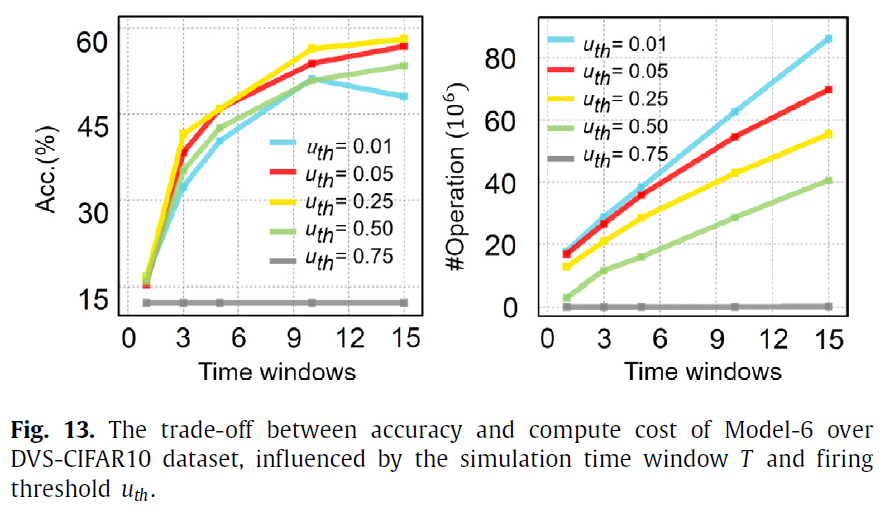
通过以上分析,我们知道SNN中的发放活动将极大地影响精度和计算成本。因此,我们以DVS-CIFAR10数据集上的模型6为例,进一步进行如图13所示的敏感性分析。我们忽略了内存成本,因为它仅取决于某个时间步骤的脉冲事件的最大数量,而不是整个时间窗口内的总脉冲。考虑两个因素,即T和uth。我们可以得到两个观察结果:(1)显然,较大的T通常可以带来较高的精度,但会导致更多的计算成本;(2)适当大的uth可以同时提高精度和计算成本。太小的uth将产生更多的脉冲,这不仅会增加计算成本,而且由于模式可分辨性较低,还会降低模型精度。尽管太大的uth可以使脉冲明显稀疏,但会损害网络的表达能力,从而降低精度。
4.4. Additional comparison
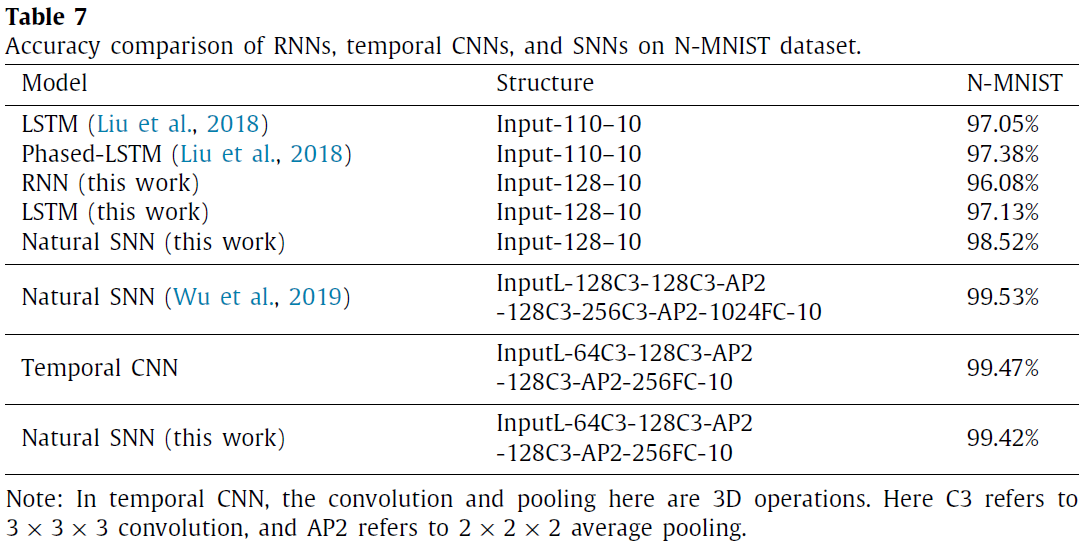
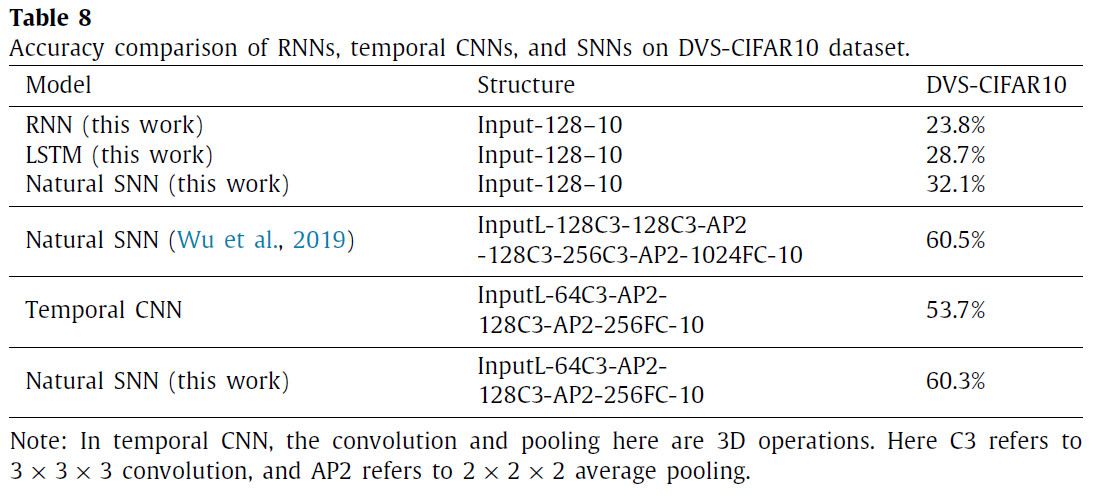
除了SNN之外,神经网络家族中的RNN和时序CNN都还能够处理时间信息。因此,这里我们提供了N-MNIST和DVS-CIFAR10数据集上RNN,时序CNN和SNN的额外比较,如表7-8所示。我们在这两个数据集上实现非脉冲版本的普通RNN,LSTM和时序CNN模型,以及脉冲版本的SNN。我们还参考其他报告的结果。我们详细介绍了所有网络结构,以帮助您理解。
首先,我们的SNN结果比以前报道的参考文献要先进,这得益于我们选择的高级训练算法和信号转换方法。与最近的工作相比(Wu et al., 2019),精度的降低幅度较小是因为我们使用的网络较小,并且未采用神经元归一化和基于投票的分类技术。我们想强调的是,这项工作的重点是提供一种全面的基准测试方法,而不是击败以前的工作,因此我们放弃了可能的优化技术。我们的LSTM结果与先前的工作一致(Liu et al., 2018),这也反映了我们实施的可靠性。
其次,关于SNN和RNN(LSTM)/时序CNN模型之间的比较,似乎自然的SNN模型(模型6)具有更大的潜力来表现更好。尽管我们的自然SNN的效果比N-MNIST上的时序CNN稍差,但我们应该注意,由于3D卷积,后者的权重参数要大得多。我们尽力解释SNN在神经形态工作量方面的优势:(1)历史信息的时间整合可以自然地更好地保持稀疏数据的详细特征(见图11);(2)每个神经元的泄漏和阈值发放机制可以协同帮助去除多余信息,从而保持有用的功能(Evangelos et al., 2015;Gutig, 2016)。
