1、简要说明介绍
字符集和校对规则
字符集是一套符号和编码。校对规则是在字符集内用于比较字符的一套规则。
MySql在collation提供较强的支持,oracel在这方面没查到相应的资料。
不同字符集有不同的校对规则,命名约定:以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束
校对规则一般分为两类:
binary collation,二元法,直接比较字符的编码,可以认为是区分大小写的,因为字符集中'A'和'a'的编码显然不同。
字符集_语言名,utf8默认校对规则是utf8_general_ci
mysql字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和连接级。
具体来说,我们系统使用的是utf8字符集,如果使用utf8_bin校对规则执行sql查询时区分大小写,使用utf8_general_ci 不区分大小写。不要使用utf8_unicode_ci。
如create database demo CHARACTER SET utf8; 默认校对规则是utf8_general_ci 。
Unicode与UTF8
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.
UTF8字符集是存储Unicode数据的一种可选方法。mysql同时支持另一种实现ucs2。
详细说明
字符集(charset):是一套符号和编码。
校对规则(collation):是在字符集内用于比较字符的一套规则,比如定义'A'<'B'这样的关系的规则。不同collation可以实现不同的比较规则,如'A'='a'在有的规则中成立,而有的不成立;进而说,就是有的规则区分大小写,而有的无视。
每个字符集有一个或多个校对规则,并且每个校对规则只能属于一个字符集。
binary collation,二元法,直接比较字符的编码,可以认为是区分大小写的,因为字符集中'A'和'a'的编码显然不同。除此以外,还有更加复杂的比较规则,这些规则在简单的二元法之上增加一些额外的规定,比较就更加复杂了。
mysql5.1在字符集和校对规则的使用比其它大多数数据库管理系统超前许多,可以在任何级别进行使用和设置,为了有效地使用这些功能,你需要了解哪些字符集和 校对规则是可用的,怎样改变默认值,以及它们怎样影响字符操作符和字符串函数的行为。
2、校对规则一般有这些特征:
两个不同的字符集不能有相同的校对规则。
每个字符集有一个默认校对规则。例如,utf8默认校对规则是utf8_general_ci。
存在校对规则命名约定:它们以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束
确定默认字符集和校对
字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和连接级。
数据库字符集和校对
每一个数据库有一个数据库字符集和一个数据库校对规则,它不能够为空。CREATE DATABASE和ALTER DATABASE语句有一个可选的子句来指定数据库字符集和校对规则:
例如:
CREATE DATABASE db_name DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci;
MySQL这样选择数据库字符集和数据库校对规则:
· 如果指定了CHARACTER SET X和COLLATE Y,那么采用字符集X和校对规则Y。
· 如果指定了CHARACTER SET X而没有指定COLLATE Y,那么采用CHARACTER SET X和CHARACTER SET X的默认校对规则。
· 否则,采用服务器字符集和服务器校对规则。
在SQL语句中使用COLLATE
•使用COLLATE子句,能够为一个比较覆盖任何默认校对规则。COLLATE可以用于多种SQL语句中。
使用WHERE:
select * from pro_product where product_code='ABcdefg' collate utf8_general_ci
Unicode与UTF8
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.Unicode码可以采用UCS-2格式直接存储.mysql支持ucs2字符集。
UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。
UTF8字符集(转换Unicode表示)是存储Unicode数据的一种可选方法。它根据RFC 3629执行。UTF8字符集的思想是不同Unicode字符采用变长字节序列编码:
· 基本拉丁字母、数字和标点符号使用一个字节。
· 大多数的欧洲和中东手写字母适合两个字节序列:扩展的拉丁字母(包括发音符号、长音符号、重音符号、低音符号和其它音符)、西里尔字母、希腊语、亚美尼亚语、希伯来语、阿拉伯语、叙利亚语和其它语言。
· 韩语、中文和日本象形文字使用三个字节序列
3、校对集
MySQL5.5.8中共有字符集39,校对集195个
#显示所有的校对集
Show collation
#显示所有的字符集
show character set
所以一个字符集对应多个校对集,即同样的一个字符集有多重排序规则
比如一个utf8的字符集共有22中排序规则
Utf8字符集默认的校对集为utf8_general_ci
通过show collation like ‘utf8\_%'
即可查看
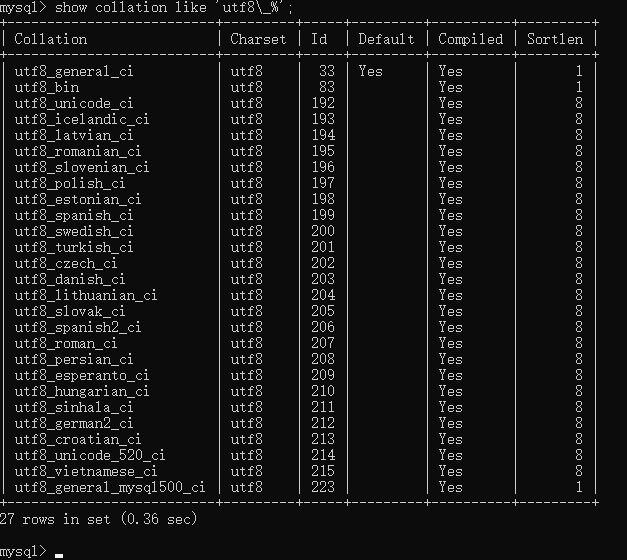
注意:
utf8_general_ci 按照普通的字母顺序,而且不区分大小写(比如:a B c D)
utf8_bin 按照二进制排序(比如:A排在a前面,B D a c)
文本为转载