1. 源代码编译为托管模块
程序在.NET框架下运行,首先要将源代码编译为 托管模块。CLR是一个可以被多种语言所使用的运行时,它的很多特性可以用于所有面向它的开发语言。微软开发了多种语言的编译器,编译时会使用相应的编译 器进行语法检查器和代码分析器,在编译完成后都生成一个托管模块。

托管模块?
托管模块是一个需要CLR环境才能执行的标准windows PE文件,包含IL和元数据以及PE表头和CLR表头。
IL又叫托管代码,是编译器编译源文件后产生的指令,CLR会在运行时将IL编译成本地CPU指令。
元数据实际上是一个数据表集合,用来描述托管模块中所定义和引用的内容。VS能够智能感知就得益于元数据的描述。
PE表头:标准Windows PE文件表头,包含文件类型(如GUI、CUI等),以及文件创建时间等信息。
CLR表头:包含标识托管模块的一些信息。如CLR版本号,托管模块入口点方法(main方法)以及MethodDef元数据等等。
2. 托管模块组合为程序集
一般编译器会默认将生成的托管模块生成一个程序集,CLR直接打交道的是程序集(assembly),程序集包含一个或多个托管模块,以及资源文件的逻辑组合。组合过程如下:
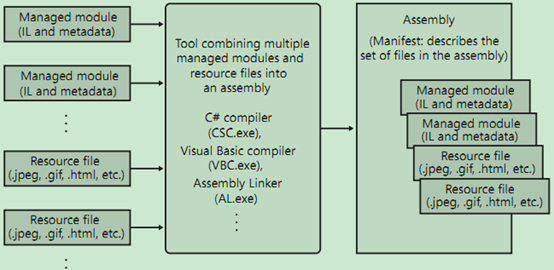
左
侧为一些托管模块,在经过一些工具的处理后,生成了一个PE文件,也就是程序集。程序集中有一个清单(manifest)数据块,用来描述组成程序集的所
有文件。此外,程序集还包含它所引用的程序集的信息,这就使得程序集可以实现自描述。这样CLR就直接知道了程序集所需要的所有内容,因此程序集的部署比
非托管组件要容易。
3. EXE或DLL文件启动CLR运行时
程序要运行,首先确定机器是否安装.NET框架:运行,输入%windir%/system32,查看目标是否存在mscoree.dll文件(微软组建对象运行时执行引擎)。
还可以通过工具CLRVer.exe查看机器上装的所有CLR版本。

加载并初始化CLR的过程:
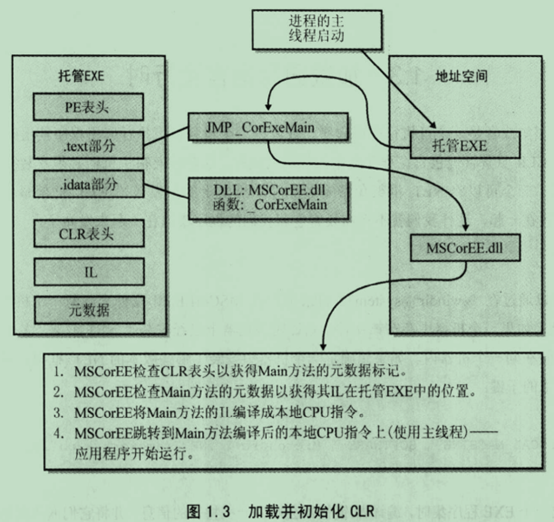
4. 程序集执行
IL代码要通过即时编译器(JIT)转换成本地CPU指令。
方法第一次调用过程?
1. 当程序第一次运行时,会调用JITCompiler函数,它可以知道调用了那些方法,以及定义该方法的类。
2. 然后JITCompiler函数在元数据中搜索该IL代码的位置,验证后转换成本地CPU指令。将指令保存在动态分配的内存中
3. JITCompiler将被调用方法地址改为第2步的内存地址
4. 跳转到上述代码块上执行代码
5. 执行完成后返回
IL是基于堆栈的语言,而且是无类型的。IL的好处之一是提高程序的健壮性,在将IL代码转换成本地CPU指令时,CLR将执行安全验证的过程,验证失败则会抛出异常。
举个小例子,我们可以看出来有时候能通过编译器的检验,但是运行时还是会抛出异常。
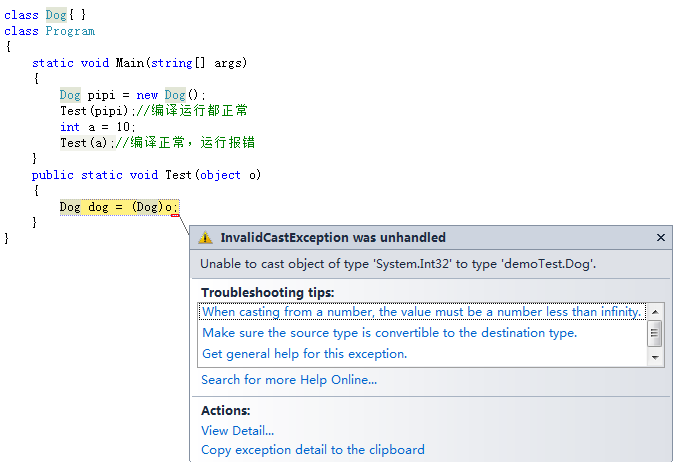
再次调用该方法?
在一个程序中,我们经常反复调用同一个方法,当再次调用该方法时就不需要重复进行验证了,可以直接调用内存块中已有的本地代码,完全跳过JITCompile函数的验证和编译过程。所以同一方法只有在第一次调用时会产生一些性能损失,后续调用就可以全速进行了。
关闭程序?
由于编译器将本地代码保存在动态内存中,所以关闭程序时本地代码将发生丢失。当再次启动程序或者同时运行程序的两个实例时,JIT编译器将再次将IL代码编译为本地指令。
跟小静读CLR via C#(02)-基元类型、引用类型、值类型
一、 基元类型
编译器能够直接支持的数据类型叫做基元类型。例如int, string等。基元类型和.NET框架类库FCL存在着直接的映射关系。
string和String?
面试的时候曾经被问到过这个问题,C#中的基元类型string实际上对应了System.String(FCL)类型,所以两者使用的时候没有什么不同。
类型转换
编译器能够在基元类型之间进行显式或隐式转换。如果转换是安全的,也就是转换过程不会造成数据丢失,则可以直接采用隐式转换。如果是不安全的,则必须采用显式转换。
Int32 a=5;
Int64 b=a;
Int32 c=(Int32)b;
二、 引用类型和值类型
引用类型和值类型的区别:
|
引用类型 |
值类型 |
|
从托管堆中分配 |
从线程的堆栈中分配 |
|
对象考虑垃圾回收机制 |
不考虑垃圾回收机制 |
|
所有类都是引用 |
结构或枚举都是值类型 |
|
继承自System.ValueType |
|
|
只有装箱形式 |
有两种形式:装箱和未装箱 |
|
可以继承和派生 |
不能作为基类,不能有虚方法 |
|
引用类型变量初始化时默认为null |
初始化时默认为0值 |
|
复制时只拷贝内存地址 |
复制时“字段对字段”的拷贝 |
结构体直接继承自System.ValueType;而枚举直接继承自System.Enum, Enum类又直接继承自System.ValueType。
下面通过例子看一下他们的区别:
首先定义类和结构体:
class SomeRef { public Int32 x; }
struct SomeVal { public Int32 x; }
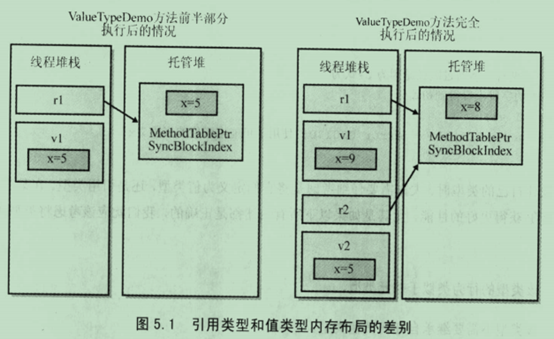
SomeRef r1 = new SomeRef(); // 分配到堆
SomeVal v1 = new SomeVal(); // 分配到栈
r1.x =5; // 所引用的堆空间内数据修改
v1.x =5; // 直接在栈上复赋值
Console.WriteLine(r1.x); // "5"
Console.WriteLine(v1.x); // "5"
SomeRef r2 = r1; //只把指针复制给了r2
SomeVal v2 = v1; // 在栈上分配空间,并且将变量内容进行复制
r1.x = 8; // r1指向(也是r2指向)的内容修改
v1.x = 9; // 只修改v1内容,v2内容不会受影响
Console.WriteLine(r1.x); // "8"
Console.WriteLine(r2.x); // "8"
Console.WriteLine(v1.x); // "9"
Console.WriteLine(v2.x); // "5"
看看下图的内存分配情况,就一目了然了。
三、 值类型的装箱与拆箱
1. 装箱过程?
装箱:将值类型转换为引用类型。当我们把值类型参数传递给需要引用类型参数的方法时,会自动进行装箱操作。过程如下:
从托管堆为要生成的引用类型分配大小。大小为:值类型实例本身的大小+额外空间(方法表指针和SyncBlockIndex)。
将值类型字段拷贝到刚刚分配的内存中。
返回托管堆中新分配内存的地址。也就是指向对象的引用。
2. 拆箱过程?
拆箱:获取指向对象中包含的值类型部分的指针。一般拆箱之后会进行字段拷贝操作,两个操作加起来才是真正与装箱互反的操作。过程如下:
如果引用为Null,则抛出NullReferenceException异常。
如果引用对象不是一个期望值类型的已装箱对象,会抛出InvalidCastException异常。
返回一个指向包含在已装箱对象中值类型部分的指针。
3. 实例
拆箱的转型结果必须是它原来未装箱时的类型。
public static void Main() {
Int32 x = 5;
Object o = x; // 装箱
Int16 y = (Int16) o; // 拆箱,抛出InvalidCastException异常
}
修正:Int16 z=(Int16)(Int32)o;//拆箱成功
这段代码进行了几次装箱?
public static void Main() {
Int32 v = 5; // 创建值变量
Object o = v; // 装箱
v = 123; // Changes the unboxed value to 123
Console.WriteLine(v + ", " + (Int32) o); // Displays "123, 5" ,装箱两次
}
上面的代码进行了3次装箱,最后一句中WriteLine方法要求参数为String引用类型。因此v被装箱为引用类型,o首先被拆箱然后再装箱为引用类型。
优化:
Console.WriteLine(v.ToString()+”,”+o);//装箱0次
我们要尽量少的进行值类型的装箱拆箱操作,以提高程序性能。
if
($ != jQuery) { $ = jQuery.noConflict(); } var isLogined = true; var
cb_blogId = 40567; var cb_entryId = 2097540; var cb_blogApp = "janes";
var cb_blogUserGuid = "cc47420b-63cf-dd11-9e4d-001cf0cd104b"; var
cb_entryCreatedDate = '2011/7/4 16:38:00';
跟小静读CLR via C#(03)- 对象创建和类型转换
本节内容不太复杂,主要是介绍类的实例创建过程,以及类型之间相互转换的知识。
一、 创建对象
CLR要求用new操作符创建对象,这个操作符在编译时产生的IL指令为newobj。例如:
Student XiaoJing=new Student(“XiaoJing”,”1986”);
那么在创建过程中,究竟发生了什么事呢?
分配空间。在托管堆中分配该类所需要字节数的内存空间。
初始化对象的附加成员。每个对象有两个附加成员:一是指向类方法表的指针;二是SyncBlockIndex成员,CLR用该字段进行线程同步控制,某些位还可以用作垃圾回收标 记等等。CLR通过这两个成员管理对象实例。
调用构造函数。其间可以传入指定的参数。
二、 类型转换
C#中,向基类转换直接隐式进行就可以;向派生类转换则需要显示进行,因为有可能会失败。在运行时,CLR会检查转型操作以确保是将对象转化为它的实际类型或者它的基类型。
class Animal { }
class Dog : Animal { }
Animal a=new Dog();
Dog b=(Dog)a; //显示转换,基类向派生类
Animal a=new Dog(); //隐式转换,派生类向基类
IS和AS?
要想检查对象和类是否兼容,有两种方式:Is和As。
Is关键字在使用中经常需要转换两次。首先判断类型兼容,然后常伴随着一次显示转换。
If(a is Dog)//第一次转换
{
Dog g=a;//第二次转换
………
}
As关键字转换一次,然后判断转换后的变量是否为null就可以了。所以该方式性能相对高一些。
Dog g=a as Dog;//转换一次,失败则为null
If(g!=null) {…}
三、 实例考察
下面来看一个类型转换的例子,看每行代码在编译和运行时是否能够正确通过?如果你都答对了,那么本节课的理解就及格了。
还是上面的两个类,Animal和Dog,主要考察类型转换的知识。
|
代码 |
正确 |
编译错误 |
运行错误 |
|
class Program |
|||
|
{ |
|||
|
static void Main(string[] args) |
|||
|
{ |
|||
|
Object o1 = new Object(); |
√ |
||
|
Object o2 = new Animal(); |
√ |
||
|
Object o3 = new Dog(); |
√ |
||
|
Object o4 = o3; |
√ |
||
|
Animal Animal1 = new Animal(); |
√ |
||
|
Animal Animal2 = new Dog(); |
√ |
||
|
Dog Dog1 = new Dog(); |
√ |
||
|
Animal Animal3 = new Object(); |
√① |
||
|
Dog Dog2 = new Object(); |
√② |
||
|
Animal Animal4 = Dog1; |
√ |
||
|
Dog Dog3 = Animal2; |
√③ |
||
|
Dog Dog4 = (Dog)Dog1; |
√ |
||
|
Dog Dog5 = (Dog)Animal2; |
√ |
||
|
√④ |
|||
|
Animal Animal5 = (Animal)o1; |
√⑤ |
||
|
Animal Animal6 = (Dog)Animal2; |
√ |
||
|
} |
|||
|
} |
错误点解析:
① Animal Animal3 = new Object();
基类向派生类转换应该显示进行,所以编译就报错了。实际上就算改成显示转型也会发生运行时错误,因为对象类型不兼容。可以尝试改成Animal Animal3 = (Animal)o2;
② Dog Dog2 = new Object();
理由同①,正解为Dog Dog2 =(Dog)o3;
③ Dog Dog3 = Animal2;
理由同①,正解为Dog Dog3 =(Dog) Animal2;