5. Conclusion and discussion
5.1. Brief summary
在这项工作中,我们设计了全面的实验,以回答“什么样的工作量最适合SNN,如何评估SNN才有意义”的问题。具体来说,我们使用不同的基准数据集(面向ANN和面向SNN),处理模型(ANN和SNN),信号转换方法(图像⇔脉冲)以及学习算法(直接和间接的监督训练)进行广泛的工作量分析。考虑到应用程序精度与内存/计算成本之间的折衷,提出了综合评估指标。
通过各种比较,可视化和敏感性研究,我们给出了以下建模见解:
- 在简单的面向ANN的工作量(例如MNIST)上,模型3(强制SNN)是更好的选择,它具有可接受的精度和较低的计算成本(无需昂贵的乘法运算,而加法运算稍多)。
- 处理更复杂的面向ANN的工作量(例如CIFAR10),模型1(自然ANN)优先保持模型的精度。尽管它需要乘法运算,但加法运算最少。
- 在面向SNN的工作量上,模型6(自然SNN)是具有较高精度和较低计算成本的最优选择。
一方面,由于在ANN预训练和SNN转换过程中的有损信号转换以及参数自适应方面存在额外的限制,因此与原始ANN相比,转换SNN一方面会降低精度。另一方面,与强制SNN相比,由于恢复精度的时间窗口更长,效率也会下降。在SNN建模中,面向SNN的数据集的稀疏活动显著降低了计算成本,并且适当增大发放阈值可以提高精度和计算成本。此外,我们在以下讨论中首次指出,尽管有许多工作在进行,但直接迁移ANN工作量以评估SNN是不明智的,并且SNN的基准测试框架涵盖了更广泛的任务,数据集和指标是紧迫需要的。
5.2. Future opportunities
Coding schemes and learning algorithms. SNN的应用精度和执行成本主要取决于编码方案和学习算法。在rate编码之外研究新的编码方案是一个有吸引力的话题,它可以在不影响表达能力(即保持精度)的情况下缩小时间窗口(即,加快响应速度并降低计算成本)。我们还需要强大的学习算法来进一步探索这些编码方案的潜力。此外,修改简单的MSE损失函数也是进一步改进网络分类性能的一种有前途的方法。所有这些方向都有助于以更少的计算成本来训练SNN或将当前模型扩展到更大的规模,例如关于ImageNet级别的任务(Deng et al., 2009)。
