一、说明
多线程这个东西,感觉一直以来都是用一次就要学一次,今天需要将之前写的脚本改成线程池的形式又学习了一轮。为了以后方便在这直接记下来。
二、多线程实现
2.1 多线程的基本实现


import threading import time import datetime # 该类是自定义的多线程类 # 多己写多线程时仿造记类实现自己的多线程类即可 class MyThread(threading.Thread): def __init__(self): threading.Thread.__init__(self) # 必须实现函数,run函数被start()函数调用 def run(self): thread_name = threading.current_thread().name print(f"开始线程: {thread_name}") self.print_time() print(f"退出线程: {thread_name}") # 可选函数,此处函数的代码可移到run函数内部,也可放到MyThread之外,无关紧要 # 线程要做的具体事务函数,我们这里就打印两轮时间 def print_time(self): count = 2 thread_name = threading.current_thread().name while count: time.sleep(1) print(f"{thread_name}: {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S %f')}") count -= 1 # 该类是一个演于调用MyThread的类 # 其实其代码也完全可以放在if __name__ == "__main__"处 class TestClass(): def __init__(self): pass def main_logic(self): # 创建新线程实例 thread_1 = MyThread() thread_2 = MyThread() # 启动新线程 thread_1.start() thread_2.start() # thread_1.join()即当前线程(亦即主线程)把时间让给thread_1,待thread_1运行完再回到当前线程 # thread_2.join()即当前线程(亦即主线程)把时间让给thread_2,待thread_1运行完再回到当前线程 # join()方法非阻塞 # 如果没对某个线程使用join()方法,那么当前线程(亦即主线程)不会等待该线程执行完再结束,他会直接结束 # 在多线程的进程中,主线程的地位和其他线程的地位是平等的,不会说主线程退出了就会导致整个进程,进而导致其他线程被迫终止 # 自己把这两句join()注释掉再运行一遍,可以更好理解这里的说法 thread_1.join() thread_2.join() print("退出主线程") if __name__ == "__main__": obj = TestClass() obj.main_logic()
运行结果如下:
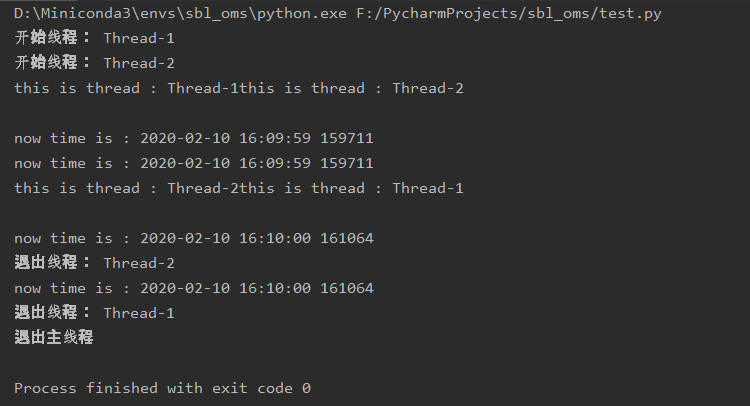
2.2 多线程间的同步
上一小结的代码运行可以成功,但在输出的时候,可以看到是很混乱的:线程1刚打印完自己的名字还没打印时间线程2就抢着打印自己的名字了。
造成这种结果的原因是,默认的多线程中,各线程之间是没有感知的。比如线程2并不知道线程1执行到了哪里(反过来亦然),是刚打印完名字还是已经打印完名字和时间还是其他什么状态,都是不知道的。
所谓同步最主要的就是使用某种方法让线程之间能在一定程度上知道对方在做什么,至少的目标是在使用共用资源时能告诉对方我正在使用你先不要用,实现这“至少”目标最常用的方法是使用锁。
Python3中锁对应的类是threading.Lock(),可通过该类的acquire()方法来获取锁,然后通过该类的release()方法来释放锁。
