一、说明
对于逆向工程和大多数人一样接触始于看雪的《加密与解密》,但在相当长一段时间内对于逆向的认知都只停留在PE格式、OD下断点动态调试、IDA各种窗口静态调试这几个名词上。看了一遍又一遍的书和视频,看的时候觉得很有道理,过了之后则完全没懂到底说了些什么。到后来老师引入CTF,其他人津津有味地做了出来,而自己手足无措看网上的答案这么操作一下那么操作一下结果就出来了完全不懂在做什么为什么要这么做,由此陷入了深深的惶恐。因为在个人看来凡事都是要有依据懂原理才能进行的,但自己成绩不落后别人动手编程能力不落后别人,完全不明白CTF这种自己感觉没头没脑的东西为什么别人却可以做得出来,世界观几要崩溃。时至今日也只能说按照自己的思路确实可以进行逆向,而至于别人为什么感觉没有章法也能逆向则还是没有想清楚。
二、逆向工程思路
在说明中提到“在相当长一段时间内对于逆向的认知都只停留在PE格式、OD下断点动态调试、IDA各种窗口静态调试这几个名词上”,这其中的问题是大多数教程都讲清楚了怎么做,而没向初学者解答一个问题,什么时候这么做。或者换一种说法就是,当我们进行逆向前我们要想清楚一个问题:当我们逆向的时候,我们到底是在做什么。
所谓逆向,其实我们就是在做以下三件事情:
第一步,借助PE格式解析可执行文件。一是指olldbg和ida按PE格式解析出可执行文件的各组成部份包括数据段代码段指令字符串等等;二是指我们自己要能把od和ida解析出来的数据段代码段指令字符串与PE格式对应上,对应上的意思首先是说我们要知道各窗口的东相都在PE文件的什么位置,然后是说我们要知道我们自己想要在的东西应该到哪个窗口去找。
第二步,通过各种手段逼近目标代码。目标代码,比如要去除nag窗口的目标代码弹窗代码,要去除次数限制的目标代码就要计数代码。逼近就是锁定目标代码的起始地址和/或结束地址。逼近手段,OD的逼近手段是各种窗口+断点,IDA的逼近手段是各种窗口+交叉引用。
第三步,是分析目标代码逻辑。就是指或是从锁定的起始地址向结束地址一条条指令地追踪,或是从结束地址往起始地址一条条指令地分析确定目标代码的逻辑,及决定跳过的对策。
