为了快速随机存取文件中的记录,可以使用索引结构。不管是从字面意思来讲,还是从生活的其他领域来讲,索引都可以被解释为快速定位。
一.聚集索引和非聚集索引
1.聚集索引:包含记录的文件按照某个搜索码指定的顺序排序,那该搜索码对应的索引称为聚集索引;也称为主索引;
2.非聚集索引:搜索码指定的顺序与文件中记录的物理顺序不同的索引;也称为辅助索引;
这里“索引”是个抽象的概念,或者说是一个状态概念,而不是具体的某个索引文件;在某个搜索码上建立了索引,我们就说某个属性有索引。所以说,记录文件和索引文件是不同的概念,下面我们来说明
二.索引记录和索引顺序文件
1.索引记录(索引项)是由一个搜索码值和指向具有该搜索码值得一个或多个记录的指针构成,是在某个搜索码上建立了索引之后生成的;
这里的指针指向的是磁盘空间(磁盘块的标识,标识磁盘块内内记录的块内偏移量);
2.索引顺序文件是指在某个搜索码上有聚集索引的文件;
所以可以说,索引记录是在记录文件(简单理解为一个表)的某个属性上建立了索引而生成的;
三.顺序索引的分类
1.稠密索引:文件中每个搜索码值都有一个索引记录;
2.稀疏索引:相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的搜索码值的索引项,然后从该记录开始向后顺序查询直到找到为止。
分情况看利弊,如果记录量适中,用稠密索引可以获得较好的响应时间;
如果记录量很多,百万级的,用稠密索引,索引(文件)本身就很难以去维护,因为搜索索引时的跨磁盘块数就至关重要(因为处理数据库请求的主要时间开销就是把块从磁盘读到主存的时间),而索引在磁盘上以顺序文件存储,对数量很多的索引记录的查询就会涉及到多个块,这是我们不希望的。但是对每个块建立稀疏索引已经是公认的利远远大于弊的做法。
对于上述庞大稠密索引的解决办法之一就是建立多级索引,于是就引出了B+树索引的理念。两个概念很像,但是也有不同;
四.B+树索引
索引顺序文件组织最大的缺点就在于,随着文件的增大,索引查找性能和数据扫描性能都会下降。
B+树索引结构是使用最为广泛的,在数据插入和删除的情况下仍能保持执行效率的几种索引结构之一。
B+树索引中的B就是Balance,顾名思义,平衡树,是B树的一种变形;
B+树索引虽然在有数据插入和删除时效率不高,但是,用自己的话来说,就是B+树能做到一步到位,一劳永逸,加上其在查找上的高效,所以才能受到追捧。
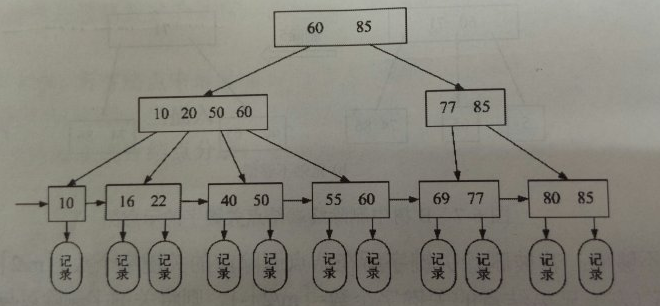
上图是一个B+树示意图,叶子节点直接存储记录,在搜索时按照稀疏索引的搜索方法,找到大于最小(相当于小于等于)的那个节点,一级一级往下搜索。
关于B+树的增删导致的节点变动这里不再说了,具体内容可参照数据结构。
五.散列索引
顺序文件组织的一个缺点是我们必须访问索引结构来定位数据,或者使用二分搜索,导致过多的I/O,基于散列的文件组织使我们能够避免访问索引结构,直接定位数据。
散列技术大体上是依赖散列函数,把搜索码值直接映射到磁盘(桶)上的一系列操作;这是一种文件系统中的文件组织和管理技术。
桶(bucket)表示能存储一条或多条记录的一个存储单位;通常一个桶就是一个磁盘块。
散列函数应该具有的性质:
1.使搜索码分布均匀;
2.使搜索码随机分布;即在一般情况下,每个桶分配到的搜索码不应该与搜索码值之外的任何可见排序相关,并且分配到每个桶的搜索码数目应该几乎相同。
例如,如果我们把某些商标或名字的首字母映射到对应的26个桶中,这个映射就不符合上述性质,因为很多人倾向于取前几个字母作为名字的首字母,这样就导致数据的分布不均;
一.静态散列
这种散列技术在数据库设计初期就确定了散列函数和桶的数量;这就是所谓的静态;
一个紧临的问题就是,如果在数据库壮大的过程中桶或桶内空间不够用了怎么办?这就是牵扯到桶溢出处理,桶溢出的发生可能有一下几个原因;
1.桶不足:桶的数目小于记录总数/一个桶能存放的记录数;
2.偏斜:某些桶分配到的记录比其他桶多,所以即使其他同仍有空间,某个通仍可能是溢出的。
为了减少第一种可能,一般多取20%的桶。至于第二种可能,我们用溢出桶解决。溢出桶就是在已满的桶后面链接一个新的桶,从而把这个链上的所有桶看成是一个桶,在插入数据时向后顺延。
静态散列索引将搜索码及其相应的指针组织成散列文件结构;具体的做法是,将散列函数作用于搜索码以确定对应的桶,然后将此搜索码以及相应的指针存入此桶中。
一般,使用散列索引来表示散列文件结构。所以,是一种文件结构。
二.动态散列
这是一种从构建开始就与静态散列不同的散列技术。
首先来看静态散列存在的一个严重问题就是要固定桶地址集合,但是大多数数据库是随时间变大的,而三种解决方案也不尽人意:1.根据初始文件大小选择散列函数——未来的性能下降;2.根据预计文件大小选择散列函数——前期的空间浪费;3.周期性重组——重组期间数据库几乎不可用;
动态散列即允许散列函数动态改变,以适应数据库的增大或缩小。可扩展散列是其中一种: