分工明细
李麒:负责词频统计的设计、编码,类图的构建、性能分析和单元测试,博客代码部分的撰写。
陈德斌:负责爬虫工具学习、使用,博客的爬虫等部分创作
PSP计划表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 330 | 480 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 110 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 20 | 30 |
| Coding | 具体编码 | 90 | 90 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 150 |
| Reporting | 报告 | 120 | 120 |
| Test Repor | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
解题思路描述与设计实现说明
- 爬虫使用
这次爬取使用的是“八爪鱼采集器”。
首先点击图标进入工具的主界面,点击界面上的自定义采集来进行爬取
进入以下界面,选择手动输入项在网址中输入要爬取的网站的网址
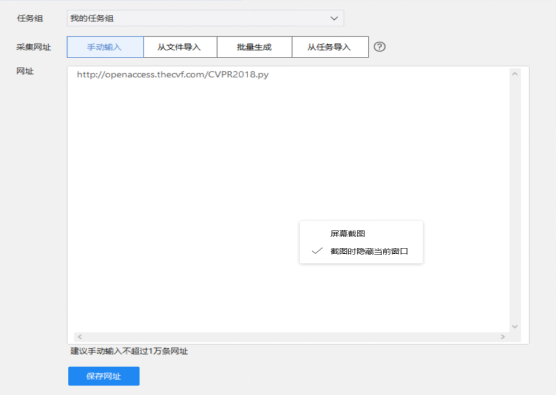
点击保存网址进入网站
这里要说明的是八爪鱼通过鼠标点击网站的元素选择要采集的对象,当鼠标移动到网页元素上的时候那个元素会变色,鼠标点击则选中元素。八爪鱼工具最后会根据选中的顺序按照循环流程一步步执行采集知道采集完毕,具体的流程如何可以点击右上角的流程来查看。
我们要爬取的是文章Title和Abstract,所以我们需要进到各个题目中去选中Title和Abstract。
先选中一个标题,出现界面变成下面这样

按顺序点击“选中全部”、“循环点击每个链接”,之后进入到第一个选中的标题的链接中