在这三步中很多教程让人感觉逆向就是在操作od/ida,但其实od/ida复杂度顶多和burpsuite/wireshark一个级别也没有很多操作,工具操作背后的PE格式理解、汇编掌握才是逆向的真正关建点。下文三四五大点依次对应以上三步。
三、可执行文件格式
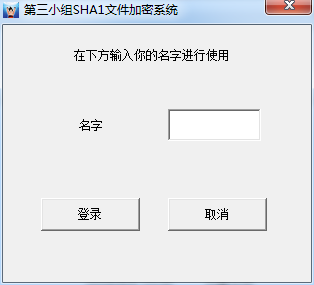
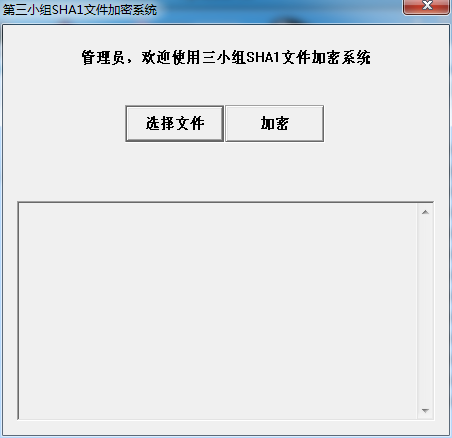
3.1 本文使用的示例程序
首先介绍本文使用的示例程序,这是密码学中用C++写的一个SHA1加密工具,操作过程就是使用小组组员姓名登录,认证通过和即可进入程序加密操作主界面。如下所示:
3.2、可执行文件格式的定义及作用
可执行文件----windows平台就是exe、dll等文件,linux平台就是各种命令和so文件,android平台就是dex文件。是磁盘状态的文件而不是加载到内存后的内存中的文件。
可执行文件格式----就是可执行文件的组织格式。对操作系统而言可执行文件格式指示系统如何正确解析、加载和运行可执行文件;对逆向工具而言可执行文件格式指导逆向工具解析出可执行文件的代码段数据段指令和字符串等各组成部份;对人而言,我们自己也得要掌握可执行文件格式能将逆向工具只是解析出的各部分与可执行文件格式对应上理解各成分的含义作用,不然只是工具解析出来几个窗口在那里并没有什么用,另外加壳脱壳等防护也需要我们掌握可执行文件格式从可执行文件格式入手
windows平台就是PE格式、linux平台就是ELF格式、安卓的dex也有其格式。其实扩展开去不只可执行文件,所有的文件都需要有格式都需要或多或少的一些头部指示其解析器如何对其进行解析,诸如视频、图片、pdf等等。数据包也需要以太头、ip头、tcp头等格式。
3.3 PE文件格式
pe文件格式就是exe文件的格式(下边是低地址上边是高地址)

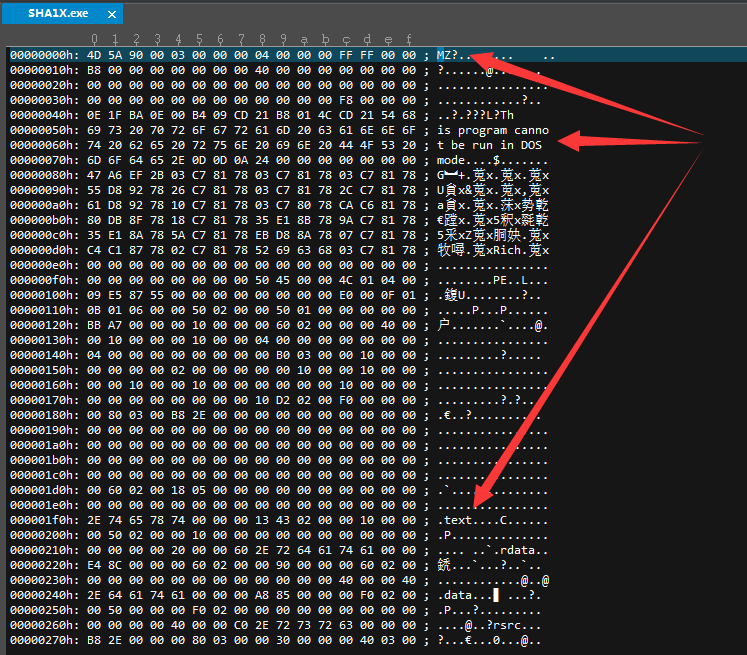
下边是ultraedit以十六进制方式打开本文使用程序的exe文件的开头部分。
在图中可以看到MZ、“This program...”、".text"等字眼,这样读者应该可以将上图的pe文件格式与下图的文件内容对应起来。
四、通过各种手段逼近目标代码
4.1 OD逼近目标代码