④ Dog Dog6 = (Dog)Animal1
基 类向派生类显示转型,语法上没有错误因此编译通过。但在运行时,CLR会检查转型操作以确保是将对象转化为它的实际类型或者它的基类型。而Animal1 对象是Animal类型而非Dog类型,因此转型时发生失败。如果添加一句Animal1=new Dog();再执行该转型则会成功。
⑤ Animal Animal5 = (Animal)o1;
理由同④。这里不再赘述了。
你答对了吗?
****************************************
跟小静读CLR via C#(04)- 本是同根生
说起.NET中的类,本是同根生,一点不为过。因为CLR要求所有类都要继承自System.Object。所有对象都必须提供一组通用操作,包括对象的等值性、唯一性、散列码以及克隆。
一、等值性——Equals()方法
有时候我们需要比较两个对象是否相等,比如在一个ArrayList中进行排序查找等操作时。
System.Object提供了Equals()虚方法:
class Object
{
public virtual Boolean Equals(object o)
{
if (this == o) return true;
else return false;
}
}
这种判断方式非常简单:直接比较是两个引用是否指向的是同一对象。但这样比较是不确切的。所以我们需要重写该方法,提供更合适的实现方式。
重写时Equals()四大原则?我们在离散数学中好像学过这个呀:
自反。即x.Equals(x)必须为true。
对称。即x.Equals(y)和y.Equals(x)必须返回同样的值。
可传递。即如果x.Equals(y)和y.Equals(z)都返回true,则x.Equals(z)也返回true。
前后一致。如果两个对象的值没变,那么多次比较的值都应该是相同的。
重写思路
1. 如果参数obj为null,返回false。 因为在非静态方法中,使用this表示的当前对象肯定不是Null。
2. 如果this和obj参数指向同一实例对象,返回true。 这样省略字段比对过程,提高性能。
3. 如果this 和obj参数指向的对象类型不同,则返回false。
4. 比较this和obj中每个实例字段,如果字段不相等则返回false。
5. 调用基类的Equals方法,如果调用结果为false,则返回false;
6. 至此,才能返回true。
二、惟一性——ReferenceEquals() 方法
惟一性指两个引用指向同一对象。一旦我们的类重写了Ojbect的Equals方法,我们就不能用它来检测唯一性了。Object提供了另一个静态方法ReferenceEquals()
public class Object {
public static Boolean ReferenceEquals(Object objA, Object objB) {
return (objA == objB);
}
}
但是我们尽量不要在C#中用==操作符来判断唯一性,除非两参数都为Object类型。因为有可能其中一个参数类型会重写==操作符,使他产生了其他语义。
实例体验?
class Animal { };
static void Main(string[] args)
{
Animal a1 = new Animal();
Animal a2 = a1;
Console.WriteLine(Object.ReferenceEquals(a1, a2)); //true,指向同一对象
a2 = new Animal();
Console.WriteLine(Object.ReferenceEquals(a1, a2)); //false,a2重新指向新对象
int number = 100;
Console.WriteLine(Object.ReferenceEquals(number, number));//false,值类型Number两次装箱到不同的对象中
Console.Read();
}
三、散列码——GetHashCode() 方法
System.Object提供了虚方法GetHashCode()从一个对象上得到Int32的散列码。该方法返回的是在整个应用程序域中保证惟一的值,该值在对象整个生存周期内都不会改变。
如果我们重写了类的Equals()方法,那么我们最好也重写GetHashCode()方法,否则编译器可能会产生警告信息。因为System.Collections.Hashtable类要求两个相等的对象具有相同的散列值。
四、克隆——ICloneable接口
如果一个类允许实例被拷贝,则继承ICloneable接口。
Public interface ICloneable{ object Clone();}
浅拷贝?
当对象的字段值被拷贝时,字段引用的对象不会被拷贝。实现时可以调用Object的MemberwiseClone方法即可。
深拷贝?
对象实例中字段引用的对象也进行拷贝。深拷贝后,新创建的对象和原对象没有任何公用的东西,改变一个对象时也不会影响另外一个。
**********************************
跟小静读CLR via C#(05)- 访问限定、数据成员
今天跟大家分享一下关于访问限定和数据成员的知识。主要包括以下两点:
Abstract, sealed, virtual, new, override怎么用?
Const 和 readonly好像都表示不能改变的值,有什么区别呢?
一、 访问限定
类和方法有一些访问限定符,如private,public等。除此之外,还包含一些预定义特性。下面几个你都知道吗?
1. 类的预定义特性
Abstract——抽象类。不能实例化。如果派生类不是抽象类,则必须实例化。
Sealed——密封类。不能做基类被继承。
要想既不能实例化又不能被继承? 需要两个步骤:
seadled修饰。防止被被继承 ;
私有化无参构造器。防止实例化自动调用默认无参构造函数。例如:
sealed class Demo
{
private Demo() { }
...
}
2. 方法的预定义特性
Abstract——用于抽象类中的抽象方法,该方法不能包含具体实现。派生类如果不实现该方法,则必须为抽象类。
public abstract class Animal
{
public abstract void Shout();
}
Virtual——用于非静态方法。调用时实现的是继承链最末端的方法,也就是按照运行时类型调用的,而不是编译时类型。
New——隐藏但并不会改变基类中虚方法的实现。
Override——重写基类中的虚方法。
实例:
public class Animal //基类
{
public virtual void Shout() //定义虚方法
{
Console.WriteLine("逼我发威啊!"); //虚方法实现
}
}
public class Dog : Animal
{
public override void Shout() //override重写基类方法
{
Console.WriteLine("汪汪!");
}
}
public class Cat : Animal
{
public new void Shout() //new隐藏基类方法
{
Console.WriteLine("喵喵~~");
}
}
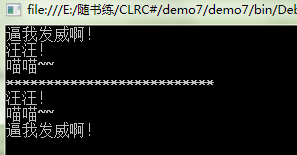
class Program
{
static void Main(string[] args)
{
new Animal().Shout(); //“逼我发威啊!”
new Dog().Shout(); //“汪汪!”
new Cat().Shout(); //”喵喵~~”
Console.WriteLine("**************************");
Animal a1 = new Dog();
a1.Shout(); //重写了基类的方法 “汪汪!”
Animal a2 = new Cat();
((Cat)a2).Shout(); //派生类中的方法隐藏了基类的方法 ”喵喵~~”
a2.Shout(); //基类的方法没有被修改,只是被隐藏 “逼我发威啊!”
Console.Read();
}
}
二、 数据成员——常量和只读
我们经常提到常量和只读,听上去都是不能改变的意思,那么它们到底有什么区别呢?
1. 常量const
常量是恒定不变的,在编译时就确定了它的值,编译后直接将值存到元数据中。变量类型只能是编译器能直接识别的基元类型,不能是引用类型,因为引用类型需要在运行时调用构造函数进行初始化。
我们给段代码实际看一下:
class TestConst
{
public const int Number = 100; //声明常量并赋值
public string GetName()
{
const string name = "XiaoJing"; //常量用作局部变量
return name;
}
}
class Program
{
static void Main(string[] args)
{
Console.WriteLine("const:The total number is " + TestConst.Number);
Console.Read();
}
}
通过ILDasm工具查看一下,const变量编译后为static literal类型,所以不难理解,常量是针对类的一部分,而不是实例的一部分。这样它才能保证是恒定不变的。
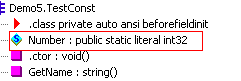
在使用常量时,编译器从常量模块的元数据中直接取出常量的值,嵌入到IL代码中。所以在声明常量的时候就要为它初始化值。例如上面的例子,Number直接替换为值100。
Main函数的IL代码如下:
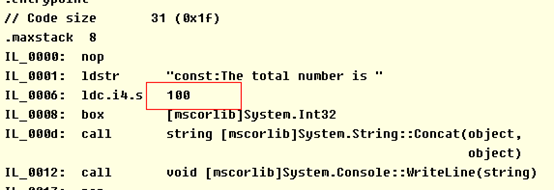
还有一点,const常量也可以用于局部变量,例如上面的GetName()方法。
2. 只读字段readonly
类的数据成员通常用来保存一个值类型的实例或者指向引用类型的引用,CLR支持读写和只读两种数据成员,其中只读数据成员使用readonly修饰的。看个实际例子:
class TestReadonly
{
public readonly int Number = 100; //只读实例成员
public TestReadonly()
{
Number = 200; //构造器中重新赋值
}
}
class Program
{
static void Main(string[] args)
{
Console.WriteLine("readonly:The total number is " + new TestReadonly().Number);
Console.Read();
}
}
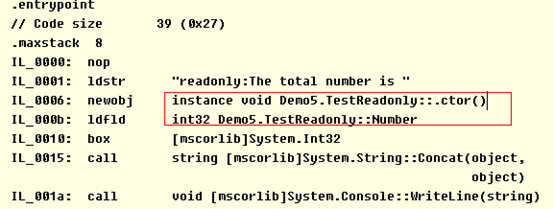
通过ILDasm.exe工具查看, Readonly实例成员编译后为 initonly修饰。这个例子是只读实例成员,readonly也可以修饰静态只读成员,需要在类静态构造器中初始化,这里就不赘述了。

