系列目录
内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
ES 本质上是一个支持全文搜索的分布式内存数据库,特别适合用于构建搜索系统。ES 之所以能有非常好的全文搜索性能,最重要的原因就是采用了倒排索引。倒排索引是一种特别为搜索而设计的索引结构,倒排索引先对需要索引的字段进行分词,然后以分词为索引组成一个查找树,这样就把一个全文匹配的查找转换成了对树的查找,这是倒排索引能够快速进行搜索的根本原因。
背景及常见术语
背景
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 将所有的功能打包成一个单独的服务,可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
面向文档
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档。Elasticsearch 不仅存储文档,而且 索引 每个文档的内容,使之可以被检索。在 Elasticsearch 中,我们对文档进行索引、检索、排序和过滤—而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
几个关键词
- 实时
- 分布式
- 搜索
- 分析
优势
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
常见术语
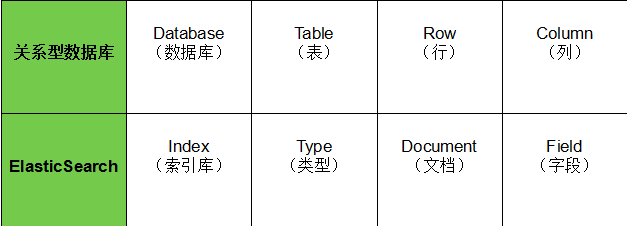
- Index:Elasticsearch的Index相当于数据库的Table
- Type:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type--有点类似于消息队列一个topic下多个group的概念)
- Document:Document相当于数据库的一行记录
- Field:相当于数据库的Column的概念
- Mapping:相当于数据库的Schema的概念(个人感觉这个解释不太合理,说白了其实就是静态类型映射)
- DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
- cluster:一组拥有共同的 cluster name 的节点
- node:集群中的一个 实例
- primary shard: 索引的子集,索引可以切分成多个分片,分布在不同的节点,分片对应的是lucene中的索引
- replica shard:代表索引副本,Elasticsearch可以设置多个索引的副本,副本具有以下作用:
提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
提高Elasticsearch的查询效率,Elasticsearch会自动对搜索请求进行负载均衡。 - allocation:将分片分配给某个节点的过程,包括分配主分片或副本。如果是副本,还包括从主分片复制数据的过程
客户端
节点客户端(Node client)
节点客户端作为一个非数据节点加入到本地集群中。换句话说,它本身不保存任何数据,但是它知道数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。
传输客户端(Transport client)
轻量级的传输客户端可以将请求发送到远程集群。它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。
注意⚠️
两个 客户端都是通过 端口并使用 Elasticsearch 的原生 传输 协议和集群交互。集群中的节点通过端口 彼此通信。如果端口没有打开,节点将无法形成一个集群。
客户端作为节点必须和 Elasticsearch 有相同的 主要 版本;否则,它们之间将无法互相理解。
应用场景
如果要将应用程序和 Elasticsearch 集群进行解耦,传输客户端是一个理想的选择。例如,如果您的应用程序需要快速的创建和销毁到集群的连接,传输客户端比节点客户端”轻”,因为它不是一个集群的一部分。
类似地,如果您需要创建成千上万的连接,你不想有成千上万节点加入集群。传输客户端( TC )将是一个更好的选择。
另一方面,如果你只需要有少数的、长期持久的对象连接到集群,客户端节点可以更高效,因为它知道集群的布局。但是它会使你的应用程序和集群耦合在一起,所以从防火墙的角度,它可能会构成问题。
RESTful API with JSON over HTTP
可以使用 RESTful API 通过端口 和 Elasticsearch 使用类GraphQL语义进行通信,可以用任何一个 web 客户端访问 Elasticsearch
java - spring接入方式
https://spring.io/projects/spring-data-elasticsearch