该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
关于RPC(Remote Procedure Call),如果没有概念,可以参考一下RMI(Remote Method Invocation)。
简言之,是一种对网络传输细节进行封装,并且对用户暴露被代理对象的一种思想。
我们知道NameNode和客户端一般是不在同一部机器上的,客户端(Client)通过RPC调用NameNode的方法,获得NameNode上
文件目录结构,块映射信息,文件权限,文件所在位置(Locations,也就是DataNode的信息)等等信息资源。
下文将讲解当我们调用FileSystem.create,FileSystem.append,FileSystem.open等方法时,为数据传输做的准备。
这些方法是最主要的方法,其他方法的准备阶段和他们的准备阶段差不多。
1.FileSystem.create搭建的准备环境:
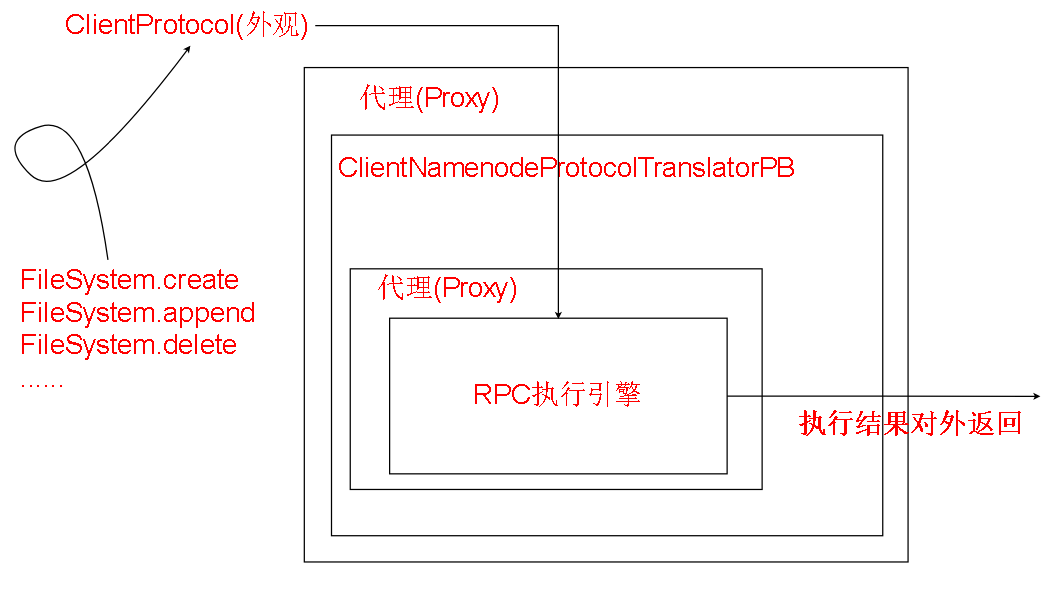
下图是我们调用FileSystem.create方法的时候,最终调用到的关于namenode的地方。
由图可见这里的namenode是一个Proxy(代理),真正的对象其实被封装在代理中。

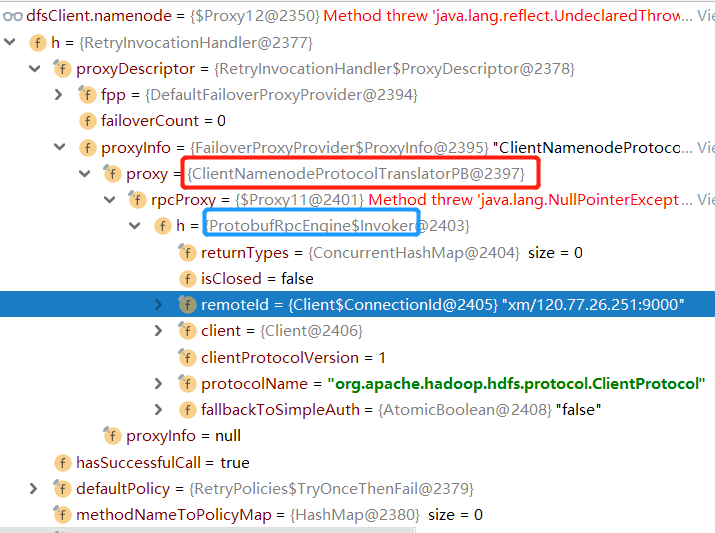
根据JDK动态代理中常用的真实对象->Handler->Proxy$