import sys import threading import time import datetime # 该类是自定义的多线程类 # 多己写多线程时仿造记类实现自己的多线程类即可 class MyThread(threading.Thread): def __init__(self,threading_lock): threading.Thread.__init__(self) # 同步添加处2/4:承接传进来的锁 self.threading_lock = threading_lock # 注意锁必须定义在线程类外部,不能如下在线程类内部自己定义锁 # 因为如果锁在线程类内部才定义,每个线程都是不同的线程类实例,那么各线程间的锁变量本质上就不是同一个锁变量了 # self.threading_lock = threading.Lock() # 必须实现函数,run函数被start()函数调用 def run(self): thread_name = threading.current_thread().name print(f"开始线程: {thread_name}") self.print_time() print(f"退出线程: {thread_name}") # 可选函数,此处函数的代码可移到run函数内部,也可放到MyThread之外,无关紧要 # 线程要做的具体事务函数,我们这里就打印两轮时间 def print_time(self): count = 2 thread_name = threading.current_thread().name while count: time.sleep(1) # 同步添加处3/4:要操作共用资源(这里即打印)时获取锁 self.threading_lock.acquire() print(f"this is thread : {thread_name}") print(f"now time is : {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S %f')}") # 同步添加处4/4:操作完共用资源(这里即打印)后释放锁 self.threading_lock.release() count -= 1 # 该类是一个演于调用MyThread的类 # 其实其代码也完全可以放在if __name__ == "__main__"处 class TestClass(): def __init__(self): pass def main_logic(self): # 同步添加处1/4:定义一个锁对象 threading_lock = threading.Lock() # 创建新线程实例 thread_1 = MyThread(threading_lock) thread_2 = MyThread(threading_lock) # 启动新线程 thread_1.start() thread_2.start() # thread_1.join()即当前线程(亦即主线程)把时间让给thread_1,待thread_1运行完再回到当前线程 # thread_2.join()即当前线程(亦即主线程)把时间让给thread_2,待thread_1运行完再回到当前线程 # join()方法非阻塞 # 如果没对某个线程使用join()方法,那么当前线程(亦即主线程)不会等待该线程执行完再结束,他会直接结束 # 在多线程的进程中,主线程的地位和其他线程的地位是平等的,不会说主线程退出了就会导致整个进程,进而导致其他线程被迫终止 # 自己把这两句join()注释掉再运行一遍,可以更好理解这里的说法 thread_1.join() thread_2.join() print("退出主线程") if __name__ == "__main__": obj = TestClass() obj.main_logic()
使用锁后输出如下:
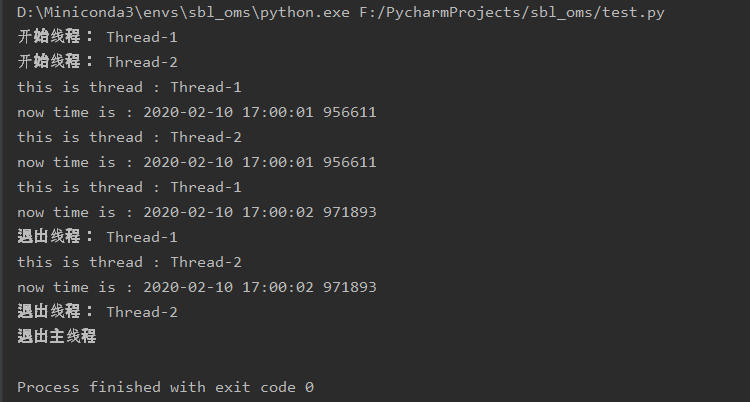
2.3 错误的锁使用方式
虽然在上一小节的代码注释中有说明,但一是自己踩了坑然后想了半天二是感觉应该还是比较典型的容易犯的问题,所以单独一节再强调一下。
代码注释如下:
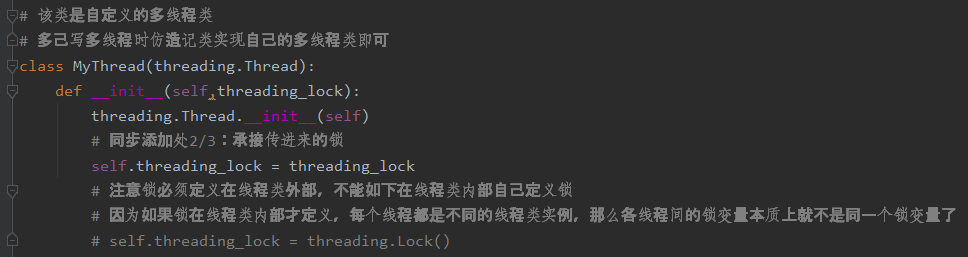