数据成员是在类的实例构造过程中分配内存的,因此能在运行时刻获取它的值。因此只读成员类型没有限制,可以是基元类型,也可以是引用类型。而且可以在构造器中赋值,声明时赋值与否都可以。
我们查看main函数的IL代码:可以看出首先对TestReadonly类进行实例化,然后读取实例的Number成员的值,是在运行过程中获取值的。
还有要注意的一点,readonly不能用作局部变量,否则编译时就会报错。
最后我们要说明的是,readonly字段不能改变的是引用,而不是字段引用的对象。例如
public sealed class AType
{
public static readonly char[] chars = new char[] { 'a', 'b', 'c' };
}
public sealed class BType
{
public static void Change()
{
AType.chars[0] = 'X';
}
}
class Program
{
static void Main(string[] args)
{
Console.WriteLine(AType.chars[0]);
BType.Change();
Console.WriteLine(AType.chars[0]);
Console.Read();
}
}
运行结果是
a
X
*********************************
最近忙着看新还珠,好几天不学习了。玩物丧志啊,罪过罪过。
今天总结的是类构造器的知识,其实这方面的文章蛮多的,可还是觉得亲自写一下对自己的思考和认识会有提高。
对于构造器,大家应该都不陌生,它主要是用来进行初始化状态的。包括实例构造器和类构造器两种,先给大家看个实际的例子。
class Dog : Animal
{