使用od就是使用od的各种窗口(比如字符串)和断点(比如内存断点)逼近目标代码,我们这里只点出这个关键点然后简单总结一下od的各种窗口和断点,更详细学习推荐自己带上这一关键点去看《加密与解密》和小甲鱼的解密系列。
4.1.1 OD界面
下边几个图是小甲鱼调试课程ppt的截图,其他窗口及OD操作就不多介绍了。


4.1.2 寄存器
| 寄存器 | 归类 | 名称 | 初始设定作用 | 当前作用 |
| EAX | 通用寄存器 | 扩展累加寄存器 | 函数调用时放回值放里边。STOS会将EAX内容复制到EDI指向的位置。其他时间随便使用 | |
| EBX | 通用寄存器 | 扩展基址寄存器 | 开始用于存放基地址 | 现在由于可以自己完成寻址,所以ebx平时可以随便用 |
| ECX | 通用寄存器 | 扩展计数寄存器 | MOVS等字符串处理指令、REP等循环指令的循环次数,每执行一轮自动减1.其他时间随便使用 | |
| EDX | 通用寄存器 | 扩展数据寄存器 | 乘法存放高位(EAX存低位),除法存余数(EAX存商),其他时间随便用 | |
| ESI | 通用寄存器 | 扩展来源寄存器 | MOVS、CMPS、LODS等字符串处理指令的源地址,其他时间也可随便用 | |
| EDI | 通用寄存器 | 扩展目标寄存器 | MOVS、CMPS、SCAS、STOS等字符串处理指令的目的地址,其他时间也可随便用 | |
| EBP | 通用寄存器 | 扩展基址指针寄存器 | 保存当前函数当前栈底地址 | |
| ESP | 通用寄存器 | 扩展堆栈指针寄存器 | 保存当前函数当前栈顶地址 | |
| EIP | 通用寄存器 | 扩展的指令指针寄存器 | 保存下条将要执行的指令的地址 |
说明:
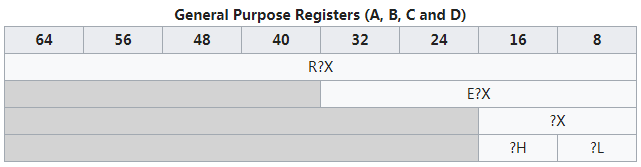
RAX共64位----EAX是RAX的低32位----AX是EAX的低16位----而AH是AX的高8位,AL是AX的低8位;其他寄存器与EAX类似。
4.1.3 OD断点
| 序号 | 断点名称 | 原理 | 适用范围 |
| 1 | INT3断点 | 将下断处的指令改为INT3指令(CC),INT3会触发一个异常,OD捕获异常然后再将INT3修改回原指令 | 代码段(包括DLL的代码段) |