总的意思就是线程同步用的锁必须要来自线程类外部而不能是来自线程类内部的自己实例化。
举个例子,比如我们有一个类叫Test其内部有一个变量a,Test类有两个实例化对象test1和test2,那么我们知道test1.a和test2.a并不是一个变量,对test1.a的任何操作都不会影响test2.a。
所以自己print顺序混乱,使用了锁还是混乱时,就要注意是不是自己的锁是在线程类内部实例化的(不要盯着网上什么print()不是线程安全的、要用sys.stdout.write()之类的说法想半天)。
三、线程池实现
假设我们有100个任务,我们打算分10轮进行,每轮创建10个线程去处理10个任务,这是一个可行的做法,但有些粗放。
每轮创建10个线程,那么就意味着完成这100个任务前后共有100个线程的创建及消毁的动作,而如果我们创建10个线程组成线程池那么就能反复复用这10个线程,完成100个任务的前后总共只有10个线程的创建及消毁的动作。(但要注意整个过程中并不一定是每个线程都处理10个任务了,有的线程可能处理多于10个,有的线程则可能处理少于10个)
减少线程创建及消毁过程中损失的计算资源正是线程池的意义所在。
3.1 由普通单线程类改造成使用线程池的类的方法
有时候我们会遇到这种情况:我们之前已经写好了一个类,但该类是单线程的我们现在机改成多线程的形式。
我们下边来看一下如何该动最少的代码,将该类改成使用线程池的形式;同时有了第二大节的知识,也直接改成线程同步的形式。
假设原始的单线程的代码形式如下:
import threading import time class TestClass(): def __init__(self): pass def main_logic(self): for i in range(4): self.do_something(i) pass def do_something(self, para): thread_name = threading.current_thread().name print(f"this is thread : {thread_name}") print(f"the parameter value is : {para}") time.sleep(1) pass if __name__ == "__main__": obj = TestClass() obj.main_logic()
执行结果如下:
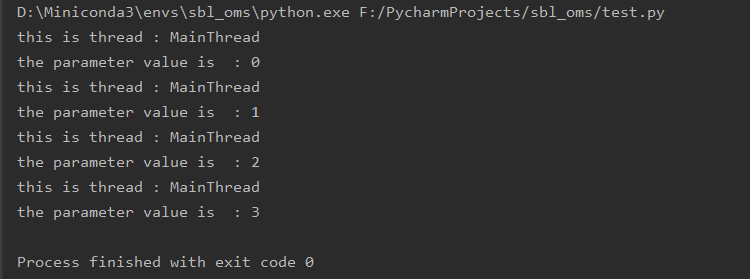
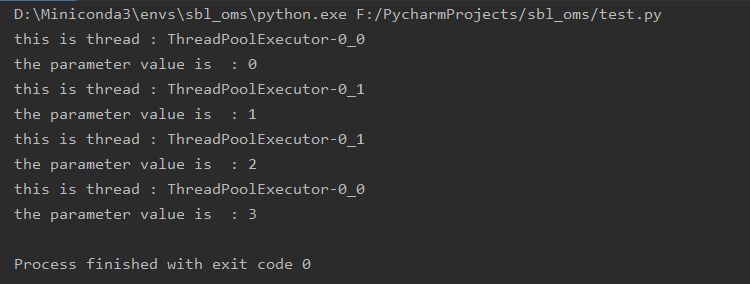
改造后代码如下:
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor # 线程池,进程池 import threading import time class TestClass(): def __init__(self): # 线程池+线程同步改造添加代码处1/5: 定义锁和线程池 # 我们第二大节中说的是锁不能在线程类内部实例化,这个是调用类不是线程类,所以可以在这里实例化 self.threadLock = threading.Lock() # 定义2个线程的线程池 self.thread_pool = ThreadPoolExecutor(2) # 定义2个进程的进程池。进程池没用写在这里只想表示进程池的用法和线程池基本一样 # self.process_pool = ProcessPoolExecutor(2) pass def main_logic(self): for i in range(4): # 线程池+线程同步改造添加代码处3/5: 注释掉原先直接调的do_something的形式,改成通过添加的中间函数调用的形式 # self.do_something(i) self.call_do_something(i) pass # 线程池+线程同步改造添加代码处2/5: 添加一个通过线程池调用do_something的中间方法。