(一)正则表达式


(二)正则表达式语法:
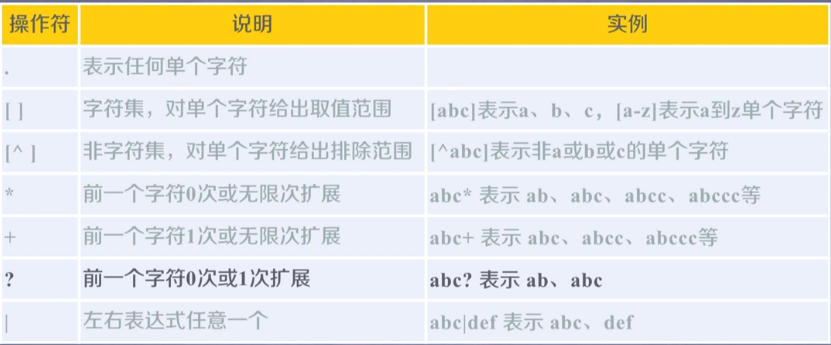
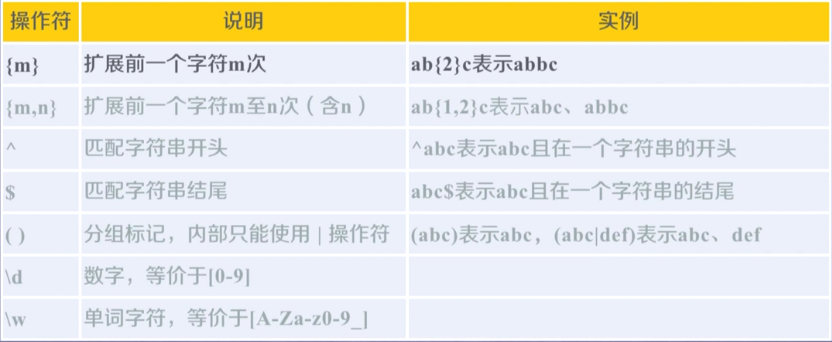
经典例子:

IP地址:



(三)常用方法:

1,第一个方法:re.search()返回match对象


2,第二个方法:re.match():当匹配的第一个字符不符合,则返回空,返回match对象

3,第三个方法:re.findall()

4,第四个方法:re.split()

5,第五个方法:re.finditer()返回match对象

6,第六个方法:re.sub()

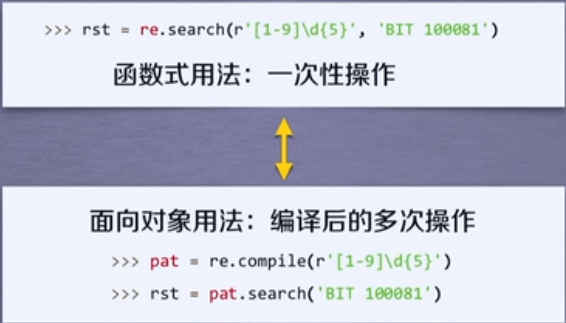
7,第七个方法:re.compile()

8,两种使用re对象的方法的方式:使用面向对象方式时,将正则表达式写入compile()方法中,re对象的方法中就不用正则表达式参数了;

(四)Match对象
1,match对象的属性:

2,match方法:

(五)正则表达式的匹配
1,贪婪匹配

2,最小匹配

例子:
import re rE=re.compile(r"[A-Z].*[A-Z]") ls=rE.search("adaAdssdDsdsFdsdsdM") print(ls.group(0))
截图:

import re rE=re.compile(r"[A-Z].*?[A-Z]") ls=rE.search("adaAdssdDsdsFdsdsdM") print(ls.group(0))
截图:

(六)re库的使用例子
实例一:
1,功能:

2,实现难点:


3,准备工作:
接口:https://s.taobao.com/search?q="搜索的关键词"
分页:第1页:https://s.taobao.com/search?q="搜索的关键词"xxxxxxxxxxxs=0
第2页:https://s.taobao.com/search?q="搜索的关键词"xxxxxxxxxxxs=44
第3页:https://s.taobao.com/search?q="搜索的关键词"xxxxxxxxxxxs=88
商品名称:"raw_title":"uek小学生书包男孩女生1-3-6年级护脊双肩背包6-12岁轻便儿童书包"(存入脚本)
商品价格:"view_price":"198.00"(脚本中)
获取网页请求头的信息方式:
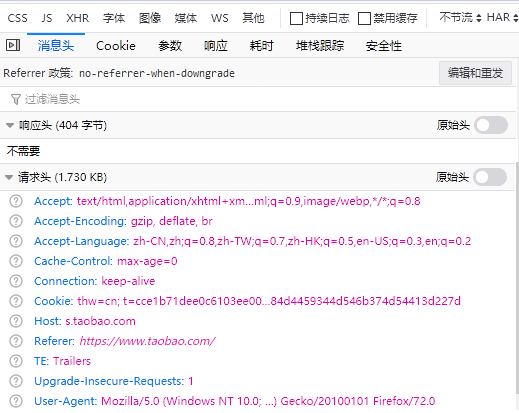
4,实现步骤:

import requests import re #步骤1获取商品页面信息 def getHTMLText(url): kv = {'Cookie':'thw=cn; t=cce1b71dee0c6103ee00c2a80f5d58b8; cookie2=1729efb908bb47c9173e7285b76bcf1f; _tb_token_=37535f9e637ee; _samesite_flag_=true; enc=0MctOlChFlCV5nZPM9I%2BvVj4iB8%2BJrpziCIjwoMf9H8E9LNIgKTgxu8%2BCSUFi9bSBiSB%2FDa5a9LfUco5h2f5%2Bg%3D%3D; JSESSIONID=24C312D5C90EBF0B9899868DCFB187FD; hng=CN%7Czh-CN%7CCNY%7C156; mt=ci=0_0; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; _uab_collina=158054440702373535211543; isg=BMXFMTj6N3FEpBO8M49bhYzg1wH_gnkUQBjla8cqiPwLXuXQj9O75js8aAKoBZHM; l=cBLFG56PQxE7VxgtBOCw5uI8Lz7tjIOYYuPRwCDMi_5Qw6Ls55bOo4N2tFp6csWdOPTB4eJvIYp9-etkiKy06Pt-g3fP.; cna=7ZWXFhLSeHECAd3As7NcDDt3; v=0; miid=664408812090938164; tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5hp3RebXyJYzZUKAW1r6Uz%2FmMSvZbsMK3FmmZCXmyWRkMO1h3bnCN3x3ZrRJ7yYJdsRNoxMHGQpCyrQg3UzMo56H4tZmIQynT2CEisdNFijmGtI6hnUSL2LXCi4gKgBkS8Rgapd4MwIAFja5Js0G49JqnDhbWc1sKw79UmzqcVt7Tw0az0KP0yXz%2B0Li96D%2FooNJq9RYuD5ymYWzhG%2FmPLfTyzOOMEzkaw7usLWvRNcuQeUOw8Aji5KPbwH; x5sec=7b227365617263686170703b32223a223931346262326434363731346639336664383162376333356535323062363562434b377431664546454d4c306c666d38785065696f51456144544d304d5445784d4459344d546b374d54413d227d', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0','Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Connection':'keep-alive','Host':'s.taobao.com','Referer':'https://s.taobao.com/search/_____tmd_____/verify/?nc_token=95d15a040668aef6de1945952b6d3d6f&nc_session_id=01Zi4sj2c1tpzARQSsI0rq4Cgb5Sg381G1L90GIrfuH6mT-4CLxi8J5_8kfLz3jmo6N8HPWMx6QlMWV-Nw9LKhFln6-0AXmw2z9nEi93BnEERLHjVyYXuOUK6PXRbErcqBWuWG0mV-a-DvE0pTXq6UJzeagecKV3_fbyDJFmMMda9Gn-gwOELXRwI79faMGTxFHvJG0DpdSHZOdyTDPcKc6A&nc_sig=05GpvesdJBVOhMKscmy0iTGVDhDcartZBI8_OhtG395T3MbvF8jsEiyBZ7_89OfHOu1nVfPaE5fquc_8txuX6MuF8JQQQg6KQjDn6GhIUSV4fA9h6a7L0JgEFy3pW-zi6nL8tX3gUMBIC4YgQfgM20A7aweY_FNSUFEk-nEfY_Qwzkpdmguqt_-uH0uG2xqNmbhzIiGJzKxLpS1LnjuS6F8jnEPs_3D0-lJiwaplLuVDZq1_zEMGxVwW_8z-7wUDFCWI9DTT7KPOs-J3qa5Yebuw4i27GuhH6ngF7lLWFCfZj6_1L4lvqAx25LM2Tin_MGdXxH5yNP9qr_zDPI2kztLEB0VESqjnwGcZ4Ovek3EkEo2o3GOxbowBqfBsLfhdzrp7i1nHL_dhh2gabB_Lino1sAxQHojeOF39MSL4bxBD5Ffwge4v4hLjRYG86tawsBHxVCueuVDLHjdNsABRbmWC-ezyLl12sTvnDX542Pzls&x5secdata=5e0c8e1365474455070961b803bd560607b52cabf5960afff39b64ce58073f78f68ede033dd239842063c29628191423866f9620b863c667132a90ce579d5cd75c7327bde2bcde85def97069291fa34dbdd96b66a9dff8da5f07d2fd13ea072445cb0ce36cef9f62cbd52852a03cf8ba461ee819ca12264cfd380e1ff9a3181721bc44fcd5aa925118d721cd93646f3e566899a389acd33f04add41433f5dd657f7806228d1f17d85334904897a5fa2e79a52a883b8d79c21b1904b01749f64ff68ede033dd239842063c29628191423f26a33fc19185ca7f5ba435d1801cd576b8357c40b8852e10bee2dd322fdfa01b85d13ca384528f05b373d3a77a70575ad921bb1d36afdc5973c0455682491a957f7918a4f2572499cc398910575bb4ae5b2a48d9c0185c8d8521d59b4860b9243a2952e026506275152d2dce642e18a4440bf0b3e57db00024c36b841c1cc35ed81c65bebf3b9df46dd6afed6f199892c38573d94a1e033206e485398b2371f6578a595e91f44da415c8660f5f2584e2dcd04435273e80c8ba41a4b44ca79f946d7c07b418bd61930fcc7f43085f215602ff14c1eeffa993259bf8351d819eb3f4129c5e95a897ae925e3fabb3e1a8cfc76271052aec7cfa7d67310728cc6e8&x5step=100&nc_app_key=X82Y__2ec484ab2f20befbd6f0aadd26b8bc5b' ,'TE':'Trailers','Upgrade-Insecure-Requests':'1'} #设置访问的请求头,否则会被反爬虫限制登录或验证等 try: r = requests.get(url, headers=kv,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" #步骤2分析页面内容 def parsePage(ilt, html): try: rEo=re.compile(r'"view_price":"[d.]*"') plt=rEo.findall(html) #价格 rEt=re.compile(r'"raw_title":".*?"') tlt=rEt.findall(html) #商品名称 for i in range(len(plt)): #eval()方法去掉双引号,将内容通过:分割 price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("") #步骤3打印商品信息 def printGoodsList(ilt): tplt = "{0:^4} {1:^8} {2:{3}^25}" print(tplt.format("序号", "价格", "商品名称",chr(12288))) print("-"*90) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1],chr(12288))) print("-"*90) #主函数 def main(): goods = '书包' #搜索商品关键词 depth = 3 #设置爬取页面数 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) #第i+1页的URL html = getHTMLText(url) parsePage(infoList, html) except: continue #当某一页爬取错误,则结束继续爬取下一页, printGoodsList(infoList) #程序入口 if __name__=="__main__": main()
截图:

实例二:
1,功能:

2,实现难点:
3,准备工作:网站选取原则:

爬取链接:https://quote.stockstar.com/stock/sha_3_1_x.html 股票综合排名(x从1到53页)
http://q.stock.sohu.com/cn/xxxxxx/index.shtml 搜狐个股股票信息
先爬取股票综合排名:获取股票代码,放入搜狐股票的链接中转到个股信息
爬取股票综合排名网页发现:股票简略信息都在<tbody class="tbody_right" id="datalist"></tbody>中;一个行内是一支股票的信息;一行的第一列是代码,第二列 是股票名称
4,步骤:
import requests; import re import bs4 import traceback from bs4 import BeautifulSoup from idlelib.iomenu import encoding #获取HTML内容 def getHTMLText(url): access={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"} try: r=requests.get(url,headers=access) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "无法连接" #获取股票列表 和个股的URL def getStockList(lst,stockURL): try: page=54 #存放股票列表的一共53页 for i in range(1,page): list_url=stockURL+str(i)+".html" #每一页的URL print(list_url) html=getHTMLText(list_url) #每一页的HTML内容 soup=BeautifulSoup(html,"html.parser") tbody=soup.find(id="datalist") #查找有股票内容的tbody for tr in tbody.children: if isinstance(tr, bs4.element.Tag): #排除非标签的子节点 td=tr('td') #每一行的td列表 code=td[0].string #每个股票代码 stockName=td[1].string #每个股票名称 lst.append(code) #将每个股票代码存入列表lst except: print("获取错误") #获得个股股票信息,并存入列表,把信息存入本地文件 def getStockInfo(lst,stockURL,fpath): cond=1 #显示进度变量,初始值为1 for code in lst: url=stockURL+code+"/gp" try: print(url) html=getHTMLText(url) infoDict={} soup=BeautifulSoup(html,"html.parser") div2=soup.find(name="div",attrs={"class":"content clear"}) #里面是基本信息 div1=soup.find(name="div",attrs={"class":"title_bg"}) #里面是名称和代码 messaget=div1.find_all(name="h1") #里面是名称和代码 message=div2.find_all(name="span") #里面是基本信息 stock_name=messaget[0].string #股票名称 stock_code=messaget[1].string #股票代码 span1=message[::2] #span1为message列表的偶数位数据组成的列表 span2=message[1::2] #span2为message列表的奇数位数据组成的列表 stock_price=span1[0].string #股票价格 stock_change_point=span1[1].string #股票变化点 infoDict.update({"股票名称":stock_name,"股票代码":stock_code,"今日股票价格":stock_price,"今日变化点数":stock_change_point}) key=[] val=[] for i in span1[2:15]: rE=r"[[a-z]{0,2}d{0,4}]" agei=re.sub(rE,"",i.string) agei="".join(agei.split()) key.append(agei) #key中存放股票汉字提示信息 for j in span2[1:15]: #val中存放股票数据信息 val.append(j.string) key.insert(0, "涨跌幅") print(key[1]) for i in range(len(key)): kv=key[i] va=val[i] infoDict[kv]=va #新增内容 with open(fpath,'a',encoding="utf-8") as f: f.write(str(infoDict)+" ") cond+=1 print(" 当前速度:{:.2f}%".format(cont*100/len(lst)),end="") # 被禁用 except: cond+=1 print(" 当前速度:{:.2f}%".format(cont*100/len(lst)),end="") print("执行错误") traceback.print_exc() #continue #主函数 def main(): stock_list_url="https://quote.stockstar.com/stock/sha_3_1_" lst=[] stock_info_url="http://gu.qq.com/" out_put_file="D://stock.txt" getStockList(lst, stock_list_url) getStockInfo(lst,stock_info_url, out_put_file) #程序入口 main()
截图:

5,不足:爬取股票列表和个股网页部分没有爬取到,爬取速度慢。
只能爬取HTML中的静态数据,不能爬取动态数据