一、模型选择的两种方法
1、正则化(regularization)
能够很好地解释已知数据并且十分简单才是最好的模型
定义:正则化,即结构风险最小化:经验风险+正则化项(罚项)
正则化的一般形式:
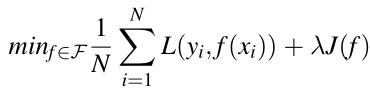 ,第1项是经验风险,第2项是正则化项,λ>=0为调整两者关系的系数
,第1项是经验风险,第2项是正则化项,λ>=0为调整两者关系的系数
第1项的经验风险较小的模型可能较复杂?(有多个非零参数?),此时第2项的模型复杂度较大。
正则化的作用是选择第1项和第2项同时比较小的模型
正则化项:
一般是模型复杂度的单调递增函数,模型越复杂,正则化值越大,正则化项可以是模型参数向量的范数
贝叶斯角度看,正则化项对应于模型的先验概率,可以假设复杂的模型先验概率较小,反之较大
几种形式的正则化项:
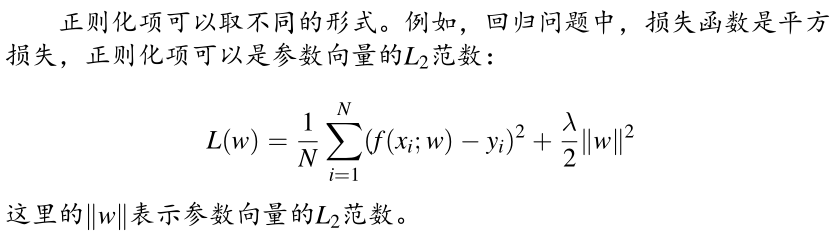

2、交叉验证(cross validation)
a、样本充足:
随机将数据集分成三部分:训练集(用于训练)、验证集(用于模型选择)、测试集(用于评估)。
此时:选择对验证集有最小预测误差的模型
b、样本不充足:
交叉验证:重复使用数据,将数据切分、组合为训练集和测试集,然后反复训练、测试以及模型选择。
i、简单交叉验证:
训练集下训练模型,测试集上评价各个模型的测试误差,选择测试误差最小
ii、S折交叉验证(S-fold cross validation):
随机将数据切分为S个互不相交的大小相同的子集,然后用S-1个子集的数据训练模型,1个子集测试模型。
一共有S种选择重复进行:选出在S次评测中平均测试误差最小的模型
iii、留一交叉验证(leave-one-out cross validation):
S折交叉验证的特殊情况:S=N,N是给定数据集的容量,即一个数据子集只有一个实例,往往在数据缺乏的情况下使用
二、泛化能力
泛化误差越小,泛化能力越大,模型越有效
泛化误差:模型对于未知数据预测的误差,可以认为是模型的期望风险
泛化误差的上界(generalization error bound):训练误差越小、泛化误差越小
是样本容量的函数,样本容量增加时,其值趋于0;是假设空间容量的函数,假设空间越大,模型越难学,其值越大。
三、生成模型(generative)和判别模型(discriminative)
生成:给定输入X,产生输出Y (朴素贝叶斯模型、隐马尔可夫模型)
判别:给定输入X,预测输出Y (感知机、k近邻、 Logistic回归模型、决策树、最大熵模型、支持向量机、提升方法和条件随机场等)