我们要的是Title和Abstract下面的内容,点击标题和Abstract下方的文字,点击采集该元素的文本。
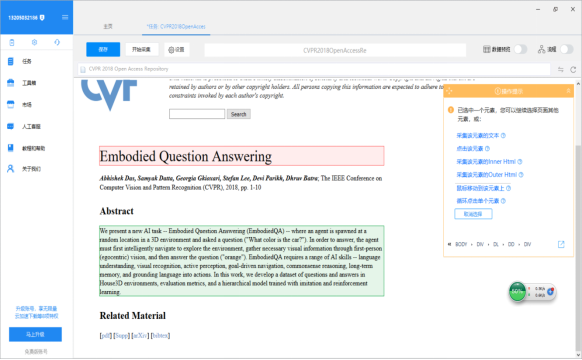
现在我们去流程中确认下采集流程是否有误。
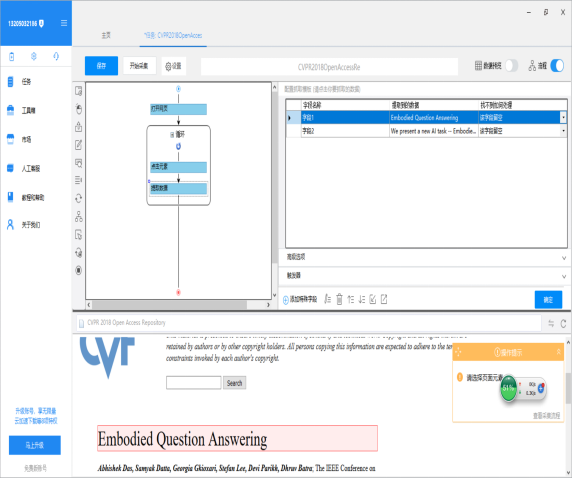

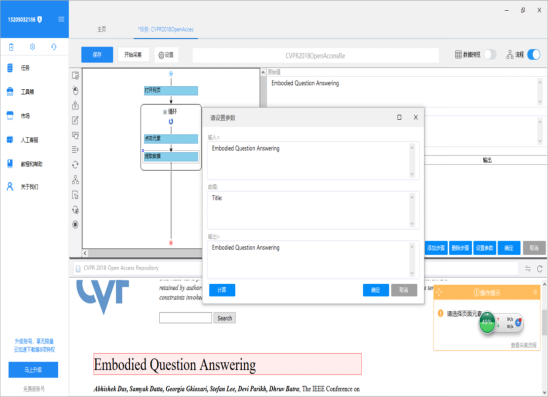
从流程图可以看到等下采集的顺序,工具会逐个点开网站每个论文链接并采集其中的Title和Abstract。这次作业的文件输出有要求规范,所以还要在旁边的字段界面这里设置下格式化的规范,选择“添加步骤”->“添加前缀”来为输出文本添加前缀。确认无误就可以点击左上的开始采集。
最后要注意的是,八爪鱼的输出格式是没有txt的,我们可以把文本输出成其他格式再转格式成txt,我使用的是Excel格式,因为之后还用到了表格对文本进行了一个文件编号,我个人感觉用起来会方便点。
- 代码组织与内部实现设计
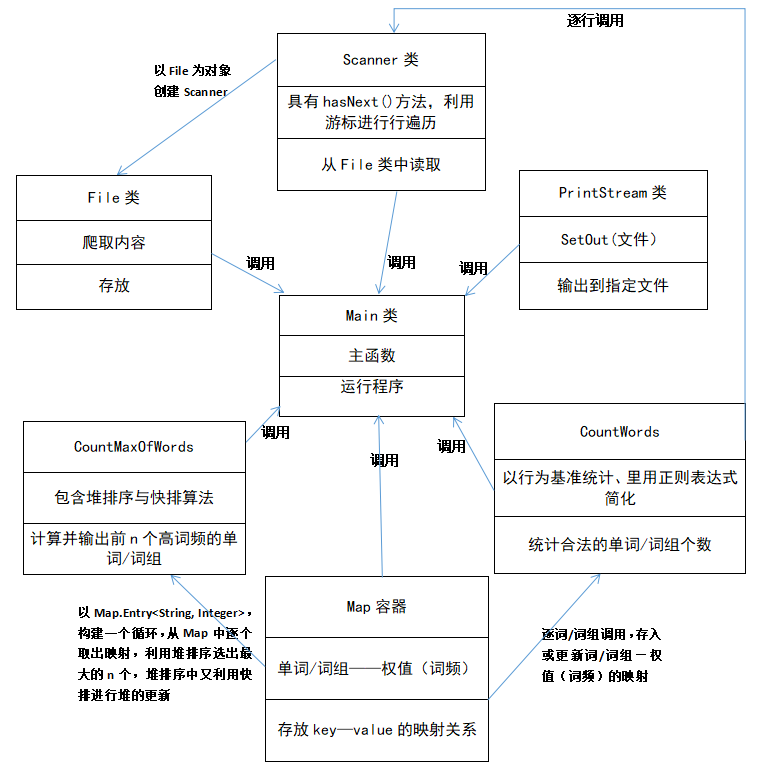
类图:
- 算法的关键与关键实现部分流程图
/*这是两个关键的方法,首先是在while循环内,每次调用一次countWords方法,对每一行统计符合条件的单词数,记录或更新单词/词组的词频;另一个则是在循环结束后,对Map中的数据进行一次遍历,并从中筛选 出符合条件的n组映射;*/
countOfWords += CountWords.countWords(line, words,mn,wn); //CountWords内的static方法countWords
CountMaxOfWords.Sort(words,nn); //CountMaxOfWords内的static方法Sort
CountWords
流程图:
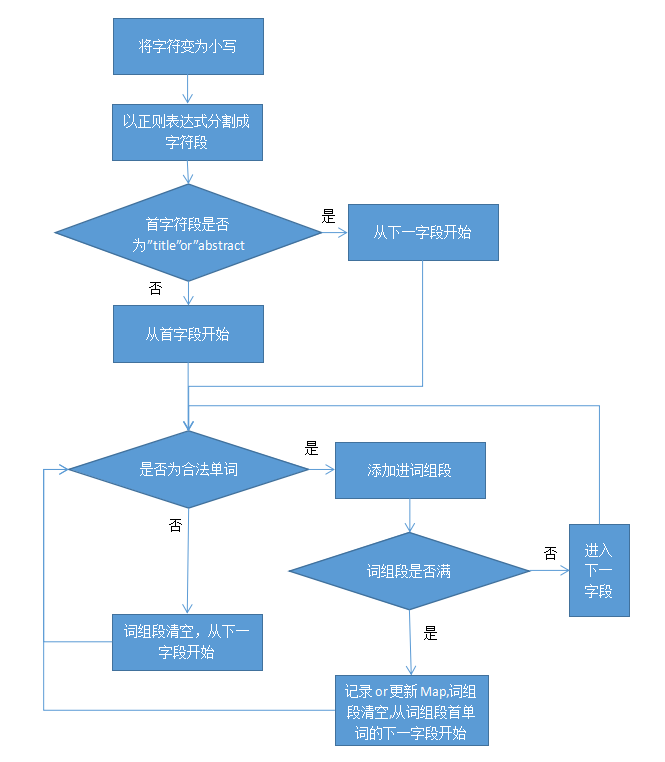
部分代码如下
//判断首字段,k初始值为0.
if((words[0].equals("title"))||(words[0].equals("abstract"))) {
k = 1;
}
//仅mcount=0表示单词合法,进入词组段ww,ww未满,出现非法单词,ww清空
if((mcount == 0)){
if(w == 0) {
ww += words[i];
}
else {
ww +=uu[i]+words[i];
}
w++;
}
if(mcount != 0){
ww = "";
w = 0;
wcount--;
}
//w表示当前词组段单词数,若w="-m"的参数,则进行map的记录或更新,之后ww清空。
if(w == mn) {
if(m.containsKey(ww)){
int v = (Integer)m.get(ww);
v+=t;
m.put(ww,v);
}
else{
m.put(ww,t);
}
ww = "";
w = 0;
i = i-mn+1;//跳转到词组段首单词的下一字段(少1,但外循环for中有i++补足)
}
CountMaxOfWords类
· 流程图:

· 部分代码如下
int s = m.size();
int[] a = new int[nn];
a[0] = 0;
int type = 0;
String[] wd = new String[nn];
/*利用Map.Entry完成对Map内的数据进行以key为基准的遍历,type为一个标准,界定于n内外;
当数组a存放了n组数据后,调用选择排序方法bbsort,将最小数据放入a[0],之后对于新的数据比较value与a[0],大于则插入,并调用bbsort;*/
for(Map.Entry<String, Integer> entry : m.entrySet()){
String k = entry.getKey();
int v = entry.getValue();
if((type < nn)&&(type != s)){
a[type] = v;
wd[type] = k;
type++;
}
i++;
if((type == s)||(type == nn)){
if((v > a[0])&&(i > type-1)){
a[0] = v;
wd[0] = k;
}
bbsort(a,wd,s,nn);
}
}
关键代码解释
File f = new File("文件名");
//创建一个File类f,指向test,txt;
//......
Scanner input = new Scanner(f)//创建一个Scanner类input指向f;
//......
Map<String, Integer> words = new TreeMap<String, Integer>();//创建TreeMap用于词频统计部分;
//利用while循环遍历txt文件内的每一行内容
while (input.hasNext()) {
String line = input.nextLine();
countOfCharacters += line.length();//计算当前行的字符个数
String[] cc = line.split("[^\w\d]+");//拆分字符段
if(!cc[0].matches("[0-9]")) { //舍弃作为序号的行
if((cc[0].equals("Title"))||(cc[0].equals("Abstract")))//由题意,为首的Title或Abstract不计入字符个数,固作个判断
countOfCharacters -= (cc[0].length()+2);
.....
}
}
//两个关键方法,在上述关键算法部分作了解释
countOfWords += CountWords.countWords(line, words,mn,wn); //CountWords内的static方法countWords
CountMaxOfWords.Sort(words,nn); //CountMaxOfWords内的static方法Sort
性能分析与改进
- 问题与改进
在统计最高n个词频的方法中,我利用了堆排序和快排,但是在调用快排的时候,我发现,个人项目由于10的确定性被变为不确定,调用出现了重复调用、覆 盖原数据等问题,通过对方法结构的再分析,完善结构与条件,改进了方法。同时原先对“Title: ”与“Abstract: ”的判定,我是在放在循环中的,我发现将其提出后,用一个k专门去判定,代码的性能会有微笑的提升。
- 展示性能分析图和程序中消耗最大的函数
先展示一个运行结果:
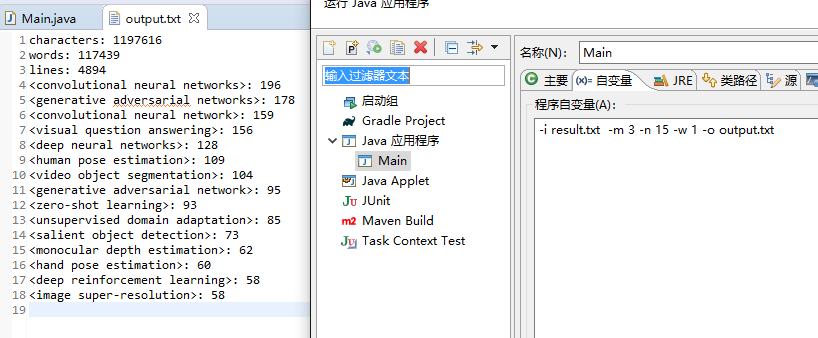
内存的分布: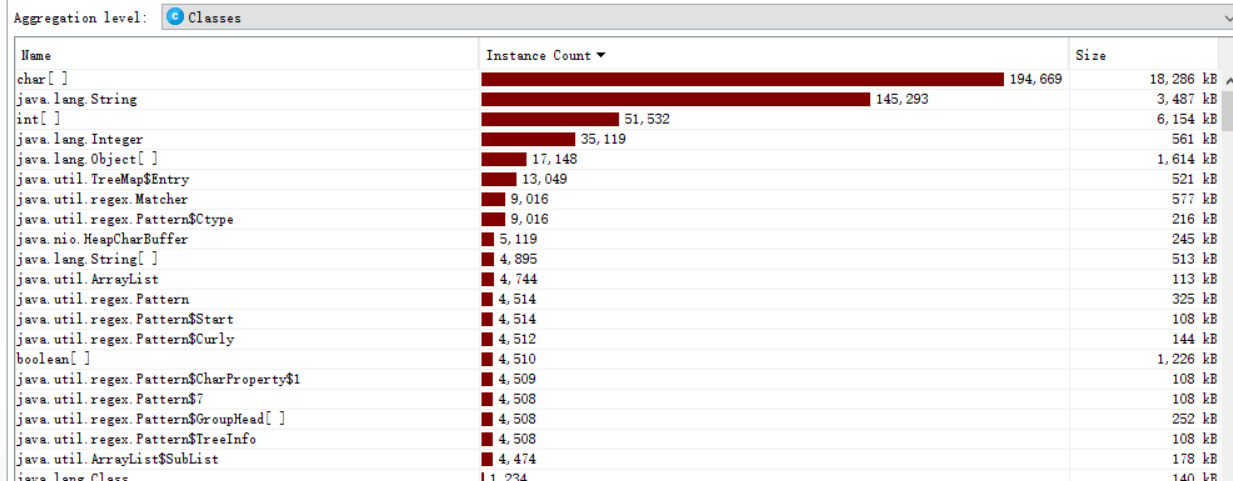
由于在方法CountWords内对单词是否符合条件的判断需要把String内转换成char[],所以char[]比String多,其次就是int[]与Integer,分别在CountMaxOfWords和TreeMap中使用。同时也能看出,方法CountWords是占用率最多的方法。
接下来是代码覆盖率: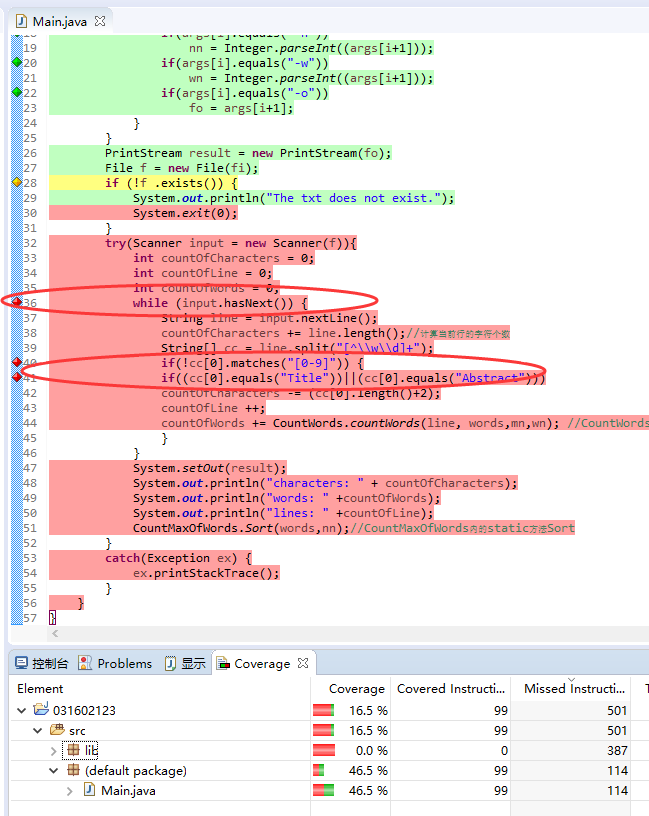
在Main函数中,最大的消耗在于while循环以及其中2个if判断。
单元测试
- 部分测试与结果
1、不输入-i参数;
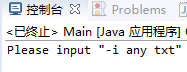
输出:"Please input -i any txt",符合预期
2、不输入-o参数;
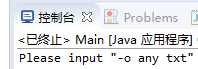
