参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
1. 作用:在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
2. 参数描述:
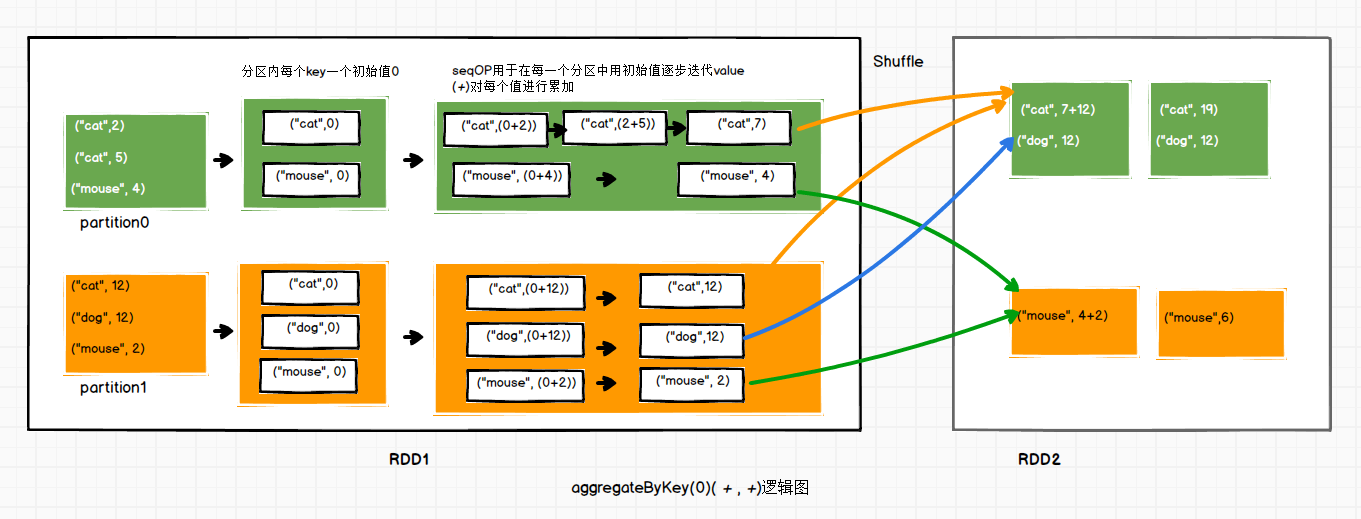
(1)zeroValue:给每一个分区中的每一个key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp:函数用于合并每个分区中的结果。
案例:
// 创建一个有2个分区的RDD
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2) // pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[12] at parallelize at <console>:24 pairRDD.collect // res27: Array[(String, Int)] = Array((cat,2), (cat,5), (mouse,4), (cat,12), (dog,12), (mouse,2))
// 计算每个分区相同key对应值的加和,最后求结果之和 pairRDD.aggregateByKey(0)(_+_,_+_).collect // res28: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6))
以下是pairRDD.aggregateByKey(0)(_+_,_+_)的逻辑图。
注意:
RDD内只是逻辑上的数据,不存物理数据。一个Partition对应一个Task,Task负责处理运算对应分区的数据。
aggregateByKey有Shuffle的过程,创建RDD的时候有多少个Partition,新生成的RDD就有多少个Partition。