 字段
字段
private string _name;
private int _age;
public string Name//属性
{
get { return _name; }
set { _name = value; }
}
public int Age
{
get { return _age; }
set { _age = value; }
}
public static string type = "动物";//静态字段实例构造器
public Dog() //①无参实例构造函数
{
_name = "无名";
}
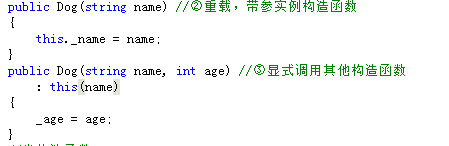
public Dog(string name) //②重载,带参实例构造函数
{
this._name = name;
}
public Dog(string name, int age) //③显式调用其他构造函数
: this()
{
_age = age;
}类构造器
static Dog() //④类构造函数
{
type = "狗狗";
}
}
基类Animal
class Animal//基类
{
public Animal()
{
Console.WriteLine("我是一只动物。");
}
}
一 实例构造器
实例构造器主要负责将类型的实例初始化到一个合理的状态。引用类型和值类型的实例构造器是有所区别的。
1. 引用类型实例构造器
实例构造器可以进行重载,而且可以具有不同的访问限制。上面例子中①②③都是引用类型实例构造器。
实例构造函数和类名相同,但是没有返回类型。在ILDasm.exe中查看为.ctor。
如果我们没有定义实例构造器,那么编译器会为我们默认产生一个无参构造器。
实例对象初始化过程
为实例分配内存;
初始化附加成员,包括方法表指针和SyncBlockIndex变量(我们已经在 跟小静读CLR via C#(03)中已经提到过)。
调用实例构造器进行初始化。
在调用构造函数前,变量被初始化为0或者null,所以没有被构造器改变的变量在实例创建后将保持0值。例如下面的age字段保持0值

![]()
![]()
调用顺序
如果类没有显示定义构造器,编译器会自动生成一个无参构造器,调用基类的无参构造器。例如
public class Animal{}
相当于
public class Animal
{
public Animal():base(){}
}
如果类的修饰符为static(sealed和abstract),编译器不会默认生成构造器;
如果基类没有提供无参构造器,那么派生类必须显示调用一个构造器,否则编译错误。
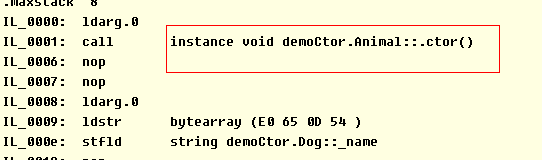
如 果存在继承关系,派生类在使用基类的字段之前应该先调用基类的构造器。如果派生类没有显式调用基类构造器,则编译器会自动产生调用基类无参构造器的代码, 沿着继承层次一直到System.Object的无参构造器位置。例如下面,调用Dog dog=new Dog()方法的结果。

class Dog:Animal。。。

Dog()方法IL代码
代码爆炸?
为了防止构造器重载时大量重复赋值造成代码膨胀,我们建议将公共的初始化语句放在一个构造函数中,然后其他的构造器显式调用该构造器。
2. 值类型实例构造器
值类型没有默认产生的无参构造器,也不允许我们定义无参构造器。但是我们可以自定义带参数的构造器。

