本作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
一、将爬虫大作业产生的csv文件上传到HDFS
将爬虫大作业中爬取到的数据文件csv导入到/usr/local/bigdatacase/dataset目录下,并且查看CSV:

二.对CSV文件进行预处理生成无标题文本文件
利用bash ./pre.deal.sh 恶魔人cryb.csv 恶魔人crybaby.txt对文本进行预处理,pre.deal.sh内容如下:

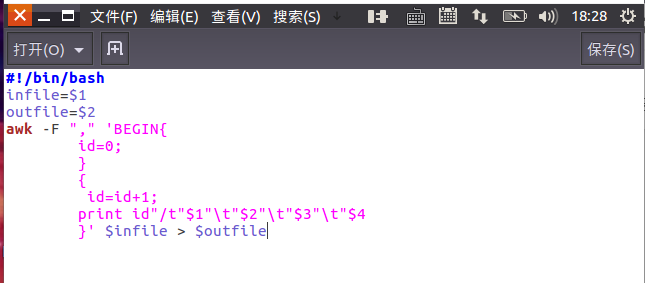
处理后的恶魔人crybaby.txt内容如下:

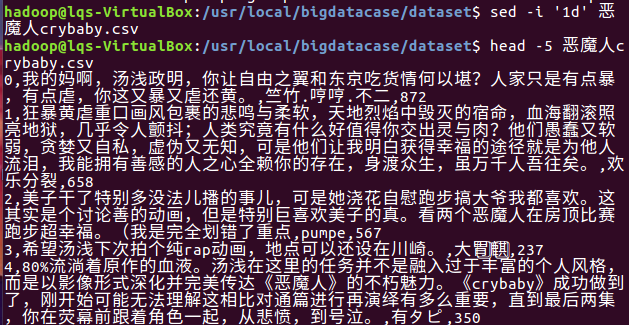
用命令去除csv的第一行
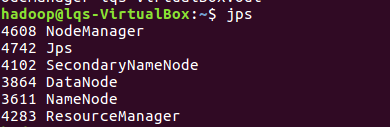
然后用start-all.sh打开hdfs服务,用jps命令查看启动情况:
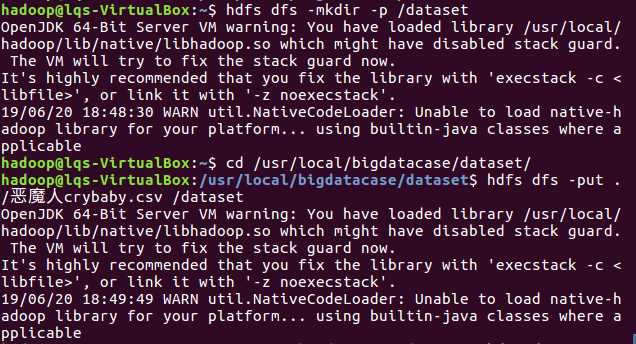
在HDFS上建立/dataset文件夹并且把恶魔人crybaby.csv上传到HDFS中
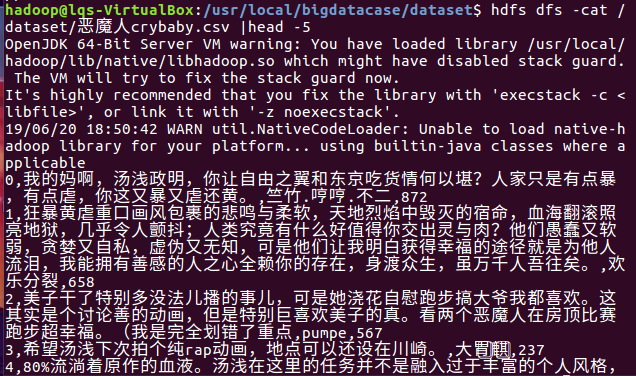
在HDFS上查看csv内容
三、把hdfs中的文本文件导入到数据仓库Hive中
在hive中新建一个名为crybaby的table并use

