(一)使用Beautiful Soup库(默认将HTML转换为utf-8编码)
1,安装Beautiful Soup库:pip install beautifulsoup4
2,简单使用:
import requests; from _socket import timeout from bs4 import BeautifulSoup #使用Beautiful Soup库需要导包 #from aifc import data def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() #如果连接状态不是200,则引发HTTPError异常 r.encoding=r.apparent_encoding #使返回的编码正常 print("连接成功") return r.status_code except: print("连接异常") return r.status_code url="https://python123.io/ws/demo.html" #keywords={"ip":"202.204.80.112"} access={"user-agent":"Mozilla/5.0"} #设置访问网站为浏览器Mozilla5.0 if getHTMLText(url)==200: r=requests.get(url, headers=access) #print(r.encoding) r.encoding=r.apparent_encoding demo=r.text soup=BeautifulSoup(demo,"html.parser") #解析HTML页面,使用html.parser解析器 print(soup.prettify()) #打印HTML代码
print(soup.a.attrs) #打印出该HTML文件的第一个a标签的属性,获得一个字典型数据;可以根据soup.a.attrs['href']获取链接
print(soup.a.name) #打印第一个a标签的标签名
print(soup.a.parent.name) #打印出第一个a标签的父标签的标签名
3,原理:


(二)提取网页内容
1,基本要素

2,使用beautiful Soup库进行HTML遍历
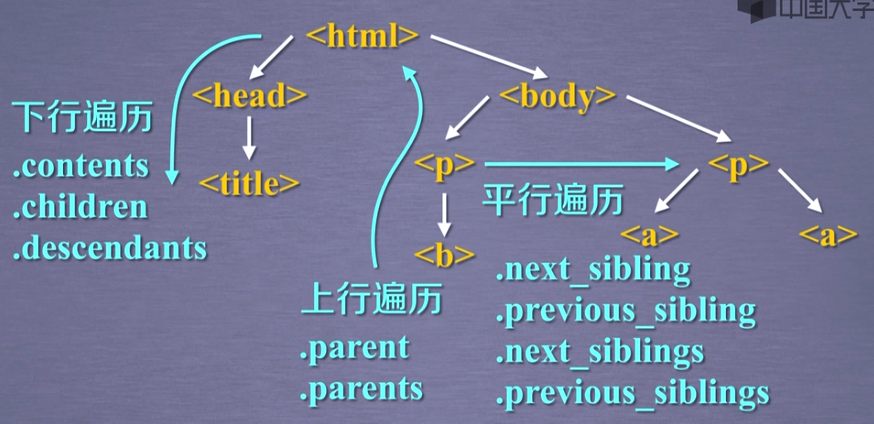

.contents返回列表类型;.children和.descendants返回的是迭代类型,只能用在for循环中

soup的父节点为空,返回None


平行遍历发生在一个父节点下的子节点;平行遍历可能不会获得下一个标签

3,更好的获得HTML的内容:
soup.prettify()方法:可以将获取的HTML内容进行格式美化,使用print方法打印HTML内容
(三)信息标记:


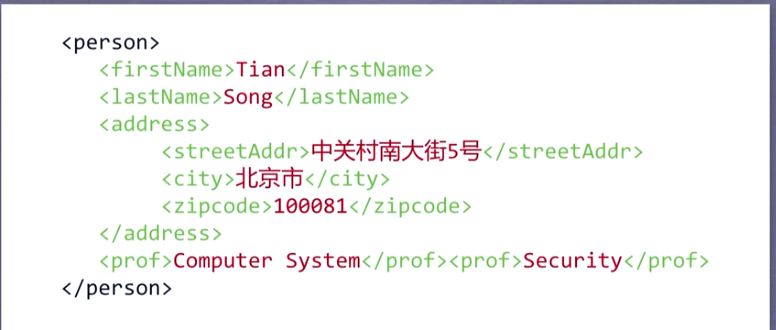
1,JSON三种形式:
1,"name":"value",一键一值
2,"name":["value1","value2"],一键多值
3,"name":{“name1”:"value1","name2":"value2"},嵌套键,值
2,YAML:无类型键值对,类Python使用缩进表示所属关系,


3,同样的信息使用三种不同形式表示和区别:



4,信息提取:融合两种方法


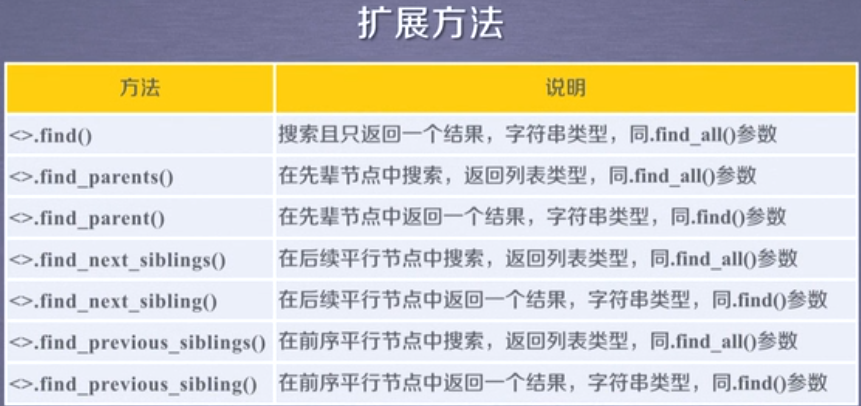
5,查找函数:

简写为:

当find_all函数的第一个参数name为True,则返回所有的标签信息;第一个参数可以为列表,存放想要查找的所有标签名
第二个参数attres可以通过设置为id="id名"准确查找相关信息;也可以直接设置为"class名"查找相关信息;
第三个参数为True,则在当前标签中查找子孙节点相关的标签或属性等;参数为False,则只在当前标签中查找子节点是否符合,不会去检索孙节点;
可以给参数赋值正则表达式:导入re库;re.compile("匹配部分字符串");来进行HTML的模糊检索
(四)实例:
爬取最好大学网的2019年的大学排名 :爬取网站:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html
使用bs4库只能爬取网页的静态数据,我们首先要查看网页源代码,查看大学排名信息是否是直接写在HTML中;发现大学排名信息是写在网站的HTML中
然后查看robots协议内容;发现该网站没有robots.txt文件

步骤一:getHTMLText()
步骤二:定义存储数据结构为二维列表;fillUniversity()
步骤三:printUniversity()
开始爬取:
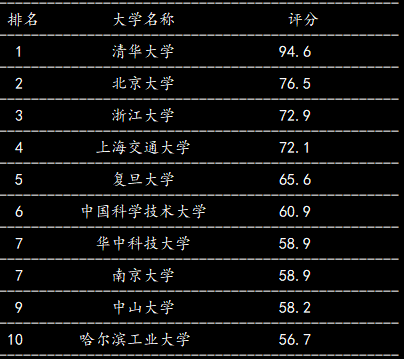
import requests; import re import bs4 from bs4 import BeautifulSoup #获取URL的HTML内容 def getHTMLText(url): try: access={"user-agent":"Mozilla/5.0"} #设置访问网站为浏览器Mozilla5.0 r=requests.get(url,timeout=300,headers=access) r.raise_for_status() #如果连接状态不是200,则引发HTTPError异常 r.encoding=r.apparent_encoding #使返回的编码正常 print("连接成功") return r.text except: print("连接异常") return "" #提取HTML的大学排名信息并将信息填入ulist:存储结构(二维列表) def fillUniversity(ulist,html): soup=BeautifulSoup(html,"html.parser") for tr in soup.find("tbody").children: if isinstance(tr, bs4.element.Tag): #排除子节点中非标签的节点 tds=tr('td') ulist.append([tds[0].string,tds[1].string,tds[3].string]) #输出排名信息;先输出表头,然后输出具体信息 def printUniversity(ulist,num): print("-"*50) print("{:^5s} {:^20s} {:^10s}".format("排名","学校排名","评分")) #{^10}中^表示内容居中为10格宽对齐,10表示输出长度 print("-"*50) for i in range(num): #ulist是一个二维数组型列表,每个数据也是一个一维数组,遍历ulist中前200个数据 u=ulist[i] print("{:^5s} {:^20s} {:^10s}".format(u[0],u[1],u[2])) #format函数^对齐输出中文字符时默认使用西文字符的空格填充,导致中文对齐效果不好 print("-"*50) #主函数 def main(): uinfo=[] url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html" #大学排名网 html=getHTMLText(url) fillUniversity(uinfo, html) printUniversity(uinfo, 200) #获取排名前200个学校 #启动主函数 if __name__=="__main__": main()
截图:


优化后的输出函数:
def printUniversity(ulist,num): print("-"*50) str="{0:^5} {1:{3}^10} {2:^10}" #{3}指使用format函数的第三个变量进行填充, print(str.format("排名","大学名称","评分",chr(12288))) print("-"*50) for i in range(num): u=ulist[i] print(str.format(u[0],u[1],u[2],chr(12288))) print("-"*50)