参数与do_something一致 def call_do_something(self, para): self.thread_pool.submit(self.do_something, para) def do_something(self, para): thread_name = threading.current_thread().name # 线程池+线程同步改造添加代码处4/5: 获取锁 self.threadLock.acquire() print(f"this is thread : {thread_name}") print(f"the parameter value is : {para}") # 线程池+线程同步改造添加代码处5/5: 释放锁 self.threadLock.release() time.sleep(1) pass if __name__ == "__main__": obj = TestClass() obj.main_logic()
执行结果如下:
3.2 处理submit非阻塞导致的所有任务会一次性创建的问题
self.thread_pool.submit()是非阻塞的,提交任务后立即返回,这就导致call_do_something()也会立即返回,进而导致main_logic()中的for会一下执行完。
也就是说,还是假设我们有100个任务用10个线程去处理,那么这100个任务基本就是一下就创建完成。当然线程池自己会组织好这100个任务,慢慢地让这10个线程去处理。
这种机制在100个任务下还没什么大的影响,但如果我们有100万个任务呢,100万个任务同时创建,100万个任务的信息堆在内存中,内存消耗就是很大的问题了。
所以当任务量很大、或者任务的参数很大时就要注意和处理submit非阻塞可能会导致的内存消耗问题。代码在上一小节之上修改如下:
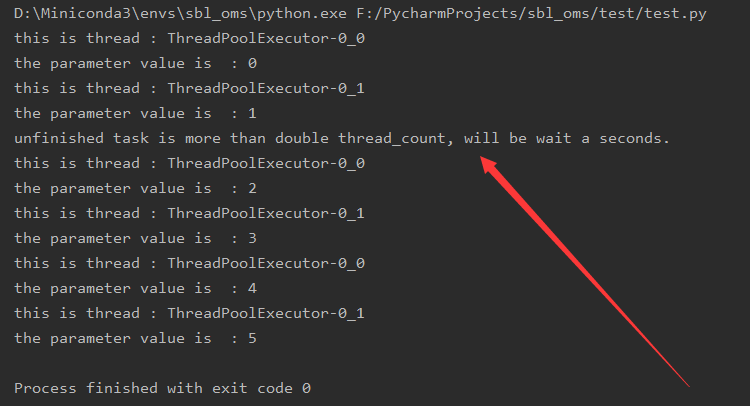
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor # 线程池,进程池 import threading import time class TestClass(): def __init__(self): # 线程池+线程同步改造添加代码处1/5: 定义锁和线程池 # 我们第二大节中说的是锁不能在线程类内部实例化,这个是调用类不是线程类,所以可以在这里实例化 self.threadLock = threading.Lock() # 定义2个线程的线程池 self.thread_pool = ThreadPoolExecutor(2) # 定义2个进程的进程池。进程池没用写在这里只想表示进程池的用法和线程池基本一样 # self.process_pool = ProcessPoolExecutor(2) pass def main_logic(self): for i in range(6): # 线程池+线程同步改造添加代码处3/5: 注释掉原先直接调的do_something的形式,改成通过添加的中间函数调用的形式 # self.do_something(i) self.call_do_something(i) pass # 线程池+线程同步改造添加代码处2/5: 添加一个通过线程池调用do_something的中间方法。参数与do_something一致 def call_do_something(self, para): # 控制未完成任务数添加代码处1/3:定义一个变量,记录当前任务列表。规范写法是在__init__中定义我为代码信中放在这里 try: self.task_handler_list except: self.task_handler_list = [] # 控制未完成任务数添加代码处2/3:提交任务时把任务句柄记录到上边定义的列表中 task_handler = self.thread_pool.submit(self.do_something, para) self.task_handler_list.append(task_handler) # 控制未完成任务数添加代码处3/3:当未完成任务数不多于线程的2倍时才允许此任务返回 while True: # 