1. Self-supervising Fine-grained Region Similarities for Large-scale Image Localization
ECCV2020
1.1 Thinkings
这篇论文的motivation就在于目前公开的benchmarks 仅能 提供带有噪声的GPS坐标标签,以提供learning image-to-image similarities的弱监督。为了解决这个问题,论文的作者提出了一种自监督、细粒度的image-to-region similarities的学习方式,去充分挖掘difficult positive images和其子区域的潜力。
整篇论文的亮点有二:首先是这篇论文将self-supervision、self-knowledge distillation成功地扩展到了geo-localization的领域,其提出的自监督标签Query-gallery similarities of top ranking gallery images强调了difficult positive images对于网络训练的重要性;其次是这篇论文通过更进一步研究,将自监督标签从image-to-image换成了更细粒度的image-to-region。这样能够很好地缓解仅靠noisy GPS labels划分positive和negative images,而由于视角原因可能GPS很近的图像有区域并没有重合这种弱监督标签的问题。
总体来说论文的contributions如下:
- 将自监督和自我知识蒸馏扩展到geo-localization领域,提出了一种self-supervised similarities可以在不断地迭代中自我蒸馏网络,提高网络性能。
- 更进一步地将这个自监督的标签从image-to-image扩展到了更细粒度的image-to-region。
- 性能达到了sota,并且拥有很强的泛化能力(仅在Pitts30k-train上训练,就能在Tokyo 24/7和 Pitts250k-test上分别达到85.4和90.7R@1)
1.2 Principle Analysis

上图便是整个网络的训练过程,初始的时候考benchmarks提供的GPS label提供弱监督以训练网络,然后再用训练完成的网络输出自监督的image-to-region similarities labels去训练下一代的网络,然后就这样一代一代的自我蒸馏,最终完成训练。
1.2.1 Self-supervising Query-gallery Similarities
有了上面整个网络训练的过程,我们只需要知道作者提出的这个自监督标签如何计算,就能明白整篇论文的原理了,这里博主先介绍论文提出的image-to-image的自监督标签。
S θ 1 ( q , p 1 , ⋯ , p k ; τ 1 ) = s o f t m a x ( [ < f θ 1 q , f θ 1 p 1 > / τ 1 , ⋯ , < f θ 1 q , f θ 1 p k > / τ 1 ) S_{ heta_1}(q,p_1,cdots,p_k; au_1) = softmax([<f^q_{ heta_1}, f^{p1}_{ heta_1}>/ au_1, cdots, <f^q_{ heta_1}, f^{pk}_{ heta_1}>/ au_1) Sθ1(q,p1,⋯,pk;τ1)=softmax([<fθ1q,fθ1p1>/τ1,⋯,<fθ1q,fθ1pk>/τ1)
其中, < , > <,> <,>代表向量点乘, p 1 ⋯ p k p^1 cdots p^k p1⋯pk代表topk的positive images, τ 1 au_1 τ1代表第一代训练的蒸馏温度, θ 1 heta_1 θ1代表第一代训练的网络参数。
训练下一代的损失函数项如下:
L s o f t ( θ 2 ) = l c e ( S θ 2 ( q , p 1 , ⋯ , p k ; 1 ) , S θ 1 ( q , p 1 , ⋯ , p k ; τ 1 ) ) L_{soft}( heta_2) = l_{ce}(S_{ heta_2}(q, p1, cdots, pk;1), S_{ heta_1}(q, p_1, cdots, p_k; au_1)) Lsoft(θ2)=lce(Sθ2(q,p1,⋯,pk;1),Sθ1(q,p1,⋯,pk;τ1))
其中, l c e ( , ) l_{ce}(,) lce(,)代表交叉熵。
1.2.2 Self-supervising Fine-grained Image-to-region Similarities
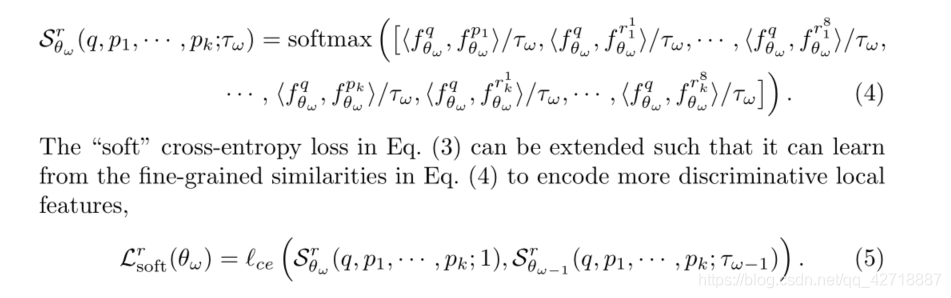
从image-to-image到更细粒度的image-to-region公式都是一样的,就多加入了几个region,从
r
1
⋯
r
8
r_1cdots r_8
r1⋯r8分别是图像的 4 half regions and 4 quarter regions,所以公式博主就直接截图上去了,不再手敲了。
1.3 Trash Talk
这篇论文成功的将自监督和自我知识蒸馏扩展到geo-localization领域,这个创意是真滴比较可以。但是,后文提出将image-to-image扩展到image-to-region的region划分属实有点随意了,用一张图像的4 half regions and 4 quarter regions很难代表真正有意义的区域,并且有些有意义的区域形状还不一定是矩形。这一点如下图所示,从后面消融实验就能看出来,这样一张Query Image让两种方法都出错了,这就是因为这幅图的有意义区域除了那个墙以外,还有被树遮挡住了一部分的房子,而两者均对房子没啥兴趣。
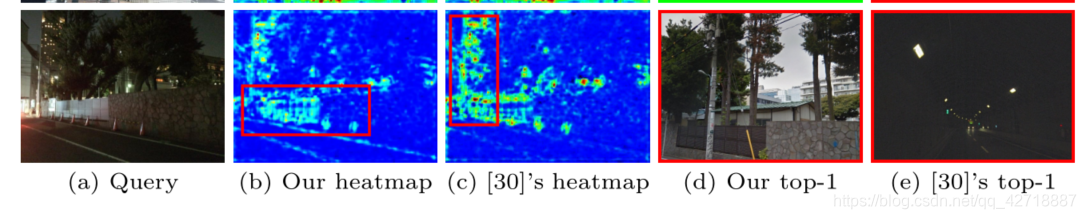
这一点mark一下,我感觉我后续可以把这种自监督和自蒸馏的过程融合到空间attention之中去进行改进。