| 2 | 硬件断点 | 将下断的指令地址存入DR0-DR3,CPU执行指令时会比较指令地址是否是DR0-DR3中的地址,如果是会主动给od发送异常 | 代码段 |
| 3 | 内存断点 | 将下断地址修改为不可读/写,当该地址被试图进行读/写时会触发异常 | 代码段、数据段 |
| 4 | 内存访问一次性断点 | ||
| 5 | 消息断点 | 一个消息的发送中包含句柄和消息编号两个参数 | 代码段 |
| 6 | 条件断点 | 当某个寄存器或堆栈段某处等于某值时中断 | 寄存器、堆栈段 |
| 7 | 条件记录断点 |
函数断点:
函数断点指对调用某个win32 api函数(比如USER32.GetWindowTextA)的位置下断点,操作步骤是使用ctrl+n快捷键调出Names窗口里边即是程序所有从dll导入的函数。找到要下断点的函数(不支持搜索只能自己滚动查找,还算好的是按字母排序),然后在其上右键,点击“Set breakpiont on every reference”此时用户内存空间中所有call该函数(本质上是该函数的地址)的指令都会被设成int3断点。删除这些断点一样在函数上右键,选择“delete all breakpoints”即可,当然由于本质是int3断点,所以也可以直接打开断点窗口进行管理。
4.1.4 od 绕过登录限制演示
在本文使用的示例程序中只有输入给定的用户名登录才能使用,我们这里想不管输入什么都能进入使用。这里就锁定我们的目标:逼近输入文字被获取并进行比较附近的代码。
获取文本框内容的函数是GetWindowTextA,ctrl+n呼出函数窗口,找到GetWindowTextA,右键选择“Set breakpiont on every reference”

然后随便在窗口输入一些内容点击登录,比如我这里输“test”
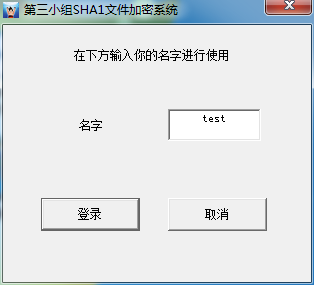
然后程序就断在了GetWindowTextA调用处
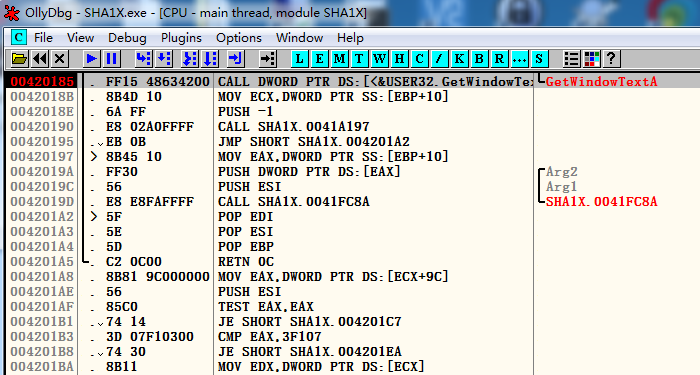