Datasets, benchmarks, metrics, and applications. 在这项工作中,我们强调指出,使用面向ANN的基准数据集来直接测试SNN是不明智的。此外,我们提出一个有趣的问题是,当前面向SNN的数据集是否足够神经形态,即它们是否可以帮助充分探究SNN的特征。在Iyer, Chua, and Li(2018)中,作者声称即使在神经形态数据集(例如N-MNIST)上,SNN也无法胜过ANN,并且当前神经形态数据集中的时间信息并不重要。我们发现他们的比较有点不公平,因为他们使用的ANN的网络规模大于SNN基准。但是他们仍然为神经形态社区提出一个有趣的问题:什么是良好的神经形态数据集以及如何建立它?尽管存在用于神经形态数据集的不同类型的生成方法(Li et al., 2017;Mueggler, Rebecq, Gallego, Delbruck, & Scaramuzza, 2017;Orchard et al., 2015;Serrano-Gotarredona & Linares-Barranco, 2015),使用类似DVS的设备将静态图像数据集扫描到脉冲版本仍然是当前的普遍做法。但是,这可能不是利用SNN的时空处理能力的最优方法。
其次,大多数现有基准都是基于视觉任务,尤其是图像识别。它们不足以展示SNN在处理时间或不确定信息方面的能力。我们需要为SNN提供更多的基准测试任务,以推动研究创新。除了视觉识别应用程序外,还可以处理具有固有时间属性的听觉和语言信息,或者找到不需要高精度求解方法的优化问题的快速解决方案,例如,它们非常适合SNN。再举一个例子,大容量视频中的对象检测(Binas, Neil, Liu, & Delbruck, 2017;Zhu, Yuan, Chaney, & Daniilidis, 2018)有望从SNN的事件驱动范式向低成本发展中受益匪浅 。此外,还需要超出建议的识别精度和存储/计算成本的更多评估指标。例如,如何评估时间关联能力,存储能力,容错能力和设备上的实际运行效率都是很有趣的。
此外,识别图像只是大脑可以执行的众多任务中的一项。应该进行广泛的努力来探索SNN的更多函数潜力。一个有希望的方向是从更全局的角度研究网络动态。SNN中的每个神经元都是具有发放活动的动态模型,该模型与ANN有所区别,后者可以在时域中带来丰富的响应行为。例如,一个SNN可以存储以亚稳态编码的多个场景,并可以在不同刺激下输出相应的响应轨迹。即使是一个刺激,改变输入脉冲的顺序也会产生完全不同的响应。因此,如何通过外界刺激精确地控制反应轨迹对于记忆行为的探索尤为重要。总体而言,SNN具有巨大的行为空间,值得在将来进行深入分析。在本文中,我们仅提供一些要点进行讨论。预计将进行更多调查,需要整个社区的努力。