我们可能听说过使用as_completed()可以获取执行完成的任务列表,但实际发现as_completed是阻塞的他要等待任务响应他的询问 # 所以并不推荐使用以下形式来获取未执行完成的任务列表 # task_handler_list = list(set(task_handler_list) - set(concurrent.futures.as_completed(task_handler_list))) # 将已完成的任务移出列表 for task_handler_tmp in self.task_handler_list: if task_handler_tmp.done(): self.task_handler_list.remove(task_handler_tmp) # 如果未完成的任务已多于线程数的两倍那么先停一下,先不要再增加任务,因为几万个ip一把放到内存中是个很大的消耗 if len(self.task_handler_list) > 2 * 2: print("unfinished task is more than double thread_count, will be wait a seconds.") # 睡眠多久看自己需要,我这设2秒 time.sleep(2) else: return True def do_something(self, para): thread_name = threading.current_thread().name # 线程池+线程同步改造添加代码处4/5: 获取锁 self.threadLock.acquire() print(f"this is thread : {thread_name}") print(f"the parameter value is : {para}") # 线程池+线程同步改造添加代码处5/5: 释放锁 self.threadLock.release() time.sleep(1) pass if __name__ == "__main__": obj = TestClass() obj.main_logic()
运行结果如下,可以看到成功实现在当未完成任务过多时阻止继续创建新的任务:
3.3 多线程不共享线程函数内的局部变量
多线程共用内存地址空间所以变量是共享的,即变量在一个线程中被修改那么该变量在其他线程中的值也会被修改。
但这句话需要进一步明确,比如在3.1节的代码中do_something函数有thread_name这个变量,如果在线程1获取thread_name之后打印thread_name之前,线程2也获取了thread_name,那么线程1的thread_name值是否会变成线程2的名称?
答案是不会,多线程虽然共用地址空间,但是不同线程启动的函数如同在主线程对一个函数进行多次调用一样,并不放在同一地址,所以线程函数内的局部变量也就不是共享的变量。除了thread_name,para是传值过来的参数也是线程函数内的局部所以也不共享。
3.4 多线程异常不会被打印更不会导致进程结束(20200326更新)
今天在跑一份线程池代码时发现进程没有按预期结束,该代码有一初始值为0的线程计数器,在线程函数的开头线程计数器加1,在线程函数的开头线程计数器减1,在最后线程计数器为0(即所有线程运行完毕)时退出。但该计数器一直不为0。
反复排查之下发现是多线程(线程池)场景中,当一个线程(更准确地应该说是任务)出现异常时,该线程会直接结束,异常也不会被抛出。测试代码如下:
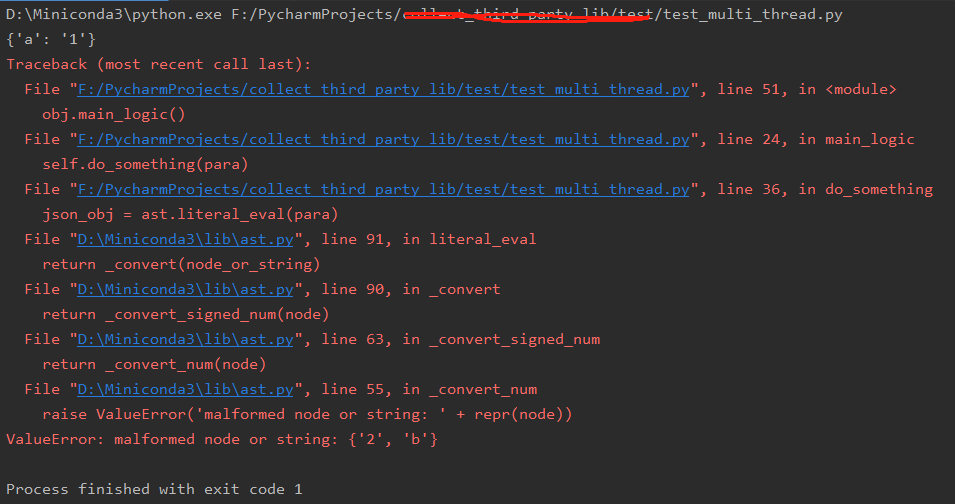
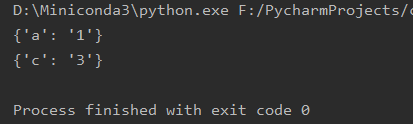
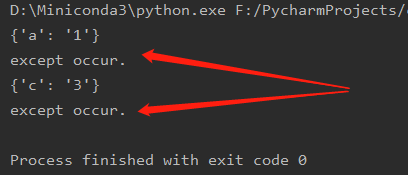
import ast import time import threading from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor # 线程池,进程池 class TestClass(): def __init__(self): # 线程池+线程同步改造添加代码处1/5: 定义锁和线程池 # 我们第二大节中说的是锁不能在线程类内部实例化,这个是调用类不是线程类,所以可以在这里实例化 self.threadLock = threading.Lock() # 定义2个线程的线程池 self.thread_pool = ThreadPoolExecutor(2) # 定义2个进程的进程池。进程池没用写在这里只想表示进程池的用法和线程池基本一样 # self.process_pool = ProcessPoolExecutor(2) pass def main_logic(self): paras =["{'a':'1'}",{'b','2'},"{'c':'3'}",{'d','4'}] for para in paras: # 线程池+线程同步改造添加代码处3/5: 注释掉原先直接调的do_something的形式,改成通过添加的中间函数调用的形式 # self.do_something(i) # 单线程模式 # self.do_something(para) # 多线程(线程池模式) self.call_do_something(para) pass # 线程池+线程同步改造添加代码处2/5: 添加一个通过线程池调用do_something的中间方法。参数与do_something一致 def call_do_something(self, para): self.thread_pool.submit(self.do_something, para) def do_something(self, para): # thread_name = threading.current_thread().name # 这个的作用是把字符串变为json对象 json_obj = ast.literal_eval(para) # 多线程时,上边这句异常之后并不会抛出异常,且在其后边的本该此线程运行的代码都不会被执行 print(f"{json_obj}") # 线程池+线程同步改造添加代码处4/5: 获取锁 # self.threadLock.acquire() # print(f"this is thread : {thread_name}") # print(f"the parameter value is : {para}") # # 线程池+线程同步改造添加代码处5/5: 释放锁 # self.threadLock.release() # time.sleep(1) pass if __name__ == "__main__": obj = TestClass() obj.main_logic()
当单线程模式时,即注释self.call_do_something(para)启用self.do_something(para)时,运行代码可以看到异常抛出:
当多线程(线程池)模式时,即注释self.do_something(para)启用self.call_do_something(para)时,运行代码可以看到并没有异常,只是出现异常位置之后的代码(这里是print)并不会被执行:
我们有理由相信一个库在单线程模式下不自己处理而是直接抛出异常,那么在多线程之下他应当保持一样的表现。所以多线程模式下异常虽然没有被打印也没有导致进程结束,但异常应当还是抛出了的,即也可以通过try来捕获。测试结果如下,证实了我们这一猜想。
四、关于Python3并发/并行的一些技术细节讨论(20200409更新)
4.1 并发和并行的区别
并发:看似多个任务同时进行,但具体到某一时刻,只有其中一个任务能在CPU运行的状态。
并行:同一时刻,多个任务能同时在CPU运行的状态。
说明:单核CPU只能实现并发不能实现并行的,只有多核CPU才可能实现并行。C语言的多线程是并行的,Python的多线程由于GIL的存在只能并发。
4.2 GIL是什么
Python解析器(CPython)不是线程安全的,即当一个线程访问一个对象时另外的线程仍然可以访问该对象,如果不加以限制那么就很容易出现数据错误(就如我们自己多线程不加锁去操作同一个变量一样),由此Python引入了GIL。