的封装关系,我们可以看到代理体系中,被代理的第一层(红色框)是一个ClientNamenodeProtocolTranslatorPB的对象
ClientNamenodeProtocolTranslatorPB类中有create,append,delete 等可以向NameNode进行的操作,但他实际上也只是一层壳
实际进行远程调用的还是第二层(蓝色框)ProtobufRpcEngine的Invoker。
下面我们来看看调用Filesystem的create,append,open等方法后,Client这边会得到什么,并且执行什么操作。
当我们调用Filesystem.create , 调用的是namenode的create方法。
![]()
如果NameNode在目录结构中创建文件的元数据成功,那么将会把创建的文件的相关信息返回给客户端
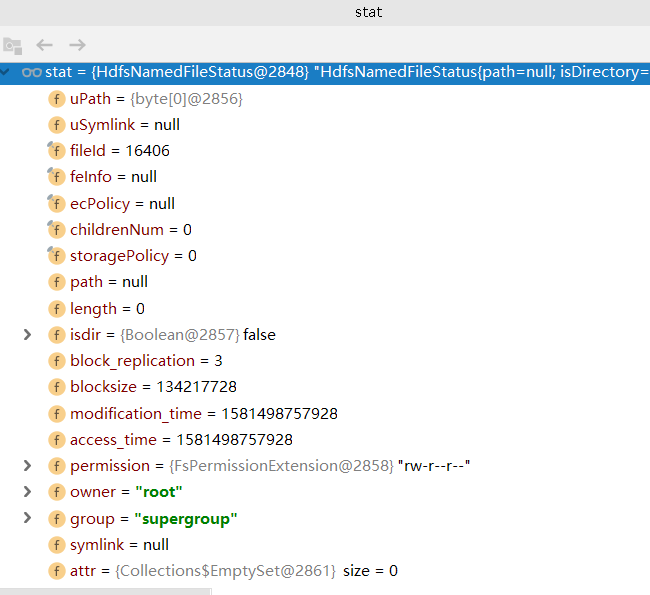
从图中我们可以看到创建的文件的各种信息 比如
文件权限 : rw-r--r-- (对于文件拥有者可读可写,对于拥有者所在群组成员和其他人可读)
备份数 : 3
文件的第一个数据块的信息......
其中值得注意的是文件块(Block)的大小blocksize = 134217728 字节

表明了我们一个块的大小是128MB。128MB是默认值,适用于多数大文件传输的场景。
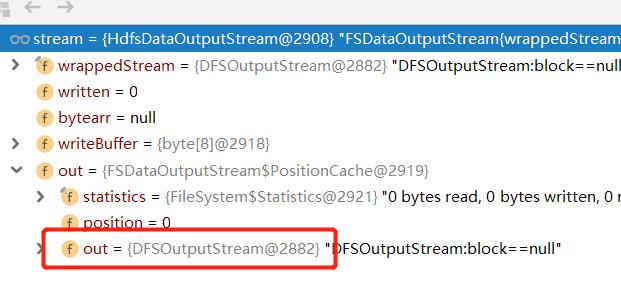
根据文件元数据信息stat,我们创建了一个DFSOutputStream(简化起见将DFSStripedOutputStream与DFSOutStream看作一个讨论,前者其实继承后者)

DFSOutputStream很重要,我们操作的FSDataOutputStream对象中包装了他的对象。
也就是说我们的函数调用实际是DFSOutputStream负责实现的。
并且他负责开启和维护着管理我们数据传输的守护线程DataStreamer
(代码图之后是过程图解)
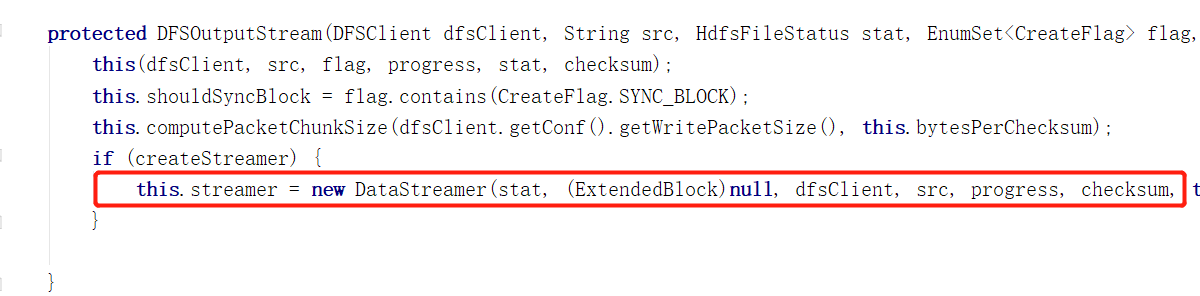
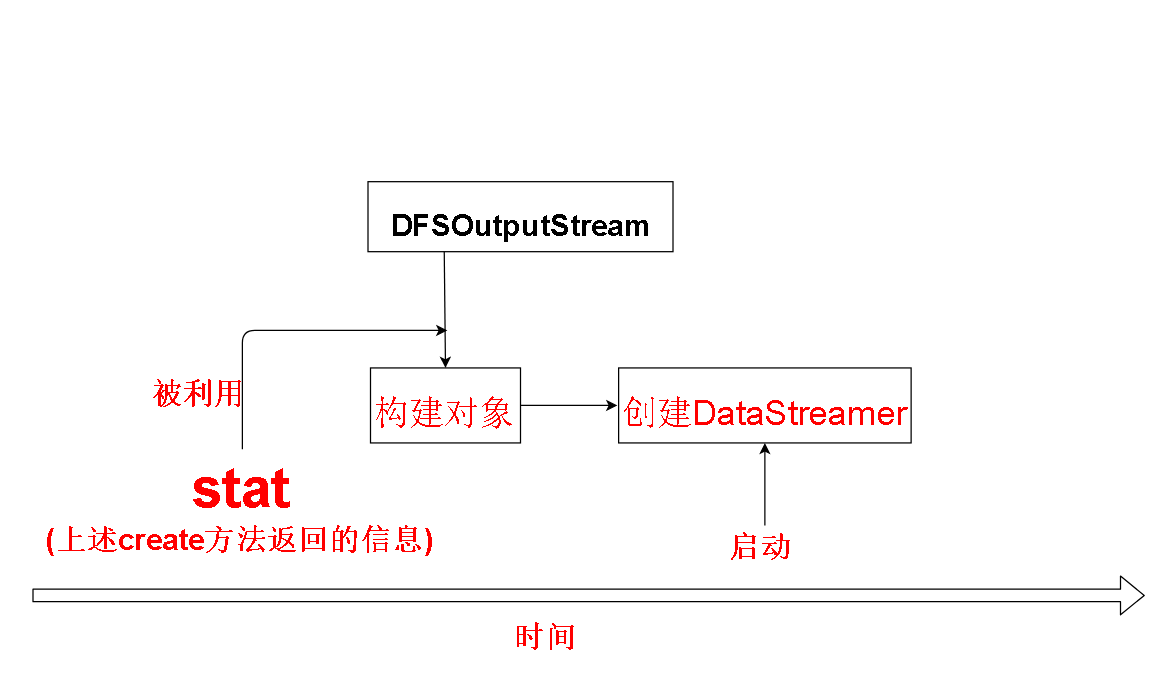
至此,create方法的准备阶段完成。DataStreamer被开启,等待数据被传输。
2.FileSystem.append搭建的准备环境:
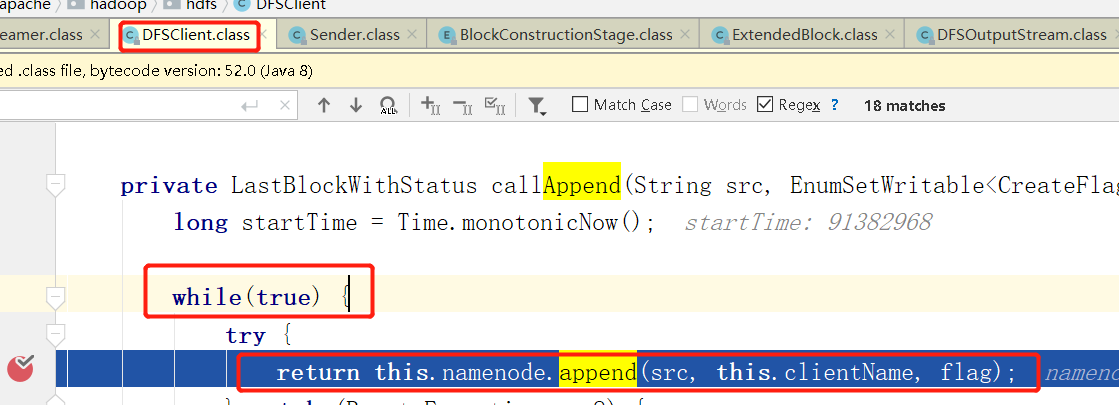
调用FileSystem.append,最终会调用到namenode.append上,也就是RPC调用,和上文原理类似。
我们注意到这里写了while(true)的死循环,主要是如果NameNode繁忙,来不及处理我们的请求的话,就会抛出异常

死循环允许程序产生异常的时候,会休眠一段时间之后重试,而不是直接退出。
如果请求超过了一定时间(5秒),那么将会抛出异常,停止重试。
较为重要的是函数的返回值

我们发现我们从namenode.append那里拿到的东西,有二
一是我们请求append的文件的最后一个数据块的信息
二是我们请求append的文件他本身的信息
比如我们.append("abc/abc");
那么lastBlock返回的是组成abc/abc这个文件的所有数据块中,最后那个数据块的信息。
fileStatus是abc/abc这个文件他本身的信息
我们看看这些信息包括了什么。
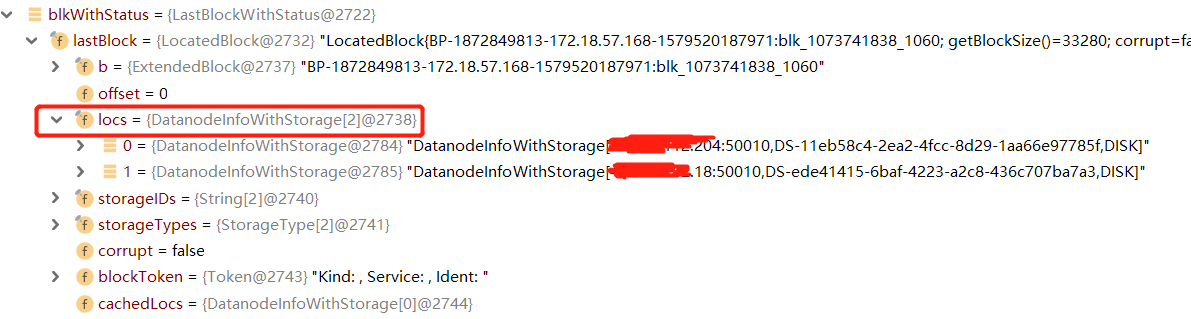
最后一个数据块的信息中,比较重要的是存储这个数据块的位置,位置信息中包含DataNode的IP和端口,根据位置信息,我们可以建立起对块进行读写的流水 线(pipeLine)
fileStatus包含文件的权限,所有者等等关于文件的信息。
和.create方法一样,我们在获取文件信息后也利用文件信息创建了一个DFSOuputStream,并且在DFSOutputStream构造完后也开启了DataStreamer(DataStreamer的创建和启动不在下图中)
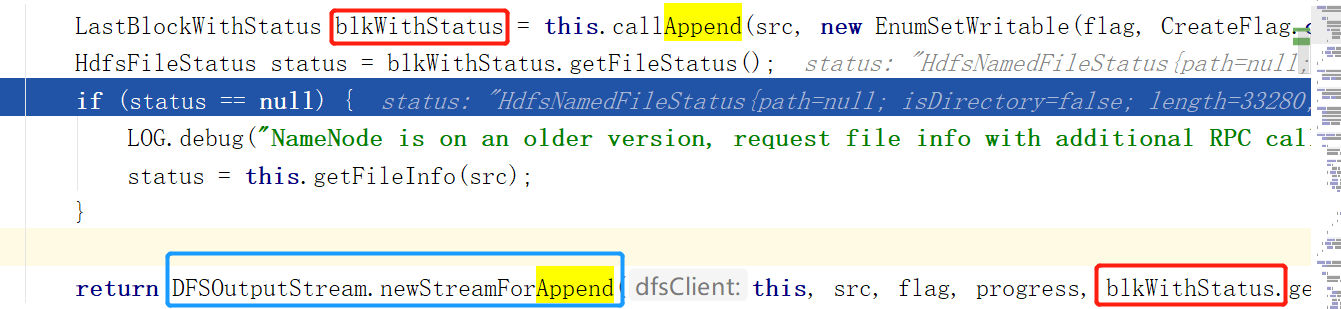
至此,.append的准备阶段完成。
3.open函数做的准备;
当我们调用FileSystem.open , 最终会调用到DFSClient的callGetBlockLocations函数,这个函数通过调用namenode的getBlockLocations获得
数据块的存储位置,我们看看他返回了什么。

一.我们打开只有一个Block的文件
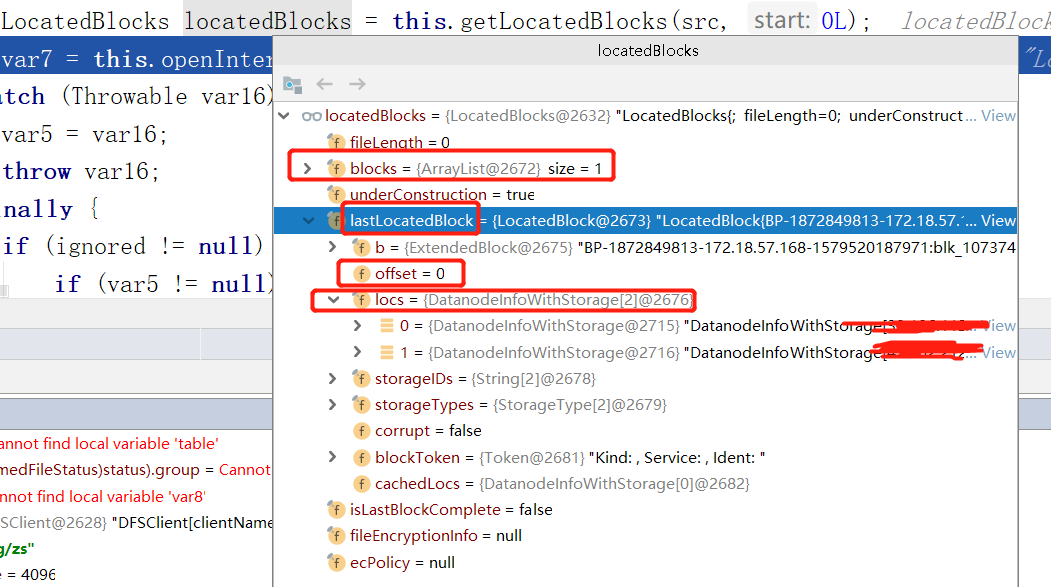
1.我们注意到,blocks(组成文件的数据块),确实只有一个
2.并且lastLocatedBlock(组成文件的最后一个数据块),offset是0,因为只有一个数据块,所以offset是0,等会我们打开有两个数据块的文件,这个值不是0.
3.每个block都有其所在DataNode的位置信息,比较重要的是IP和端口,可以通过他们建立文件读写的流水线
二,我们打开有两个数据块的文件
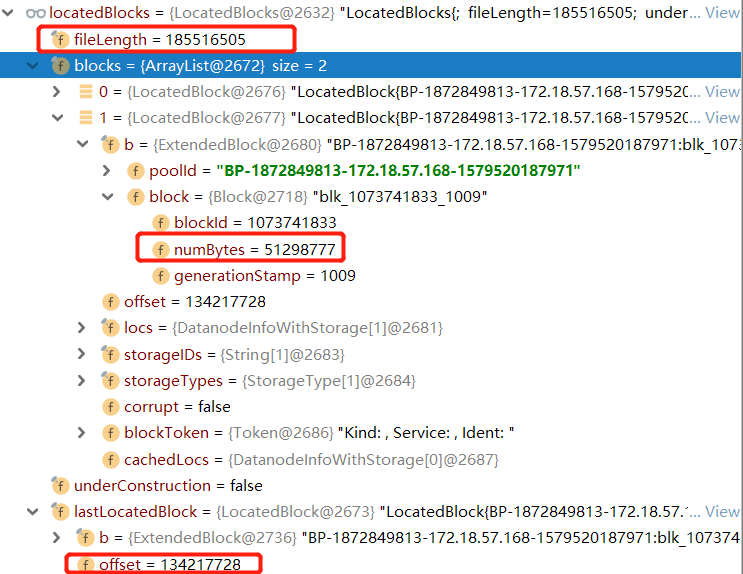
值得注意的是,确实有两个数据块,并且lastLocatedBlock就是第二个数据块(因为只有两个数据块,最后一个数据块当然是第二个数据块)
并且第二个数据块的offerset是134217728(字节),换算后就是128MB, 是较新Hadoop默认的一个Block大小,
我们用文件大小fileLength减去一个数据块的大小 185516505 - 134217728 = 51298777 ,正好是第二个数据块的大小。
获取到关于文件数据块的信息后,调用DFSClient.openInternal
![]()
openInternal会创建DFSInputStream
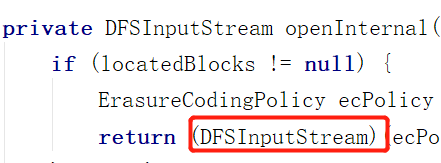
不像DFSOutputStream , DFSInputStream的创建并不会创建DataStreamer守护线程并启动,因为不需要。
至此,三大开启准备阶段的方法的讲解完毕。