1,背诵单词:substitute:替代者,替代物 valid:有效的 wax:蜡,蜡状物 stubborn:顽固的,固执的 abstract:抽象的 ankle:踝关节,踝 occasionally:偶尔 trace:踪迹
export:出口,输出 scan:扫描,细看 stale:陈腐的,不新鲜的 venture:冒险行事 amongst:处在.....中 calculate:计算,估计 victim:牺牲者,受害者
aluminium:铝 explode:使爆炸 variable:变化的,可变的 vote:投票,选举 waiter:侍者,服务员 ton:吨 wolf:狼,贪婪的人 vacation:假期,休眠
2,学习Python爬虫的Scrapy框架的使用观看视频:https://www.bilibili.com/video/av9784617 从48集看到60集
发布博客:https://i-beta.cnblogs.com/posts/edit-done;postId=12254076
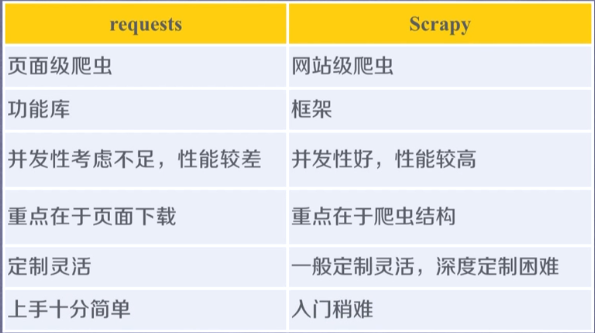
(一)Scrapy库概述
1,安装:运行D:PythonPython36python.exe -m pip install --upgrade pip命令升级
修改Python36文件的权限:https://www.cnblogs.com/liaojiafa/p/5100550.html
安装:D:PythonPython36python.exe -m pip install wheel
安装:D:PythonPython36python.exe -m pip install scrapy
安装过程出了很多问题,比如升级pip要修改Python文件的权限;安装Scrapy库前要安装wheel;还有教程要单独安装Twisted‑xxx‑win_amd64.whl,还有修改名称,结果一直不通过,一点用没有;最重要的是网络要好,不然网速太慢很多文件下载好多分钟最后保错还不知道什么地方出问题了。最后换了一个网,很快就安装成功了。

(二)Scrapy库的使用
爬取某个HTML:
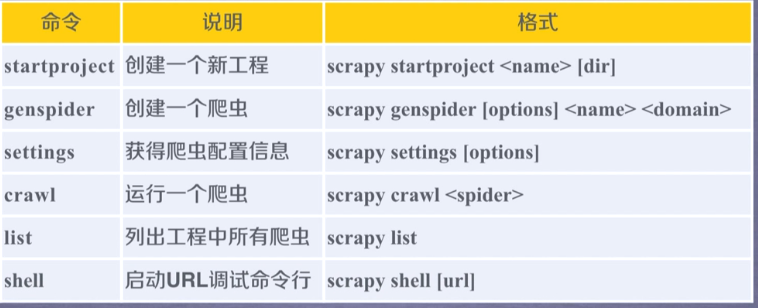
建立过程: scrapy startproject python123demo
建立爬虫demo:scrapy genspider demo python123.io;建立demo.py文件
修改爬虫文件deom.py文件
运行爬虫:scrapy crawl demo
(1)request类:

(2)response类:

(3)Item类:类字典类型,可以按照字典类型操作;表示从HTML中提取的内容
CSS Selector:

3,练习写了爬取股票信息:发现requests库+BeautifulSoup库爬取多个网页时运行速度非常慢

4,明天计划继续背单词;继续学习使用Scrapy库爬取股票数据;学习Spark