此时有很多call和jmp,比较代码是哪不是很明显,但比较代码一定在从这个GetWindowText到弹出错误窗口的这段范围内,我们一边按F8步过直到错误窗口弹出。最后看到如下

这样我们就锁定了比较代码应应该在00420185和0042021A2之间,不过由于函数调用并不是说比较代码就在这段连续的区间内
我们在0042021A2处下断点,然后不断go to Previous往前走看是从哪跳到0042021A2这边来的(或者也可以重新到00420185一步步往后走,看是哪跳到0042021A2这边来的),经过步步查看后定位到是004020EB的jnz跳过去的,可以猜测如果不跳那么就正常进入程序
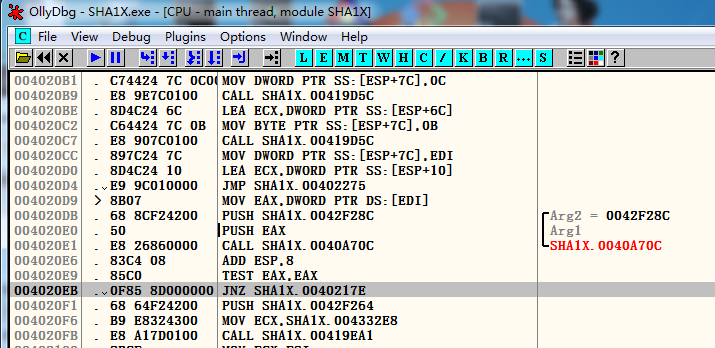
在该条语句上右键,选择Binary----“Fill wtih NOPs”
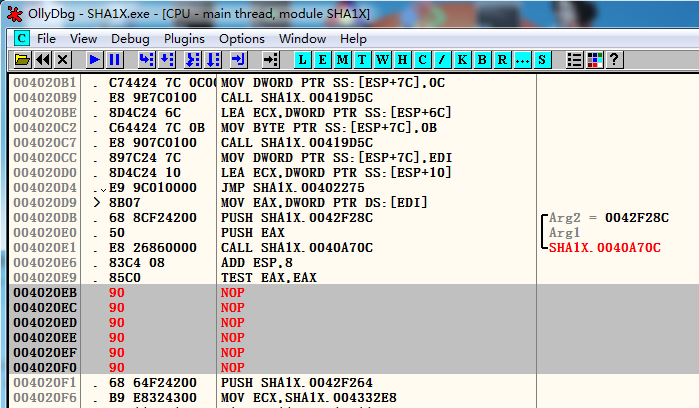
再次使用test登录,果真可进入程序主界面

4.2 IDA逼近目标代码
IDA经常被称为用于静态调试,所谓静态调试就是不能运行代码,解析大家都是可以的所以不能运行代码简单可以更解为ida比od少了指令对应程序表现、栈变化、寄存器变化这几项展现能力。
od使用各种窗口+断点逼近目标代码,ida使用同类窗口+交叉引用逼近目标代码。ida力图通过强化交叉引用能力来弥补断点缺失造成的能力损失,但毕竟交叉引用是断点的弱化版,所以动态调试效果应该来说会比静态调试好,至于还需要静态调试可能是比如病毒等不好动态调试正如老虎不宜随便放出笼来观察一样。
4.2.1 ida界面
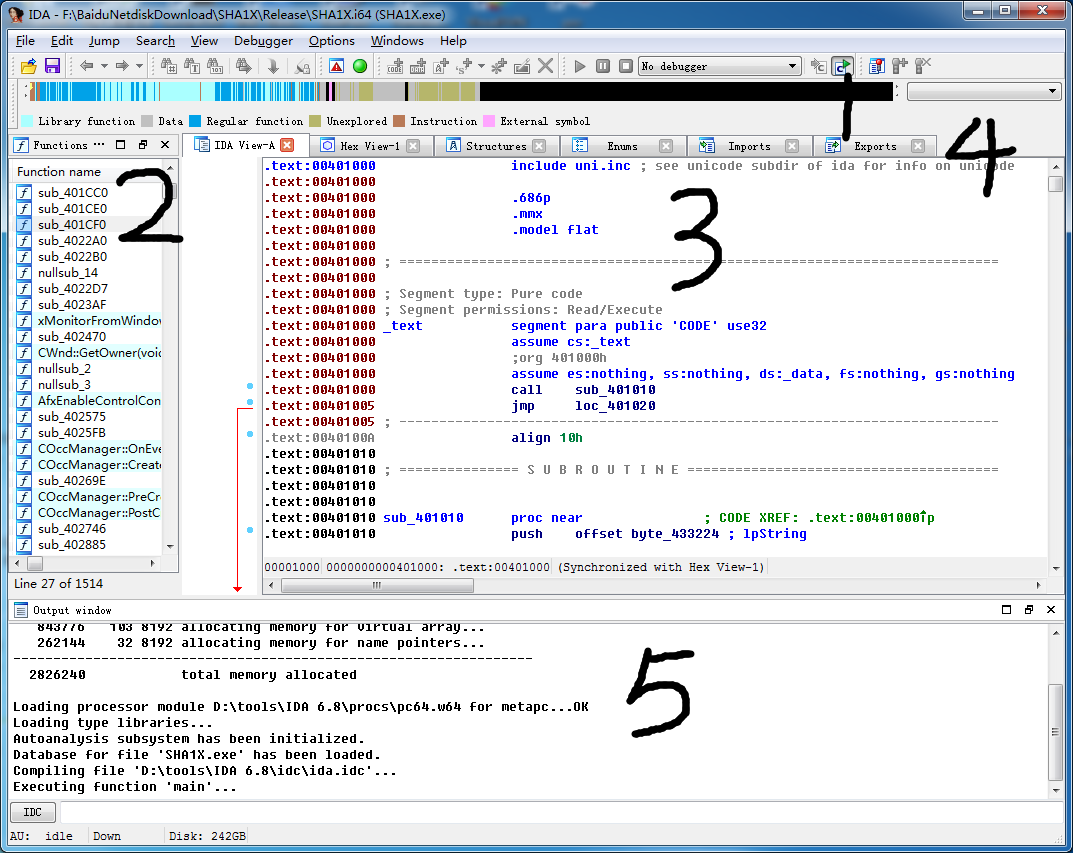
1----导航带。整条就是0x00000000-0xffffffff线性地址定间,点哪主视图窗口就显示哪。
2-----函数窗口。程序自己的函数列表,双击函数就可以去到其实义处。由于编译时不会保存原始函数名,所以如果没有源代码本程序的函数是列不出原始函数名的,只会用sub_xxxxxx形式表示(xxxxxx表示其地址,注意这里说的是“如果没有源代码”,如果有源代码比如你打开的是vc项目debug文件夹下的exe他就能列出原始函数名);至于ida能识别出系统函数名也不是因为保存有原始函数名而是因为ida能把系统函数汇编代码与系统函数名对应上。另外注意这里只是用户自写的或静态链接入的系统函数,动态链接库的函数在import窗口中。
