一、概述
这里主要简单分析一个丢包重传并恢复的场景,通过不同的设置让这个相同的场景分别触发RACK重传和前向重传,通过对比说明以下问题:
Forward Retransmit可以产生只有重传标记的数据包,也可以产生同时具有重传标记和SACK标记的数据包,注意这里说的这些数据包是没有Lost标记的,这是前向重传与之前介绍的快速重传及其变种的差异,进而会对in_flight的统计产生影响。
Recovery状态,FACK会利用一个dup ACK来前向标记丢失的数据包。
RACK可以利用重传在时间域来标记丢失的数据包,而重传报文和初传报文在系列号空间重叠,因此传统的基于系列号空间的标记方法不能利用重传标记丢失的数据包。
RACK并没有实现协议中的"reordering settling"定时器。
RACK目前linux4.4限制只能在Recovery状态或者Loss状态下使用,但是时间域标记的RACK在原理上与传统的系列号空间标记Lost的原理是相互独立的,所以RACK实际上也可以单独使用
RACK重传和前向重传的基本原理前面已经介绍过,这里不再重复介绍。
二、wireshark示例
业务场景:server端建立连接后休眠1s,然后以3ms为间隔连续写入9个数据包,每个数据包的大小都是50bytes。client正常接收到了第1个数据包和第8个数据包,另外第6个数据包的重传client也没有接收到。下面两个示例中,我黑底白字高亮标记出来的数据包是传输过程中丢失的数据包。路由设置如下
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno initcwnd 12 ssthresh lock 30 #参考本系列destination metric文章******@Inspiron:~$ sudo ethtool -K lo tso off gso off #关闭tso gso以方便观察cwnd变化
快速恢复过程中拥塞窗口cwnd的PRR更新过程前面已经介绍过多次了,不再详细逐包解释,重点关注sack标记的变化、RACK利用重传标记lost等相关点。
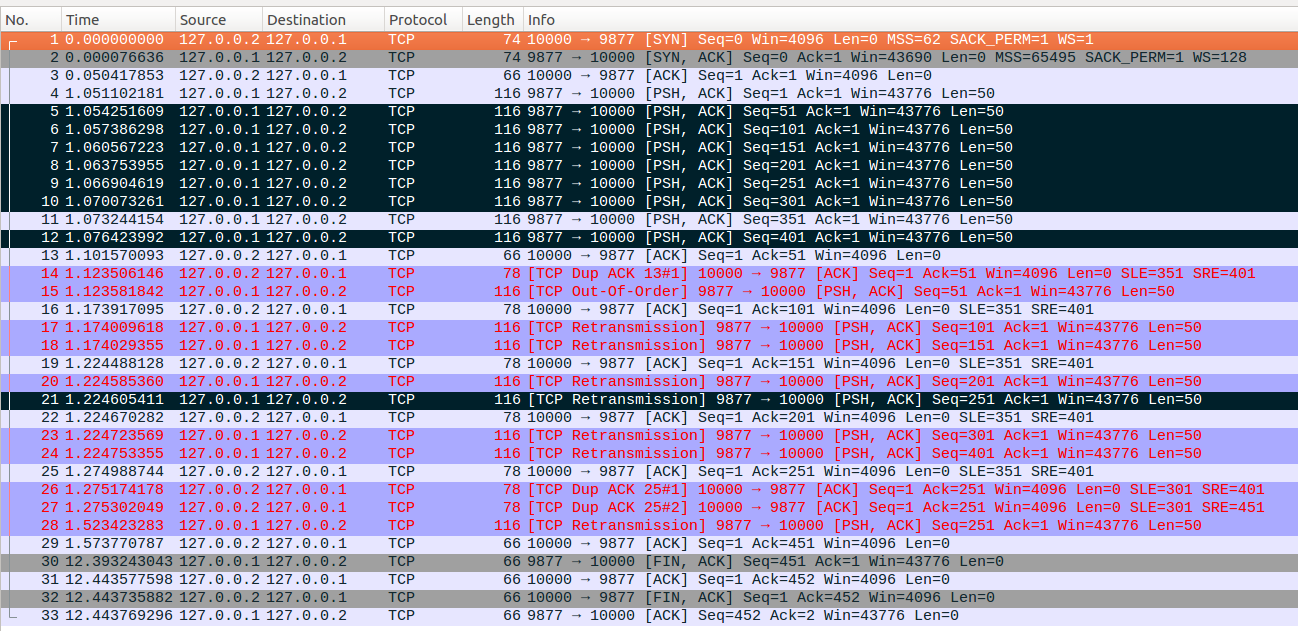
1、Forward Retransmit
设置tcp_recovery=0关闭RACK重传,我们先来看一下前向重传的效果。
No1-No3:client与server端三次握手建立连接。初始ssthresh=30,初始cwnd为12,拥塞控制处于Open状态。
No4-No12:server端在休眠1000ms后,连续发送9个数据包,每个数据包的发送间隔为3ms,其中只有No4和No11数据包顺利到达client端,其余数据包丢失。
No13:client对于No4报文响应,确认接收到了No4,server端更新cwnd=13。
No14-No15:No14是对应No11报文的ACK确认包,可以看到这是一个dup ACK,此时fackets_out=7,dupthresh=3,fackets_out-dupthresh=4。因此server端把No5、No6、No7、No8这四个数据包标记为lost。接着server端先重传No5数据包,发出No15后,packets_out=8,sacked_out=1, lost_out=4, retrans_out=1,ssthresh=6,cwnd = 4,server端直接从Open状态切换到Discovery状态。
No16-No18:server端收到No16这个确认包后,拥塞控制进行更新,允许server端发出两个数据包,因此server端接着重传No6和No7数据包,即对应No17和No18,packets_out=7,sacked_out=1, lost_out=3, retrans_out=2,ssthresh=6,cwnd = 5。
No19-No21:server端收到No19后,拥塞窗口更新后,因此server端重传No8数据包,即对应No20,此时cwnd还允许发出新的数据包,但是被标记为lost的4个数据包都已经进行了重传,同时server端也没有新数据等待发送,因此server端进行前向重传,重传No9数据包,对应No21。注意这里No21报文并没有被标记为lost状态,但是前向重传后,No21会被标记为Retrans,这就意味着着一个数据包要统计为两个in_flight,这是前向重传与其他重传方式的差异点。发出No21后,packets_out=6,sacked_out=1, lost_out=2, retrans_out=3,ssthresh=6,cwnd = 6。注意这里retrans_out已经比lost_out高了。
No22-No23:server端收到No22后,cwnd更新允许发出一个数据包,此时继续前向重传No10数据包,对应No23,传输完No23后packets_out=5,sacked_out=1, lost_out=1, retrans_out=3,ssthresh=6,cwnd = 6。
No24:server端在收到这两个数据包的时候已经没有等待发送的新数据了,而前向重传已经传到了最高的SACK块,虽然No12数据包也丢失了,但是No12是系列号空间的尾包不会触发前向重传,因此server端cwnd更新后虽然允许传输数据包,但是TCP暂时没有可以传输的数据包。No24是partial ACK会重启RTO定时器,定时时间大约为250ms。packets_out=4,sacked_out=1, lost_out=0, retrans_out=2,ssthresh=6,cwnd = 6。
No25:No25通过SACK确认了前向重传的No23数据包,这时候No23数据包的状态则是同时具有Retrans和Sack标记,另外注意这个确认包是一个dup ACK,FACK下这个dup ACK会触发继续向前标记一个lost数据包,因此server端会把No9报文标记为lost,然后尝试重传的时候,发现实际No9数据包已经重传过了,因此不再进行重传尝试。最终packets_out=4,sacked_out=2, lost_out=1, retrans_out=2,ssthresh=6,cwnd = 4。
No26-No33:No24处设置的RTO定时器超时后,server端TCP进入loss状态,并把尾包No11也标记为loss状态,No10因为已经被SACK确认,因此不会标记为lost。接着server端进行RTO超时恢复过程,并在最后关闭连接。
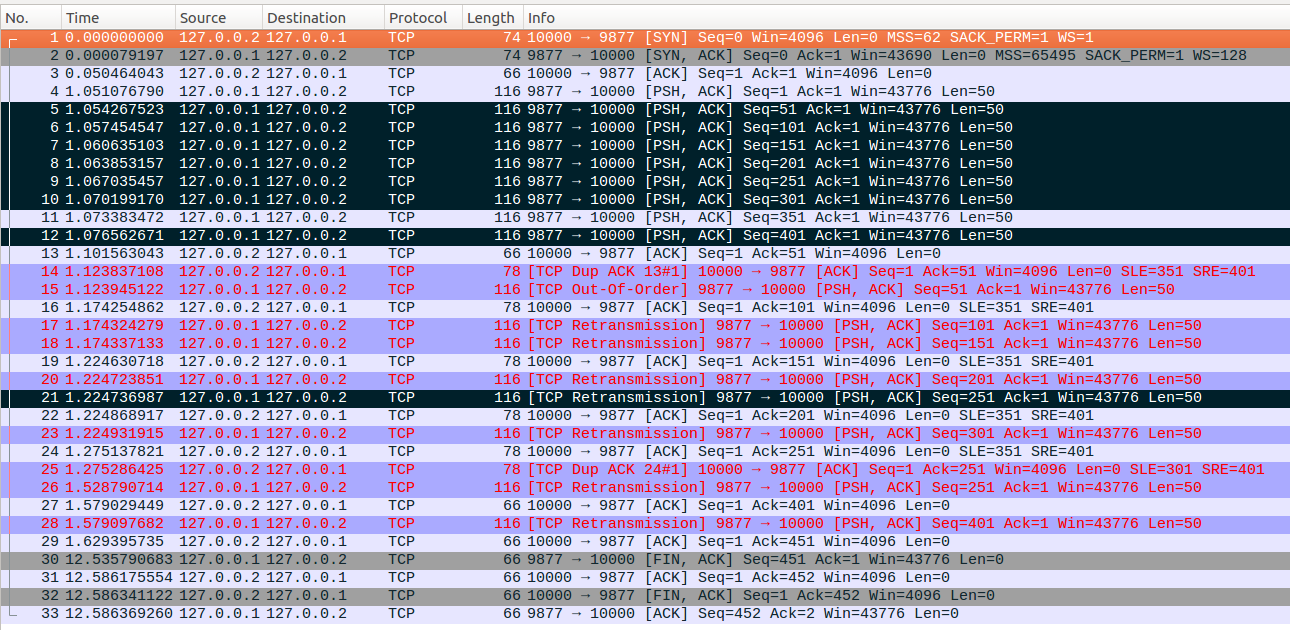
2、rack
设置tcp_recovery=1打开RACK重传后,我们先来看一下RACK重传的效果,注意与前向重传对比。
No1-No15:与上面示例相似,不再重复介绍
No16-No18:No16这个报文确认了No15这个重传报文,No15报文发出的时间点为1.123581s,server端在收到No16这个报文的时候,RACK会把1.122581s之前发送的还未被ack number或者SACK确认的数据包标记为lost,因此No9、No10、No12报文都会被标记为lost状态,可以RACK的一个重大改进是可以利用重传报文来标记lost了。cwnd更新后,server端发出两个数据包No17和No18。发出No18后packets_out=7,sacked_out=1, lost_out=6, retrans_out=2,ssthresh=6,cwnd = 2。
No19-No24:No19-No21这一组和No22-No24的处理都是类似的,收到partial ACK后,更新cwnd=in_flight + 2,然后发出两个新的数据包,这种场景前面介绍过多次,不再赘言。
No25:server端在收到No25报文后,重启RTO定时器,定时时间大约为250ms。
No26-No27:注意这两个报文通过SACK确认了No23和No24,虽然No23和No4都位于丢失的No21后面,但是三个数据发送的时间差并没有达到1ms,因此RACK不能标记No21丢失。
No28-No33:RTO定时器超时后,这里可以看到linux实现的RACK并没有实现"reordering settling"定时器功能,server端进入Loss状态,恢复后关闭了TCP连接。