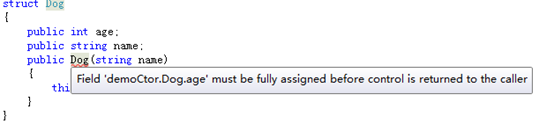
不允许在值类型中内联实例字段的初始化。下面的例子会产生编译错误。
struct TestStruct
{
partial int number=5;
}
值类型带参构造函数必须对所有实例字段进行初始化才可以。如果有变量没有初始化,就会报错。
如果不想对所有字段一一初始化,有一种替代方案:
struct Dog
{
public int age;
public string name;
public Dog(string Name)
{
this = new Dog();
name = Name;
}
}
在值类型构造器中,this代表值类型本身的一个实例,用New创建的值类型实例赋给this时,会将所有字段置零。所以这个方案可以编译通过。
带参构造函数定义之后需要用new显式调用才能执行。否则值类型的字段会保持0或Null值。


二 类构造器
类构造器适用于引用类型(包括接口)和值类型,用来设置类的初始状态。类中并没有默认产生的类构造器,需要我们显式构造,标记为static方法。在元数据表中对应.cctor

类构造器只能有一个,不能进行重载。而且不能含参数。类构造器的目的是初始化类的静态成员,它只能访问静态成员,不能访问实例成员。
类构造器的访问限制是私有的,但是我们不能在类构造器前添加访问修饰符,private也不行,否则会产生编译错误,这样做是为了防止开发人员调用该方法。它的调用是由CLR负责的,我们应该避免编写需要以特定顺序调用类构造器的代码。
类构造器不要调用其基类的类构造器。因为基类的静态成员并没有被派生类所继承,它只是编译时静态绑定。
类构造器的调用顺序和实例构造器相似的,首先静态字段被初始化,然后在构造其中被重新赋值。例如:
class Dog : Animal
{
public static string type = "动物";//静态字段
//类构造函数
static Dog()
{
type = "狗狗";
}
}
Console.WriteLine(Dog.type);
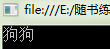
 本节小测
本节小测
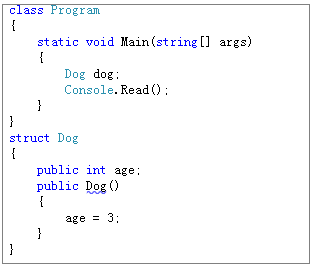
Dog的age字段值是什么呢?
A.0 B.5 C.其他
*******************************
跟小静读CLR via C#(07)-静态类,分部类
一、 静态类-Static
静态类是一些不能实例化的类,它的作用是将一些相关的成员组合到一起,像我们常见的Math, Console等。静态类由static关键字标识,静态类成员也只能是static类型。Static关键字只能用于修饰类,不能修饰值类型。
C#编译器对静态类的限制:
1. 基类只能为System.Object。

因为继承是针对对象而言的,静态类不能创建实例,所以从其他类派生没有实际意义。
2. 静态类不能实现接口。

3. 静态类的成员只能为static类型,可以定义静态的方法,属性,事件等。
public static class StaticClass
{
private static string _name;
public static string Name
{
get { return _name; }
set { _name = value; }
}
}
在ILDASM.exe中查看,我们会看到该静态类被编译器同时标记为abstract和sealed。而且,可以看到静态类不会产生默认的.ctor实例构造器。
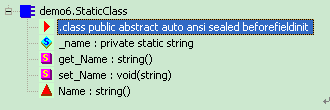
4. 静态类不能用作局部变量、字段、方法的参数等。因为它们都需要引用一个实例。
二、 分部类、结构、接口-Partial
对于partial关键字我们并不陌生,比如在web form的code-behind模式就经常看到这个关键字。它可以应用于类、结构或者接口,告诉编译器分散到多个中的源代码其实是同一个类、结构或接口。
分部类型Partial其实是由编译器提供的,CLR对此并不知情。所以编译器编译后要将相应代码合并后生成一个类型。因此,几个分部类的源代码文件都要使用同一种编程语言。
分部方式的用处?
1. 源代码管理
在使用TFS等进行源代码控制时,如果几个程序员同时修改一个文件,还要进行merge操作。如果使用Partial关键字,可以将类的代码分散到多个文件中去,使多人方便的同时编辑。
2. 代码拆分
在使用vs设计窗体时,设计器生成的文件和具体的功能代码是分离的,提高了开发效率,防止误操作。
3. 将类或结构分解成独立的逻辑单元
如果一个类提供许多复杂的功能,我们可以在源代码中使用分部类,将不同逻辑单元使用分部类拆分开来。这样当我们想从类中去除一个功能模块时也会变得比较容易操作。
对于分部类,其实实际开发中还没有特意用过,以后遇到上面说的这种情况的时候,可以考虑一下。
********************
对于操作符,我们并不陌生,例如+,-,*,%等二元操作符,以及++,!等一元操作符。但是对于非基元类型,我们需要通过一些自定义方法才能使用这些操作符。今天主要和大家分享关于操作符重载和转换操作符的知识。
一、操作符重载方法
CLR并不知道操作符,操作符重载对于它来说只是一些方法而已。但是CLR规定了语言应该如何公开操作符重载,每种编程语言自行决定是否支持操作符重载。
定义操作符重载方法注意两点:
CLR规范要求操作符重载方法必须是 public static 类型。
C#要求操作符重载方法必须有一个参数的类型和当前定义这个方法的类型相同。否则会产生编译错误
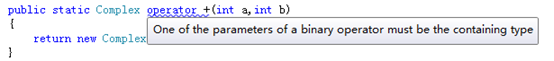
操作符重载实例
我们为非基元类型Complex重载操作符 “+”.
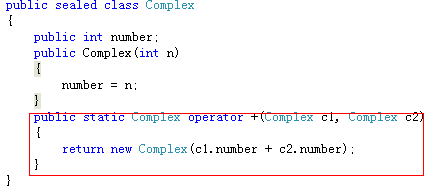
定义之后,可以使非基元类型Complex方便的进行+操作。

