一、爬虫的基本原理
1.百度是个大爬虫.
2.模拟浏览器发送http请求--(请求库)(频率,cookie,浏览器头。js反扒,app逆向)(抓包工具)--->从服务器取回数据---->
解析数据--(解析库)(反扒)--->入库(存储库,)
3.爬虫协议(详情见网站:https://www.cnblogs.com/sddai/p/6820415.html)
Robots协议也称为爬虫协议、爬虫规则、机器人协议,是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。
“规则”中将搜索引擎抓取网站内容的范围做了约定,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取,而网络爬虫可以据此自动抓取或者不抓取该网页内容。
如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,
哪些不对搜索引擎开放。
二、requests模块
1.urllib 内置库,发送http请求,比较难用,requests是基于这个库的写的
2.requests,应用非常广泛的请求库
3.request-html库(request,bs4,lxml等二次封装)
4.Usr-Agent:请求头中标志是什么客户端发送的请求
5.Regerer:上次请求的地址
2.1 发送 get请求
1. 发起请求
使用http库向目标站点发送请求,即发送一个Request
Request包含 :请求头、请求体等
2. 获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3. 解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
4. 保存数据
数据库
文件
三、请求与响应
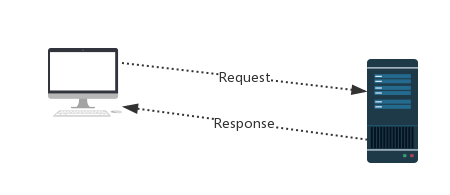
http协议:http://www.cnblogs.com/linhaifeng/articles/8243379.html
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发送来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四、Request
1 请求方式
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后
2 请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页。通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
3 请求头
User-agent:请求头中如果没有user-agent客户端配置
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息
一般做爬虫都会加上一个请求头
4 请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、响应对象方法
import requests respone=requests.get('https://www.autohome.com.cn/shanghai/') # respone属性 # print(respone.text) # 文本内容 # print(respone.content) # 二进制 # print(respone.status_code) # 状态码 # print(respone.headers) # 响应头 # print(type(respone.cookies) ) # cookie对象 RequestsCookieJar from requests.cookies import RequestsCookieJar # print(respone.cookies.get_dict()) # cookie对象转成字典 # print(respone.cookies.items()) # print(respone.url) # 请求地址 # print(respone.history) # 当你访问一个网站,有30x,重定向之前的地址, print(respone.encoding) # 网站编码 # respone.encoding='gb2312' # print(respone.text) # # #关闭:response.close() # from contextlib import closing # with closing(requests.get('xxx',stream=True)) as response: # for line in response.iter_content(): # pass ## 解析json # import json # json.loads(respone.text) # respone.json()