新建一个pinglun2的表把数据导入到其中

四.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
(1)最新10条评论

(2)点赞数>100的评论

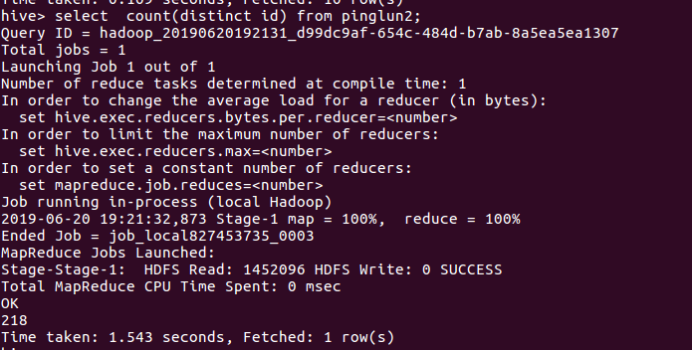
(3)总评论条数
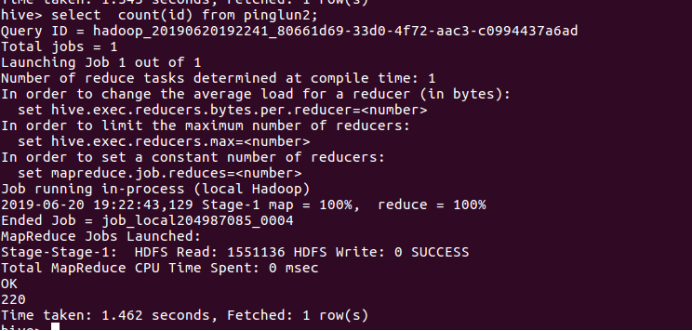
(4)不为同一ID发表的评论条数
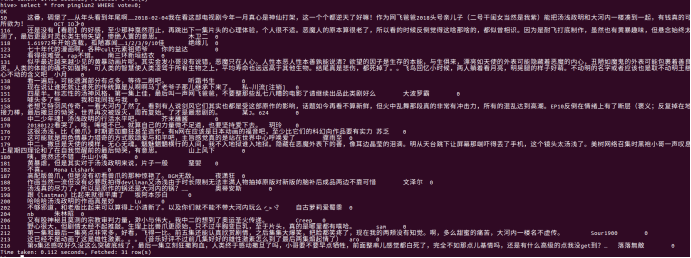
(5)点赞数为0的评论
(6)点赞数>100且<500的评论

(7)去除重复评论内容的评论数
(8)点赞数倒数10位的评论

(9)点赞数前10位的评论

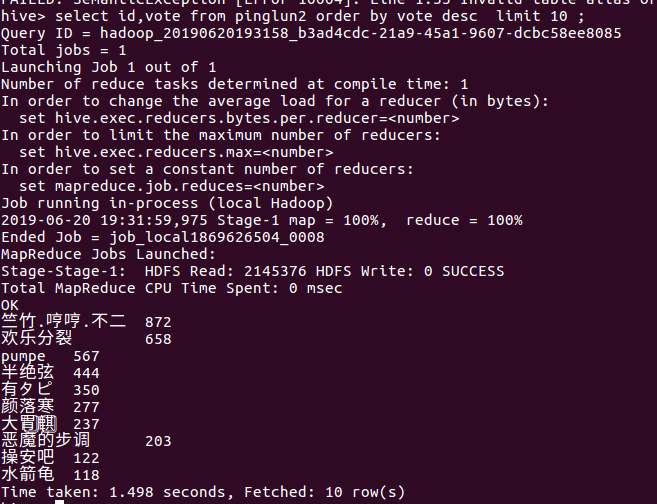
(10)点赞数前10位的用户
五、爬虫数据分析与总结
通过hive数据库查询统计,在爬取的数据的点赞数前10位的评论中我们可以大致看出《恶魔人crybaby》是一部引起人们反思人性、好评度高的好作品,评论中基本都对该作品进行褒美或者是对作品主题“黄暴虐中呼唤爱”作出的感悟,并且得到多数人赞同。而对不相同用户的发表评论条数与去除重复评论内容的评论数进行统计可知对该作品评论可信度高,没有雇请水军刷没有营养的评论的情况。
在本学期的python爬虫的学习中,我对网页的构成与数据的传输有更加深入的了解,也清楚了对爬取的大型数据在linux虚拟机上处理的大致流程。在爬虫学习过程中遇到文件转换乱码与爬取时被反爬的问题,比如我在豆瓣爬取短评时我的IP地址被封禁,账号被永封,在今后的学习中我会努力学习提高爬虫的反爬性能,爬取更多更有效的数据。