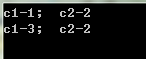
Sepecialname标记
ILDaxm.exe查看Complex类的元数据,发现产生了一个op_Addition项。如果重载其他操作符,也会自动产生相应的specialname标记。

在编译过程中,当代码中出现“+”操作符时,编译器会自动检查op_Addition的specialname标记,并且检测参数类型兼容性。
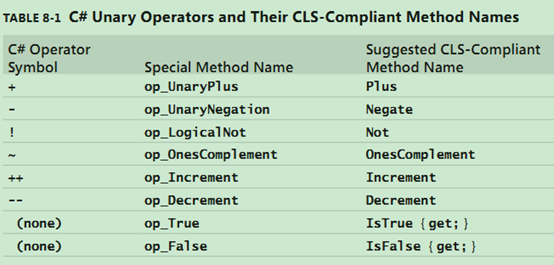
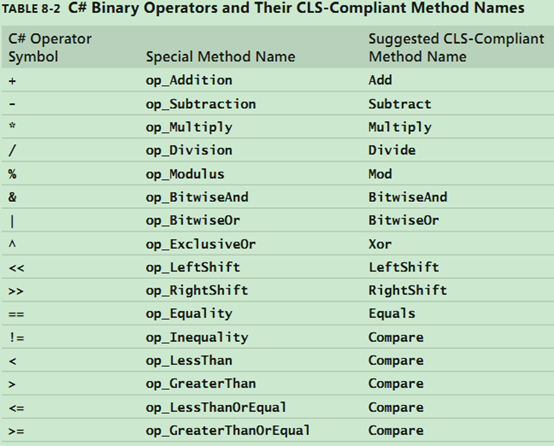
下面两个表是C#允许重载的一元操作符和二元操作符。简单了解一下就好,没必要强记。
二、转换操作符方法
当两个非基元类型的实例需要相互转换时,我们需要定义转换操作符方法。转换操作符是指将对象从一个类型转换成另一个类型的方法。
两大规定
CLR要求转换操作符重载方法必须是public static 方法。
C#要求参数类型和返回类型必须至少有一个与定义转换方法的类型相同。
另外,为了完成转换操作,我们应该在类型内定义两类方法:
实例公共构造器。参数是源类型的实例
无参公共实例方法Toxxx。该方法将定义类型的实例转换成xxx类型。
转换操作符例子
为Rational(有理数)类型定义转换操作符,方便与Int32类型实例进行相互转换。

implicit和explicit
在这个例子中,我们定义了两种转换操作符方法:implicit关键字表示在源代码中不需要进行显式转型;explicit关键字表示进行显式转型时才调用该方法。Operator关键字表明该方法是一个转型操作符。
使用ILDasm.exe查看,
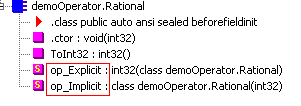
可以发现添加了两个方法:op_Explicit和op_Implicit。只有当转换后不丢失精度的前提下,才能进行隐式转换;如果会发生精度丢失,则只能定义为显式转换。
定义完成之后我们就可以方便的进行转型调用了。
static void Main(string[] args)
{
Rational r1 = 5; // 隐式转换
Int32 x = (Int32)r1; // 显示转换
}
关于重载
在 上面的例子中,实际上一个类型经常会和多个类型实例进行转换操作,此时就需要再定义其他转换操作符,例如public static explicit operator Single(Rational r),也就是进行方法重载。对于重载,我们并不陌生,特殊之处在于这两个explicit重载方法仅仅通过返回值类型不同来区分的。
CLR允许定义多个同名方法,只要每个方法的参数或者返回值类型有所区别即可。但是在C#判断方法的唯一性时,除了方法名称外只考虑参数的区别,而忽略掉方法的返回类型。所以,上面的两个重载方法仅有返回类型的差异实际上是C#放宽限制的特例。
原址:http://blog.163.com/zhouchunping_99/blog/static/783799882011749528637/