3----反汇编窗口。和od的反汇编窗口类似,不过这里能显示非代码段部分。
4----其他窗口。包括十六进制窗口、导出窗口、导入窗口、结构体窗口、枚举窗口、字符串窗口、名称窗口、段窗口等,和od相比少了寄存器窗口和堆栈窗口其他基本都是一样。所有窗口都可以通过菜单----view----Open subviews来打开。
5---输出窗口。ida输出日志的窗口。
4.2.2 交叉引用
我们前面说过交叉引用里断点的弱化版,我们这里具体来看一下交叉引用长什么样。不过首先要再次说明动态调试也可以有交叉引用,只是动态调试本身可运行程序,没有很大必要去搞交叉引用而已。
引用----或者叫调用、使用,比如jmp、call等
交叉引用---既有正向从调用者地址跳转到被调用者地址的链接,也具有反向从被调用者地址跳转回调用者地址链接的引用。也叫交叉参考。
交叉引用又分为代码交叉引用和数据交叉引用,代码交叉引用指的是代码之间的调用与被调用,数据交叉引用指代码与数据间的调用与被调用,使用上其实没有什么区别都是双击交叉引用链接就跳转到其调用或被调用处。这里只介绍交叉引用的各成分,具体长什么样见下节演示。
交叉引用会被用“;CODE XREF: .text:004020EB↑j”的格式标出,各成分解析如下:
;----注释符号
CODE----表示是代码交叉引用,如果是DATA则表示数据交叉引用。
XREF----交叉引用(Cross references)的缩写
.text----表示其引用处在代码段
004020EB----引用处的的地址,另外有可能会是_main+4等相对写法都一个意思
↑----表示引用地址在当前地址上方,相应的↓就表示在当前地址的下方
j----在代码交叉引用中可以是j或p;j表示跳转流jump,即jmp等跳转指令的引用,在高级语言即if;p表示调用流procedure,即call指令的引用,在高级语言就是函数调用
在数据交叉引用中可以是r或w,r表示读引用,w表示写引用