GIL,global interpreter lock,全局解析器锁,只有获取到了该锁的线程才能在解析器中执行,显然同一个时刻只可能有一个线程能获取到锁,所以同一个Python解析器中同一时刻只可能有一个线程能够运行,所以Python多线程只能并发不能并行。
至于为什么C语言不需要类似GIL的东西Python需要GIL,问题似乎是出在Python是解析型、弱类型语言。即凡是解析型、弱类型语言,如Ruby等,现在应该都有这个问题。
4.3 GIL的影响有多大及Python的多线程是不是鸡肋
GIL使得同一解析器中仍意时刻只能有一个线程得到运行,即意味着任意时刻一个Python进程只能使用一个CPU核,这完全不能发挥多核计算机的优势。如果说什么是Python的最大问题,我觉得这就是Python最大的问题。
但我们要明确以下几点:
第一,只有在多线程状态下GIL才会产生影响。如果你写的程序是单线程的,那么GIL对其运行速度没有影响。
第二,只对计算密集型任务GIL才会产生影响。如果多线程程序中线程更多是在等待IO而不是等待CPU进行计算,那么GIL对其运行速度没有多大影响。
所以GIL只对多线程且计算密集的程序有影响,但一般而言,除非是进行长时间不间断的运算或编写强调并行的服务器,不然我们一般编写的脚本吃不完一个核的运算能力。
4.4 改进办法是什么
但不管怎么说GIL使得多核计算机的优势不能得到充分发挥是个实实在在的问题,你不能一句问题不大就一笔带过了,万一我就是要编写计算密集的程序、就是要并行你到底行还是不行呢。
答案是想让Python多线程实现并行现在看来是不太行的,但我们可以使用多进程。前边我们说GIL限制时一直在强调“同一个解析器”,只要我们使用不在同一解析器的进程,那就能实现利用多个核、实现并行的效果。
4.5 多进程的劣势是什么
那么多人在说GIL问题,这很难让人想信多进程就能完美绕过GIL带来的限制,所以,说吧,多进程的劣势是什么。
多进程确实存在以下两个比较大的问题:
第一个是让系统难受的,即多进程相对多线程会消耗更多的系统资源,当然这在所有语言中都存在。
第二个是让开发者难受的,即不同解析器或者说不同Python进程间的通信是很麻烦的事情。
多进程间通信首先推荐队列。队列是最简单的,而且其内部(multiprocessing.Manager().Queue())已经实现好了跨进进程间的锁,访问时不需要加锁。
其次推荐multiprocessing.connection。multiprocessing.connection基于socket实现,但其与直接的socket的区别是,你通过put()推入的什么object通过get()获取到的就是什么object,不需要他不需要像tcp那样自己定界。
共享变量,则可参见“Python3多进程共享变量实现方法”。
4.6 多线程/多进程对目标函数的要求
多线程target的函数或线程池submit到的函数,不能是匿名函数,可以是一级函数、当前类的成员函数、其他类的实例的成员函数;add_done_callback只能是一级函数。
多进程target的函数或进程池submit到的函数,不能是匿名函数、当前类的成员函数,可以是一级函数、其他类的实例的成员函数;add_done_callback只能是一级函数。(一些书说多进程target的函数或进程池submit到的函数只能是一级函数,但实测发现其他类的实例的成员函数是可以的。)
另外要注意,多进程给目标进程函数提交的参数,不能是线程锁、或者logger、queue.Queue()等自带线程锁的变量,不然会导致pickle无法序列化错误(TypeError: can't pickle _thread.lock objects)。
对于目标函数是其他类的实例的成员函数的情况,还要要求该类成员变量也不能是线程锁、或者logger、queue.Queue()等自带线程锁的变量,不然也会报一样的错误。
对于这个问题,变通的处理方法是使用进程级对应的类代替,如multiprocessing.Manager().Lock()、multiprocessing.Manager().Queue(),但logger写同一个文件那似乎就没有能保证进程安全的写法了。
参考: