一、背景说明
自从整理了“正则表达式书写规则说明”后,使用正则表达式的地方都基本能应对。唯一搞不清的是不懂为什么re.search的还要用group()才能获取匹配的结果(而且是group这么个感觉和获取字符串完全不搭边的名字),正是没搞清的这点留下了很大的隐患。
上周同事问正则中重复次数只能作用于其前边的那一个字符,如何能让重复次数能作用于其前边的多个字符,自己信心满满地说加括号就完事了,比如ab*就写成(ab)*,但同事说不行。回头进行验证发现这种写法在findall中确实有问题。
二、问题示例
需求:从一段文字中提取出所有版本号。
测试代码如下:
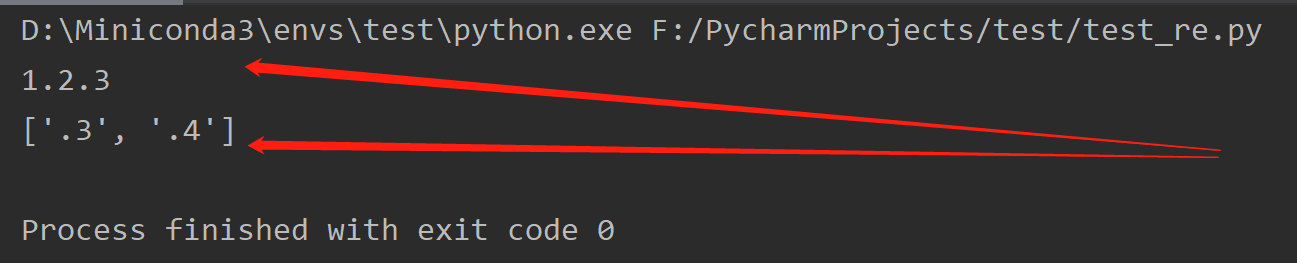
import re # 包含版本号的一段文字 text = "1.2.3 and 1.2.4" # 设想中的正则写法。一个数字开头,后边的.加数值重复一次或多次 regex = "d(.d)+" # 输出结果为'1.2.3',与预期结果一致 print(re.search(regex, text).group()) # 预期结果为['1.2.3', '1.2.4'] # 实际结果为['.3', '.4'] print(re.findall(regex, text))
运行结果如下,search输出结果符合预期,但findall输出结果为['.3', '.4']和预想的['1.2.3', '1.2.4']完全不一样:
三、处理办法
多番google后找到这篇文章,说可以用?:进行处理,使用?:去掉其外一层括号的标识作用只保留其分组作用即可解决该问题。
代码修改如下:


import re # 包含版本号的一段文字 text = "1.2.3 and 1.2.4" # 设想中的正则写法。一个数字开头,后边的.加数值重复一次或多次 regex = "d(?:.d)+" # 输出结果为'1.2.3',与预期结果一致 print(re.search(regex, text).group()) # 输出结果为['1.2.3', '1.2.4'],与预期一致 print(re.findall(regex, text))
运行结果如下,确实能成功提取出版本号:

四、处理原理
虽说使用(?:...)的写法解决了re.findall未能提取版本号的问题,但一是搞不清所谓的“标识”、“分组”是个什么概念,二是同样的正则在search和findall中表现差异让人费解。我们再来分析一下。
4.1 (...)的本质
按文档理解是,小括号的本质是标识一个分组,有多少个小括号就有多少个分组,search和findall都会针对每个分组进行匹配但处理略有差别:
search任何时候都将整个正则视为一个分组,group(0),这也是search的默认返回结果,其他括号也都算一个分组可通过group(index)方法来获取对应分组的匹配结果;
findall在没有括号时将整个正则视为一个分组,有括号时只认括号内的分组,将所有分组匹配结果以元组列表形式返回。
但实际测试后在匹配细节上还是不好理解,但同时没现在还没感觉到这种复杂的分组有什么很大的作用,这暂不深究。
4.2 (?:...)的作用
通过上边的分析我们可以看到,search和findall的区别是search无论何时都将整个正则视为分组,而findall只有在没有括号时才将整个正则视为分组。
而(?:...)的作用就是降低括号的分组功能,使其只在语法分析时视为一个整体但在进行匹配时并不认为是一个分组,这样findall就会像没有括号时那样将整个正则视为分组。此亦即所谓的非捕获(non-capturing)分组。
参考:
https://www.stat.berkeley.edu/~spector/extension/python/notes/node84.html