一、拥塞控制的相关算法
早期的TCP协议只有基于窗口的流控(flow control)机制而没有拥塞控制机制,因而易导致网络拥塞。1988年Jacobson针对TCP在网络拥塞控制方面的不足,提出了“慢启动(Slow Start)”和“拥塞避免(Congestion Avoidance)”算法。1990年Jacobson又做了两个修正。在这二十来年的发展过程中,与拥塞控制相关的有四个比较重要的版本:TCP Tahoe、TCP Reno、TCP NewReno和TCP SACK。TCP Tahoe是早期的TCP版本,它包括了3个最基本的算法-“慢启动”、“拥塞避免”和“快速重传(Fast Retransmit)”,但是在Tahoe版本中对于超时重传和快速重传的处理相同,一旦发生重传就会开始慢启动过程。TCP Reno则在TCP Tahoe基础上增加了“快速恢复(Fast Recovery)”算法,针对快速重传作出特殊处理,避免了网络拥塞不严重时采用“慢启动”算法而造成过度减小发送窗口尺寸的现象。TCP NewReno对TCP Reno中的“快速恢复”算法进行了修正,它考虑了一个发送窗口内多个数据包丢失的情况。在Reno版中,发送端收到一个新的ack number后就退出“快速恢复” 阶段,而在NewReno版中,只有当所有的数据包都被确认后才退出“快速恢复”阶段。TCP SACK关注的也是一个窗口内多个数据包丢失的情况,它避免了之前版本的TCP重传一个窗口内所有数据包的情况,包括那些已经被接收端正确接收的数据包, 而只是重传那些被丢弃的数据包。传统的TCP拥塞控制算法主要就由慢启动、拥塞避免、快速重传、快速恢复这4个基础算法组成,这四个基础算法在RFC5681规范中进行了描述。
后续我们将会分别对这些拥塞控制相关的算法做介绍,在介绍这些拥塞控制的相关算法之前我们先介绍一下拥塞控制中的数据包守恒原则和linux中拥塞控制的背景知识,以方便后面进行更进一步的介绍。
另外需要注意一下reno这个词在不同语境下的不同含义,它可以指reno这个TCP版本,也可以指原始BSD版本中的reno拥塞控制算法,也可以指目前linux中实现的reno拥塞控制算法。linux中的reno拥塞控制算法可以看成原始BSD中的reno拥塞控制算法的一个演进变种。后面我们的wireshark示例也会以linux中的reno为例子。
二、数据包守恒原则
如果一个TCP连接处于一个稳定传输状态,当发送端接收到一个Good ACK(Ack Number 大于当前发送端接收到最大的Ack Number的ACK反馈叫做Good ACK)的时候表示接收端已经收到了一个或者多个数据包,即这些数据包已经离开网络到达对端,因此Good ACK可以看成是指示发送端可以发送新的数据包到网络中了。这样在稳定传输状态下的TCP在发送端与接收端之间的网络中数据包的个数是稳定的(SMSS大小数据包),这种现象就叫做“数据包守恒”的原则(conservation of packets principle)。如下图所示,在发送端与接收端的链路中(即Pb数据包所在的管道)数据包的个数应该是稳定的(SMSS大小数据包)。下图中深色部分表示数据包,在发送端短而粗的数据包在网络中传输的时候会被伸展成细而长的数据包,这种设施叫做漏斗(funnel)。通过Good Ack指示发送端发送新数据的这种关系叫做self-clocking,因为是由Ack触发,所以这种关系也可以叫做Ack clocking。
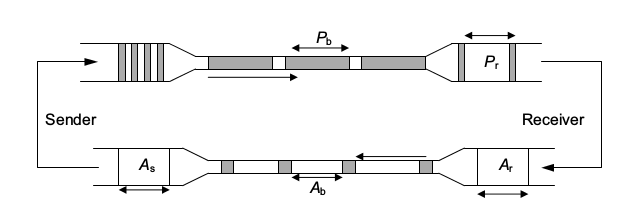
后续要介绍的慢启动和拥塞避免算法就是基于上面介绍的conservation of packets principle和Ack clocking建立的。
三、linux中拥塞控制的背景知识
1、拥塞控制状态机
在Linux的TCP实现中,使用了状态机来处理拥塞控制,这个状态机器共有五种状态,分别如下
Open:这是TCP的正常状态没有dup ACK之类的可疑事件,新收到的数据包处理上一般使用快速路径处理。TCP连接初始建立的时候就处于Open状态。当TCP收到good ACK的时候,就会依据慢启动或者拥塞避免算法调整cwnd。good ACK是指确认了新数据的ACK报文。
Disorder:这个状态是一个和Open状态很类似的状态,在收到SACK或者dup ACK的时候会进入到Disorder状态,他会把一些处理移动到慢速路径。在这个状态下cwnd并会如open态一样进行调整,但是因为这个状态下大部分收到的是ack number相同的dup ACK,因此很多场景下cwnd不会变,我们后面会给出一个Disorder状态下cwnd调整的示例。一般每个新收到的ack报文都会触发新数据的传输,此时TCP遵守包守恒原则。
CWR(Congestion Window Reduced):拥塞窗口因为一些拥塞指示(congestion notification)事件而变小,这些拥塞指示事件可以是ECN、local device congestion。当Linux收到拥塞指示事件的时候并不会一次把cwnd减小到指定值,而是每隔一个ACK报文把cwnd减1,直到窗口大小变为原来的一半。CWR状态可以被下面的Recovery状态或者Loss状态打断。
Recovery:当TCP收到足够数量的dup ACK的时候就会触发快速重传,此时就会进入Recovery状态。类似CWR状态,在Recovery状态下cwnd每隔一个ACK报文就会减小1,一般当cwnd降低到原来拥塞窗口的一半的时候就停止减小,但是Recovery状态下其实cwnd也可以降低到ssthresh以下,后面我们会有示例介绍。在Recovery状态下cwnd并不会增加。当新收到的ack number大于等于进入Recovery状态时的SND.UNA(还记得之前文章中我们称呼这个点为recovery point吧,另外本句大于等于的描述实际上不太准确,后面会给出多个示例)后,TCP发送端进入Open状态。RTO超时的Loss状态也可以打断Recovery状态。
Loss:当发生RTO超时、SACK reneging、PMTUD收到ICMP指示更小的MTU并需要进行重传的时候会进入这个状态。我们之前通过wireshark示例看到过SACK reneging的时候实际上最终触发的也是RTO超时。当RTO超时后,所有发出去的数据包都会被标记为已丢失,cwnd设置为1,发送端开始使用慢启动算法增加cwnd。Loss状态并不能直接被Disorder、CWR、Recovery状态打断。只有收到大于等于recovery point的ack number之后,Loss状态才能切换到Open状态。
我们不会详细的介绍这些状态机的状态切换,但是我们会在后面的一些典型场景下结合wireshark示例来介绍这些状态中cwnd的变化和状态之间的切换。
2、in_flight的计算
协议的中对于拥塞控制一般都是基于字节的描述,即cwnd表示允许TCP发送多少bytes的数据,而Linux中的拥塞控制是基于数据包做的实现,cwnd表示允许TCP发送多少个数据包。因此对于in_flight,Linux也是以数据包维护的,注意我这里说的in_flight并不是RFC5681中的FlightSize,而是RFC6675中的Pipe。RFC5681是拥塞控制的一个基本协议,而RFC6675则是SACK增强版本的拥塞控制,自然linux需要采用RFC6675中的方案。Pipe表示TCP发送端对于还在网络中传输的数据量的估算。in_flight表示目前还在网络中传输的数据包的个数。linux中以in_flight状态变量表示in_flight,进行拥塞控制的时候,如果in_flight>=cwnd的,就表示拥塞窗口不允许在额外发送数据包了。
如果对于下面的in_flight计算过程还是不懂那么请参考RFC6675中的SetPipe ()过程。另外如果要进一步理解linux拥塞控制的代码实现,强烈建议一定要读懂RFC6675。
in_flight = packets_out - left_out + retrans_out
packets_out:表示在SND.NXT和SND.UNA之间一共发送出去了多少个数据包
retrans_out:是重传的TCP报文的个数
left_out:表示已经离开网络但是没有被ack number确认接收的,它包含两部分
left_out = sacked_out + lost_out
sacked_out:这个表示乱序到达接收端的数据包,因此没有被ack number确认,当使能SACK的时候,该变量就是SACK反馈确认的数据包的个数,当没有使能SACK的时候,该变量为接收到的dup ACK的个数。我们之前介绍快速重传的时候说过,接收端收到乱序数据包的时候会立即反馈ACK,因此可以使用dup ACK来估计乱序到达接收端的数据包的总数
lost_out:被网络丢失的数据包的个数,这个变量在快速重传场景下是启发式估计的,正是不同的估计方式区分了不同的算法,目前linux有两种方法来估计lost_out
FACK:lost_out = fackets_out - sacked_out 从而 left_out = fackets_out,即在FACK下,所有在ack number和 most forward SACK之间的数据包,如果没有被SACK确认接收那么就被认定为在网络传输中发生丢失。FACK的相关信息请参考前面重传部分文章的介绍
NewReno:当拥塞控制进入Recovery状态的时候,假设一个数据包发生了丢失,当收到一个partial ACK的时候,则假设又有额外一个数据包发生了丢失。
而在RTO超时场景下,TCP进入Loss状态,linux则会认为所有发出去的数据包都丢失了,因此lost_out = packets_out,in_flight = retrans_out。
Linux进行拥塞控制判断是否允许发送TCP报文的时候就是根据in_flight是否小于cwnd来判断的。当in_flight<cwnd的时候说明拥塞控制允许发送这个报文,否则拥塞控制不允许发送这个报文。而流量控制中对于awnd的判断,则是根据当前报文最后一个byte的数据对应的系列号是否超过对端的接收窗口来判断的。
3、linux中拥塞控制的配置
这里仅介绍如何设置及选择TCP连接的拥塞控制算法,后面文章涉及到其他的拥塞控制的参数配置的时候在具体介绍。在我使用的ubuntu16.04的linux4.4内核中,内核TCP初始化的时候,会默认注册一个reno拥塞控制,其余的拥塞控制算法在编译内核的时候则可以通过编译选项自行配置编译为内核模块或内建到内核中或者直接移除,ubuntu16.04的默认编译选项如下所示,可以看到除了内核中默认的reno拥塞控制算法外,ubuntu16.04还会把cubic拥塞控制算法内建到内核中,并且把cubic拥塞控制算法设置为默认的拥塞控制算法了。而其他的拥塞控制算法则是以模块的形式编译的,默认并不会加载到内核中。不同的拥塞控制算法一般都会有慢启动、拥塞避免等过程,但是在具体调整cwnd和ssthresh的方法可能会有差异。如前面文章所说本系列中将会着重介绍基于丢包的拥塞检测的拥塞控制算法。后面的大部分wireshark拥塞控制示例都会使用reno算法演示。
******@Inspiron:/boot$ grep -i tcp_cong config-4.4.13+CONFIG_TCP_CONG_ADVANCED=yCONFIG_TCP_CONG_BIC=mCONFIG_TCP_CONG_CUBIC=yCONFIG_TCP_CONG_WESTWOOD=mCONFIG_TCP_CONG_HTCP=mCONFIG_TCP_CONG_HSTCP=mCONFIG_TCP_CONG_HYBLA=mCONFIG_TCP_CONG_VEGAS=mCONFIG_TCP_CONG_SCALABLE=mCONFIG_TCP_CONG_LP=mCONFIG_TCP_CONG_VENO=mCONFIG_TCP_CONG_YEAH=mCONFIG_TCP_CONG_ILLINOIS=mCONFIG_TCP_CONG_DCTCP=mCONFIG_TCP_CONG_CDG=mCONFIG_DEFAULT_TCP_CONG="cubic"
在/proc/sys/net/ipv4目录下与拥塞控制算法的选择直接相关的有三个
******@Inspiron:/boot$ more /proc/sys/net/ipv4/*cong*::::::::::::::/proc/sys/net/ipv4/tcp_allowed_congestion_control::::::::::::::cubic reno::::::::::::::/proc/sys/net/ipv4/tcp_available_congestion_control::::::::::::::cubic reno::::::::::::::/proc/sys/net/ipv4/tcp_congestion_control::::::::::::::cubic
其中tcp_available_congestion_control表示当前可用的拥塞控制算法,可以看到有一个内核默认包含的reno拥塞控制算法外,还有一个编译内核时候内建到内核中的cubic拥塞控制算法。tcp_allowed_congestion_control参数设置了对于非特权进程的允许使用的拥塞控制算法,tcp_allowed_congestion_control参数是tcp_available_congestion_control的一个子集。tcp_congestion_control 参数设置了对于新建tcp连接的默认拥塞控制算法,也可以使用socket选项TCP_CONGESTION来对每个TCP连接独立设置拥塞控制算法。
对于编译为模块的TCP拥塞控制算法,可以通过下面的方式加载
******@Inspiron:/boot$ sudo insmod /lib/modules/4.4.13+/kernel/net/ipv4/tcp_bic.ko[sudo] lybxin 的密码:******@Inspiron:/boot$ more /proc/sys/net/ipv4/*cong*::::::::::::::/proc/sys/net/ipv4/tcp_allowed_congestion_control::::::::::::::cubic reno::::::::::::::/proc/sys/net/ipv4/tcp_available_congestion_control::::::::::::::cubic reno bic::::::::::::::/proc/sys/net/ipv4/tcp_congestion_control::::::::::::::cubic******@Inspiron:/boot$ sudo rmmod tcp_bic******@Inspiron:/boot$ more /proc/sys/net/ipv4/*cong*::::::::::::::/proc/sys/net/ipv4/tcp_allowed_congestion_control::::::::::::::cubic reno::::::::::::::/proc/sys/net/ipv4/tcp_available_congestion_control::::::::::::::cubic reno::::::::::::::/proc/sys/net/ipv4/tcp_congestion_control::::::::::::::cubic
另外还可以通过路由表来设置针对某一destination的拥塞控制算法,如下所示将所有与127.0.0.2的tcp连接的拥塞控制算法设置为reno,通过路由表设置TCP相关的参数详见后面destination metric相关的文章。
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno******@Inspiron:~$ ip route show table all | grep 127.0.0.2local 127.0.0.2 dev lo table local scope host congctl reno
补充说明:
1、linux中FlightSize的计算请参考tcp_packets_in_flight
2、https://www.cs.helsinki.fi/research/iwtcp/papers/linuxtcp.pdf
3、https://people.cs.clemson.edu/~westall/853/linuxtcp.pdf
4、https://wiki.aalto.fi/display/OsProtocols/TCP+Congestion+Control
5、TCP/IP Architecture, Design and Implementation in Linux
6、关于TCP各种拥塞控制版本的介绍,建议阅读一下http://download.csdn.net/detail/xiaoran815/5509267