例一:对目录下的单词文件进行单词统计
/word/first.txt: /word/second.txt: /word/third.txt:



运行结果:

import java.io.File; import java.io.PrintWriter; import scala.io.Source; import collection.mutable.Map; import collection.SortedMap; object WordCount { def main(args: Array[String]): Unit = { var file=new File("/mnt/hgfs/D/Scala程序/word"); //word目录下有多个.txt文件 var files=file.listFiles; //把目录下文件全部列出 var results=Map.empty[String,Int]; //定义空的映射 for(file<-files){ //遍历每个单词文件 val data=Source.fromFile(file); //将一个单词文件的内容读到data中 val strs=data.getLines.flatMap{s=>s.split(" ")}; //读取每行后成为一个集合,将集合遍历后对每个元素(每行)执行分割操作,最后将所有单词放在一个集合 strs.foreach{ //如果映射中存在键为:单词word,则值加1,否则将值设为1; word=>if(results.contains(word)) results(word)+=1 else results(word)=1; } } //results.valuesIterator.reduceLeft((x,y) => if(x > y) x else y); results.foreach{ //遍历输出映射 case(k,v)=> println(s"单词:$k 次数:$v"); // val inputFile=new PrintWriter("/mnt/hgfs/D/Scala程序/wordcount.txt") // inputFile.println(s"单词:$k 次数:$v"); // inputFile.close(); } } }
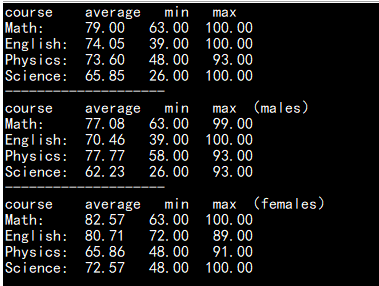
例二:根据TXT文件给的学生各科成绩统计学生总体,男士 ,女生的各科平均成绩,最低成绩,最高成绩:
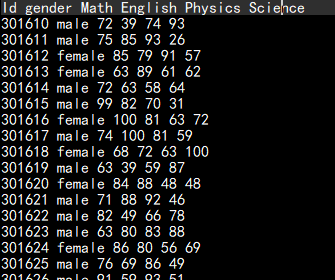
text2.txt:
package en object scoreReport { def main(args: Array[String]) { // 数据文件在当前目录下 val inputFile = scala.io.Source.fromFile("test2.txt") //”\s+“是字符串正则表达式,匹配任何空白符,将每行按空白字符(包括空格/制表符)分开// 由于可能涉及多次遍历,同toList将Iterator装为List // originalData的类型为List[Array[String]] val originalData = inputFile.getLines.map { _.split("\s+") }.toList val courseNames = originalData.head.drop(2) //获取第一行中的课程名drop函數:選擇头部除了前2个以外的元素 val allStudents = originalData.tail // 去除第一行剩下的数据 val courseNum = courseNames.length //3个 // 统计函数,参数为需要常用统计的行 //用到了外部变量courseNum,属于闭包函 def statistc(lines: List[Array[String]]) = { // for推导式,对每门课程生成一个三元组,分别表示总分,最低分和最高分 (for (i <- 2 to courseNum + 1) yield { // 取出需要统计的列 val temp = lines map { elem => elem(i).toDouble } //中缀表达式 elem(i)取出每行的成绩 (temp.sum, temp.min, temp.max) }) map { case (total, min, max) => (total / lines.length, min, max) } // 最后一个map对for的结果进行修改,将总分转为平均分 } // 输出结果函数 def printResult(theresult: Seq[(Double, Double, Double)]) { // 遍历前调用zip方法将课程名容器和结果容器合并,合并结果为二元组容器 (courseNames zip theresult) foreach { case (course, result) => println(f"${course + ":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f") } } // 分别调用两个函数统计全体学生并输出结果 val allResult = statistc(allStudents) println("course average min max") printResult(allResult) println("-"*20) //按性别划分为两个容器 val (maleLines, femaleLines) = allStudents partition{ _(1) == "male" } //partition函数,根据给定的字符串将一个分为两个容器 // 分别调用两个函数统计男学生并输出结果 val maleResult = statistc(maleLines) println("course average min max (males)") printResult(maleResult) println("-"*20) // 分别调用两个函数统计女学生并输出结果 val femaleResult =statistc(femaleLines) println("course average min max (females)") printResult(femaleResult) } }
截图: