该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立)
我们提到,在输出流DFSOutputStream创建后,DataStreamer也随之创建,并且被启动
下文主要是围绕DataStreamer进行讲解
DataStreamer是一个守护线程类,继承关系如下。
观察DataStreamer的run方法,没有意外的,我们可以发现他和普通的做法一样,用一个死循环维持线程执行,直到客户端关闭
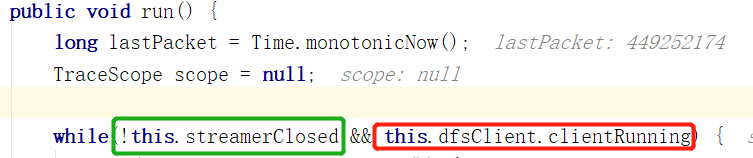
并且通过一个streamerClosed的布尔变量作为开关,控制守护线程的开启与关闭。
这个变量被volatile修饰,根据Happens-Before原则推测,其他线程通过打开或关闭这个开关,来控制DataStreamer的运作。

DataStreamer,从名字上已经能猜到,是一个控制数据传输的类
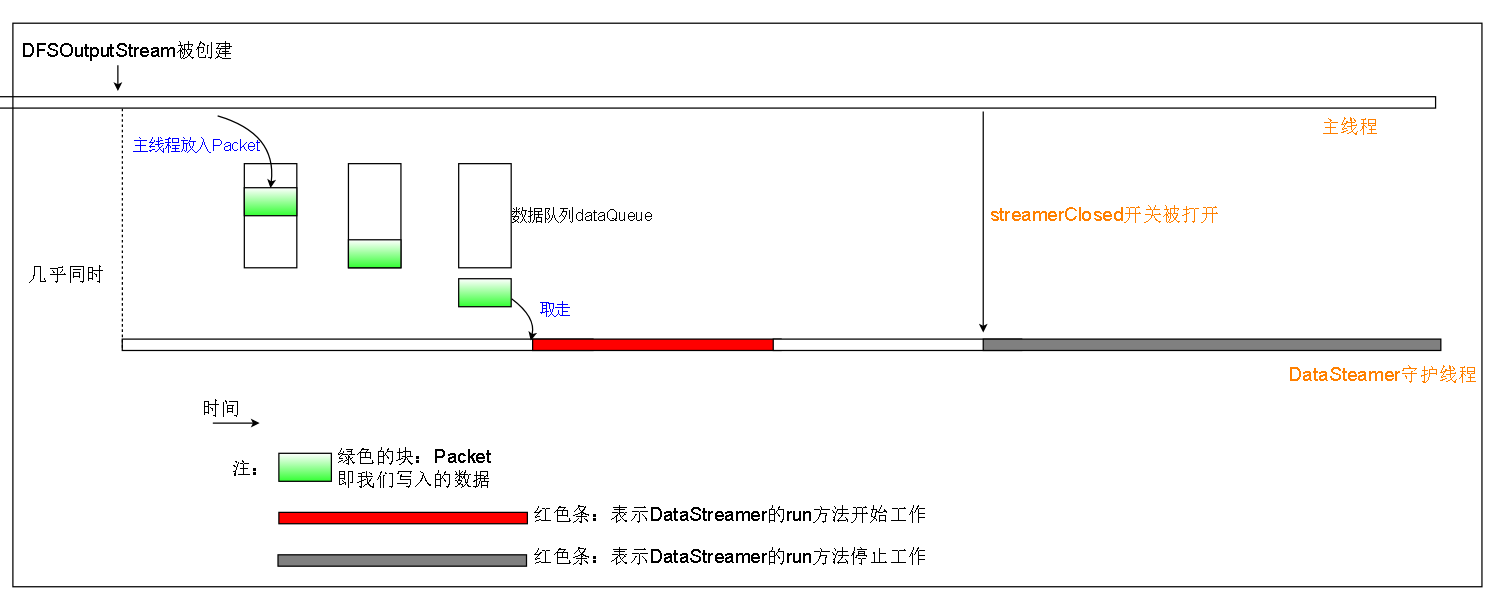
DataStreamer简要的生命周期与主要职责:
1.在DFSOutputStream被创建的时候同时被创建,并且作为一个守护线程,被主线程开启
2.DataStreamer维护一个数据队列dataQueue,并且等待主线程往这个队列放入数据包(Packet),当有数据包的时候开始工作
关于数据包是怎么来的,相关博文 : Hadoop3.1.1源码Client详解 : 入队前数据写入
3.当文件被close的时候,DataStreamer的streamerClosed开关被打开,DataStreamer使命完成
流程图:
重点:分析DataStreamer的工作流程
首先我们要知道DataStreamer是一个有工作状态的守护线程,并且状态存储在stage这个成员变量中。
这个成员变量的类型是枚举BlockConstructionStage,关于这个枚举各个值的含义如下:
关于流水线(PipeLine)以及恢复(Recovery),详见:
Hadoop架构: 流水线(PipeLine)
Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery)
以下分析的是DataStreamer的run方法
以下2张图取自DataStreamer的run方法中,DataStreamer是一个守护线程(下文有介绍),他负责在他的run方法中启动一个循环,一直监听数据队列的动静
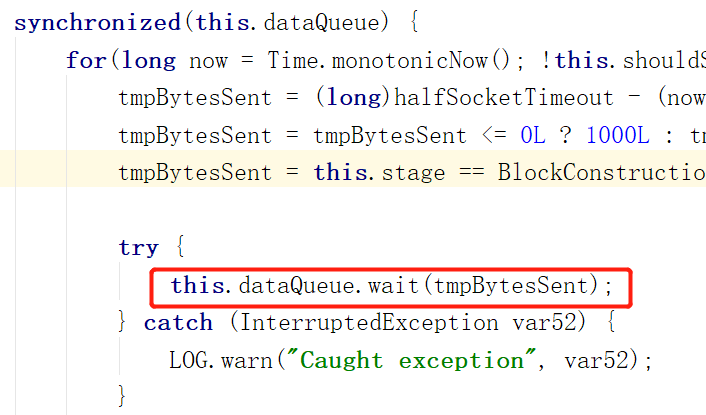
第一张图:
在run方法的while循环中锁住了dataQueue,并且内部有一个for循环,来判断是否让当前线程睡眠一段时间(tmpBytesSent)
进入for循环的条件是 (以下所有条件都要成立)
1.DataStreamer不停止工作
![]()
2.消息队列为空,表示暂时没有数据可传输
![]()
3.DataSteamer不处于数据传输阶段,或者数据包发送较快(未证实是否符合第二个条件意思)
如果不处于发送数据阶段,可能要发送心跳包,而后面的时间可能是用来限制心跳发送频率的。
![]()
或者
1.![]()
doSleep变量为真,而这个变量取决于下图这个方法
![]()
关于这个方法请见:
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 处理异常
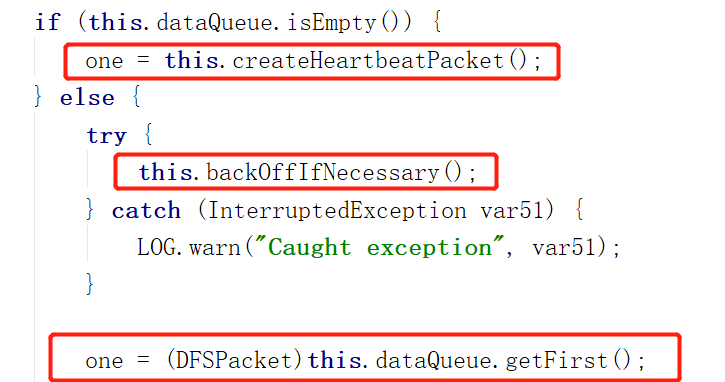
第二张图:
第二张图告诉我们,DataStreamer首先会检查数据队列是否为空,如果是,那么发送给DataNode的将是一个心跳包,来告诉DataNode,客户端还在线(活着),
在队列不空的情况下,会检查客户端的请求是否太过频繁,导致DataNode来不及处理,如果是,则会歇一会(当前线程sleep)。
以上情况都不是的话,才是从数据队列真正获取数据包
获取数据包后做什么呢?
主要是建立起数据传输的流水线,也就是setUp Pipeline
分两种情况建立(红框)
1.当前的数据需要写入新的Block。( 客户端会向NameNode申请新的Block )
![]()
2.当前数据需要写入旧有的Block(Append : 追加) ![]()
分需求架设流水线:

这里提前说一下 this.stage 这个成员变量,这个成员变量的类型是枚举

状态切换简述:当我们调用的是create方法,要新建文件的时候,stage默认是PIPELINE_SETUP_CREATE
当一个块写完之后,需要添加新的块,会在上一个块end掉的时候(调用endBlock),把stage设置成PIPELINE_SETUP_CREATE,这样一来下次流水线也是被建立来创建新的块,达到添加块的目的。

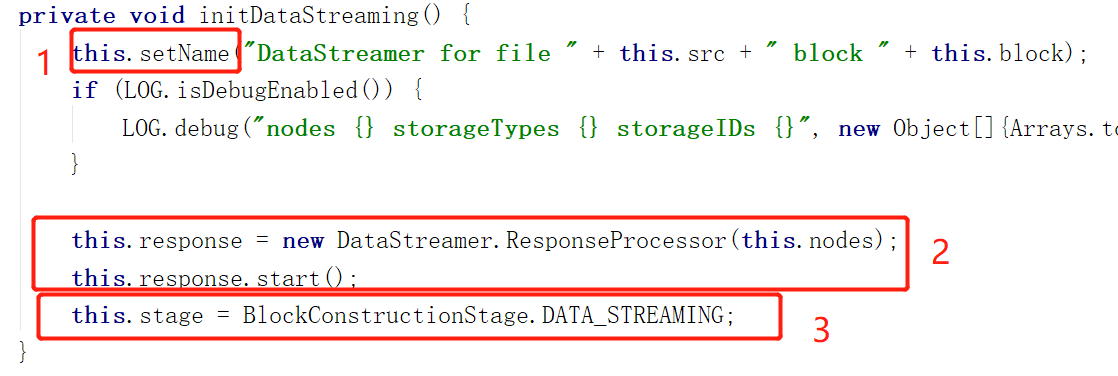
最后蓝色框告诉我们,两中情况除了流水线的建立不同,其他过程并没有什么区别。建立完流水线后共有的操作是调用initDataStreaming函数,这个为数据传输提供环境
1.设置一下当前DataStream的名字(名字由当前正在传输的文件 + 当前正在传输的块组成)
2.创建一个ResponseProcessor,并且开启他,这个线程负责接收DataNode发送回来的ACK(每当我们发出一个数据Packet,DataNode都需要发送ACK回复我们表示他收到了,类似TCP连接)
![]()
3. 将当前DataStreamer状态设置成 DATA_STREAMING,表示正在传输数据
ResponseProcessor可以和DataStreamer线程并行工作,也就是一个负责发,一个负责收,可以同时工作。
我们来看一下ResponseProcessor是怎么处理DataNode发回来的ACK的
首先ResponseProcessor的run方法中维持着一个循环,用来接收ACK。只要ResponseProcessor不被关闭,客户端正在运行,就会一直接收ACK。
什么时候关闭呢?当调用endBlock方法的时候。也就是说每个Block在DataStreamer这对应一个ResponseProcessor来接收ACK,如果一个Block写完了,会调用endBlock把当前的ResponseProcessor
关闭并销毁。当再创建一个块,需要传输数据的时候,会再创建一个ResponseProcessor。
![]()
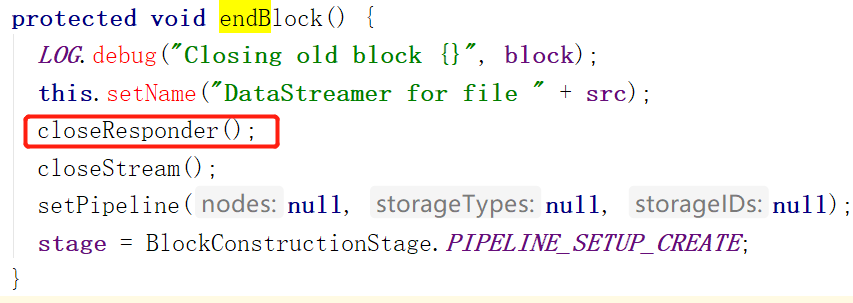

ResponseProcessor具体的工作原理,请见:Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
似乎架设流水线被忘记了。我们一 一道来
请见:
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 流水线架设 : 创建块
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 流水线架设 : 流水线恢复/append
我们接着讲DataStreamer的run方法
紧接着initDataStreaming之后:如果当前要写入流水线的Packet是最后一个包,也就是用来通知流水线上DataNode当前Block已经写完了的包。(称为lastPacket)
那么此处会等待所有lastPacket之前的Packet被确认。然后把流水线状态设置为关闭,但是此时还没有把lastPacket写到流水线上。在把lastPacket写到流水线上到客户端确认lastPacket被DataNode收到
的过程中,流水线可能失败,那么就会发生流水线关闭阶段失败的恢复。详细请见 Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery) 的文末

接着是把Packet进行移动

终于要把Packet写入流水线了。
如果Packet不能成功写入流水线,就会调用markFirstNodeIfNotMarked函数
markFirstNodeIfNotMarked的作用是如果流水线上没有DataNode被认为是不正常工作的。那么将会把第一个DataNode当成是不能工作的DataNode

收尾工作

DataStream从架构流水线到传输Packet的流程讲解完毕。