1,背诵单词:elevator:电梯 feature:特征 handsome:英俊的 empire:帝国 mate:伙伴,同事 fiction:小说 lip:嘴唇 election:当选 lifetime:一生,寿命
govern:统治 expectation:期待 lay:放置 towel:毛巾 transparent:透明的 reality:现实 recognize:认出 temptation:诱惑 typical:典型的 submarine:潜艇
2,学习spark视频:https://www.bilibili.com/video/av62881491 第50到58集
新添内容到博客:https://www.cnblogs.com/lq13035130506/p/12239342.html
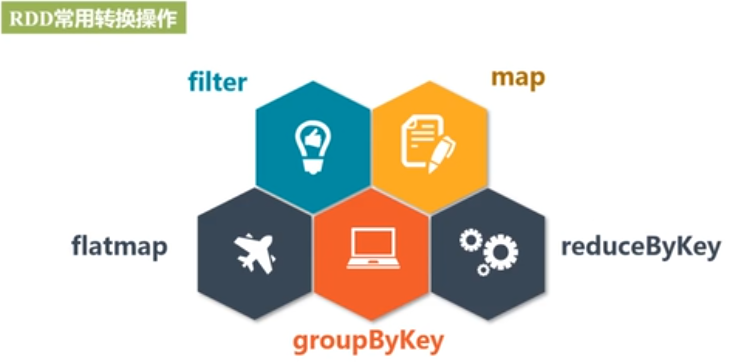
2,操作RDD:
只有到动作类型操作才会进行计算,转换类型操作只会记录


3,RDD持久化
每遇到一次动作操作就会从头到尾计算一次RDD,生成一个job;如果需要前一次的动作操作生成的值,则需要将生成的值缓存
RDD持久化方法:调用.persist()方法对一个RDD标记为持久化,但不会真正持久化;等遇到下一次动作操作就会真正持久化
 会将值存入内存;当内存不足,则替换之前内存存的值
会将值存入内存;当内存不足,则替换之前内存存的值
RDD.persist(MEMORY_ONLY)<=>RDD.cache()
 将值存入内存,当内存不足,会将存不下的值存入磁盘
将值存入内存,当内存不足,会将存不下的值存入磁盘
4,RDD分区:增加程序的并行度实现分布式的计算;减少通信开销;与hdfs的分块不一样
分区原则:

默认分区命令:如果设置local【n】,则分区为n;Apache Mesos模式会默认设置分区为8;standalone和yarn模式设置时,当集群中所有CPU数为n;与另一个?(是什么)比较,值最大的设置为分区数

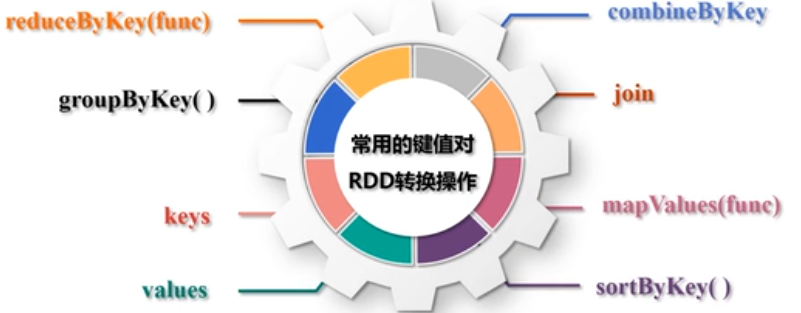
3,键值对RDD:
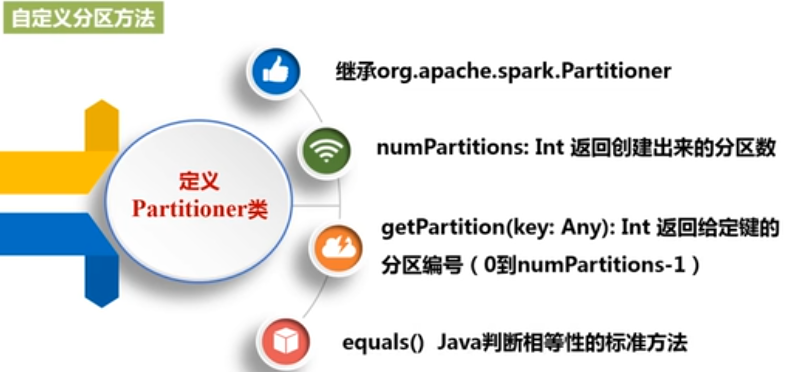
3,遇到的问题:学习RDD分区操作,听得不太懂
4,明天计划继续学习Spark和学习爬取动态数据