输出:"Please input -o any txt",符合预期
3、不输入m参数,且n>10(取20);
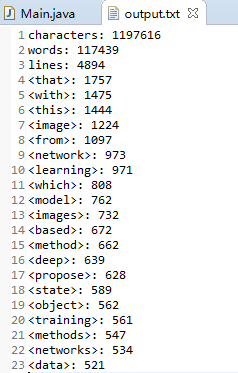
不输入m,默认统计单词,输入n为20,出现了前20词频的单词,符合预期
4、不输入n参数,且m取3;
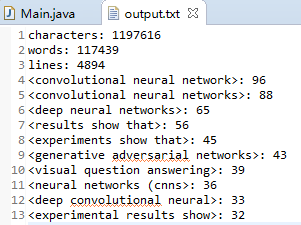
不输入n,默认输出前10词频的词组(单词),输入m为3,出现了个数为3的词组,符合预期
5、读入空文件;
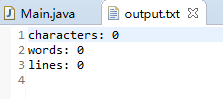
符合预期
思路:首先从参数考虑,其次从文件本身的内容考虑。
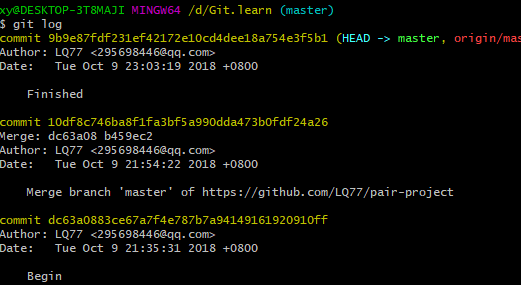
贴出Github的代码签入记录
- commit信息
遇到的代码模块异常或结对困难及解决方法
- 代码方面,虽然有个人项目的基础,但是新功能的加入,十分的考验源代码的结构性与延伸性,在添加功能时,若没有做好处理,非常容易出现代码冗长、杂乱等问题,所幸在第一次项目中的分包处理,对Main函数的变动极小,主要集中在CountWords方法中,而且改动也只针对2个循环,将原来单词的1变为n个单词的组合。但是,这样的改动是否会引起死循环或时间冗长,在这个问题上,研究了很久,最终选取了一个我认为较稳妥的写法。
- 结对方面,都是同班同学,彼此之间交流、分工没有太大的问题。
评价你的队友
- 值得学习的地方
陈德斌同学是个风趣、认真、负责的人,特别能表现的一点就是他上课从来就是在第一排,学习积极性高,值得效仿。
- 需要改进的地方
不够肝,睡得太早了。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 200 | 200 | 6 | 6 | Java复习 |
| 2 | 200 | 15 | 21 | 学习Axure RP8 | |
| 3 | 200 | 400 | 10 | 31 | Java学习 |
| 4 | |||||
| 5 |