4.2.3 ida绕过登录限制演示
假设我们使用和od一样的思路,从GetWindowTextA函数入手,首先说因为很多地方都可能调用GetWindowTextA所以确定哪个调用GetWindowTextA的指令才是登录处调用的GetWindowTextA的指令是困难的。其次还是由于无法运行我们得逐条指令分析才能知道哪里是弹出报错窗口。所以函数入手思路确定目标代码的起始地址和结束地址都是困难的。
报错时弹出了“好意思,和你不熟”语句我们不防从该句入手。首先菜单----Search----text查找该字符串,找到其在0042f24c处,然后通过双击数据交叉引用,跳到到数据调用处。
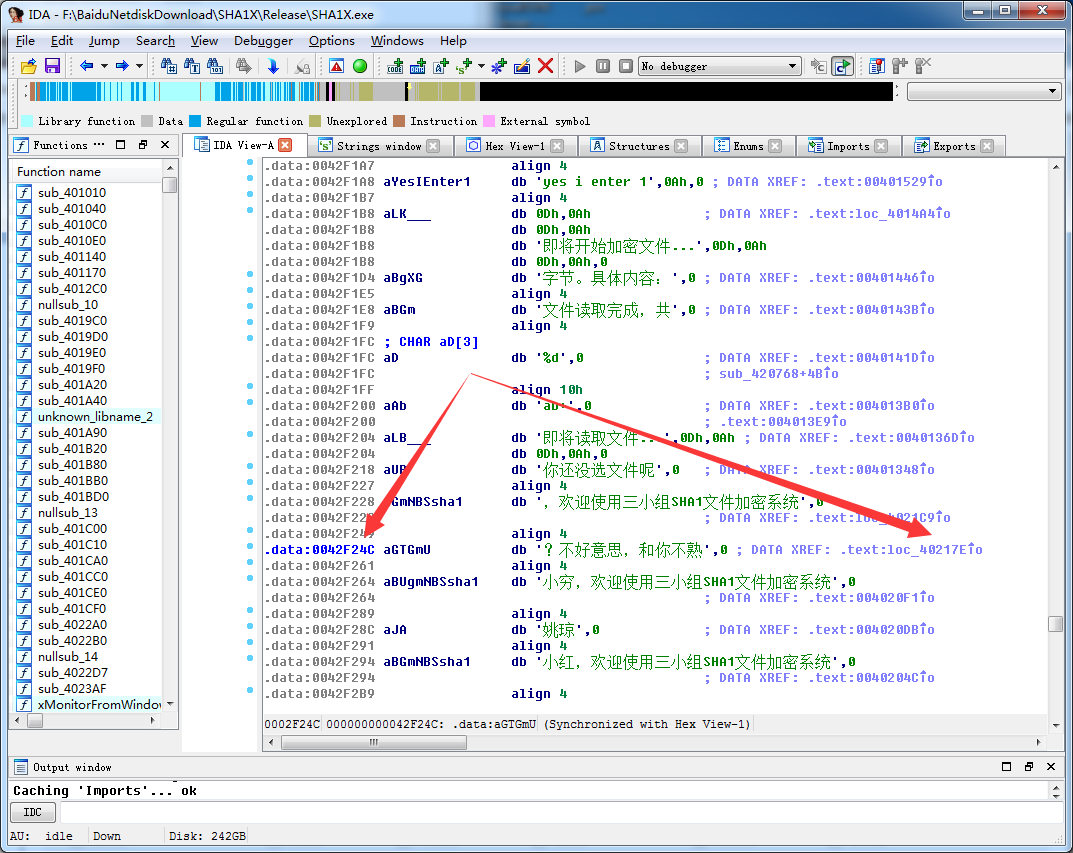
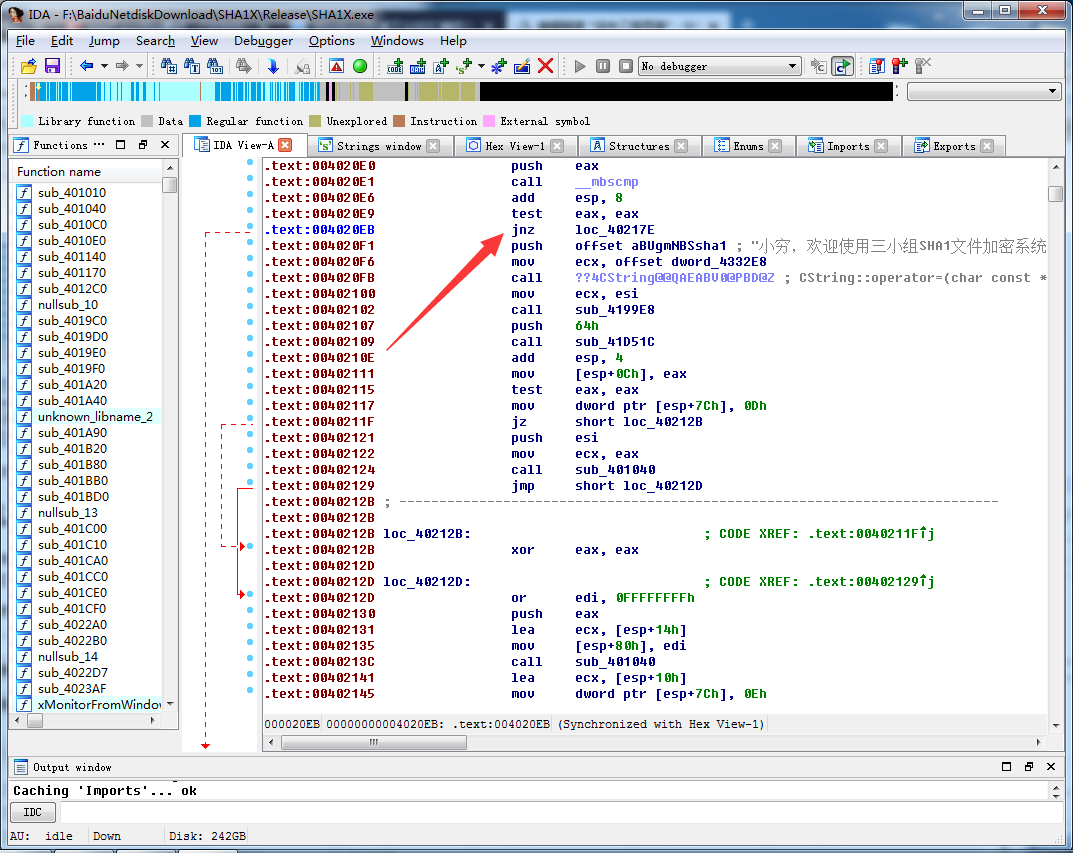
再次通过代码交叉引用跳转到,代码调用处。

观察上下文,可以推断,只要该处不跳转即可进入程序主界面
五、分析目标代码逻辑
分析目标代码关键是且只是自己知道怎么写代码。逆向学汇编建议直接学32位汇编,不用学16位汇编也不用学win 32位汇编(当然也可能我能力不足经验尚浅不解深意读者自己判断)。
虽然说实模式是老祖宗,16位汇编的道理到32位还是可用的,但32位汇编和16位汇编在寻址待方面指令写法毕竟有区别,折腾半天学了16位汇编看32位汇编不一定很顺,类似你掌握了c语言写python也不一定很顺。逆向出来的都是32位汇编所以感觉可以直接学32位汇编。
另外关于win32汇编,win32汇编就是可调用windows api可以使用.if等伪指令的32位汇编。但是一是windows api汇编本就可以调用;二是汇编/反汇编的难点就在栈操作、条件判断跳转和循环,现在汇编使用.invoke/.if/.while等伪指令把push、jnz和loop等指令隐藏起来而汇编是容易了,反汇编却反汇编不出伪指令。所以我不能理解罗云彬说的“win32汇编是windows汇编的不二选择”是什么意思,反而觉得win32汇编在给反汇编增加难度帮倒忙,至少我照着《Windows环境下32位汇编语言程序设计》写了个记事本并没有感觉能更好读懂32位汇编代码(不过理解VC倒确实是很有帮助)。