Redis
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
安装及基本使用
wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar xzf redis-3.0.6.tar.gz cd redis-3.0.6 make # 启动服务端 src/redis-server # 启动客户端 src/redis-cli redis> set foo bar OK redis> get foo "bar"
python操作Redis
# 安装 $ sudo pip install redis or $ sudo easy_install redis or $ sudo python setup.py install
1.连接方式和连接池
Redis-py 提供两个类 Redis 和 StrictRedis 用于实现 Redis 的操作命令,StrictRedis 用于实现大部分官方的命令,并使用官方的语法和命令,Redis 是 StrictRedis 的子类,用于向后兼容旧版本的 Redis-py
import redis r = redis.Redis(host='192.168.1.5', port=6379) r.set('foo', 'Bar') print r.get('foo')
redis-py 使用 connection pool 来管理对一个 redis server 的所有连接,避免每次建立、释放连接带来的额外开销。默认每个 Redis 实例都会维护着一个自己的连接池。也可以覆盖直接建立一个连接池,然后作为参数 Redis,这样就可以实现多个 Redis 实例共享一个连接池资源。实现客户端分片或有连接如何管理更细的颗粒控制。
pool = redis.ConnectionPool(host='192.168.1.5', port=6379) r = redis.Redis(connection_pool=pool) r.set('foo', 'Bar') print r.get('foo')
2.操作
String 操作,String 在内存中格式是一个 name 对应一个 value 来存储
set(name,value,ex=None,px=None,nx=False,xx=False)
# 在Redis中设置值,默认,不存在则创建,存在则修改 # 参数: ex,过期时间(秒) px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
# 设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值 # 参数: time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值 # 参数: time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
# 批量设置值 # 如: mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'})
get(name)
# 获取值
mget(keys, *args)
# 批量获取 # 如: mget('ylr', 'nick') 或 r.mget(['ylr', 'nick'])
getset(name, value)
# 设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符) # 参数: name,Redis 的 name start,起始位置(字节) end,结束位置(字节) # 如: "索宁" ,0-3表示 "索"
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) # 参数: offset,字符串的索引,字节(一个汉字三个字节) value,要设置的值
setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作 # 参数: # name,redis的name # offset,位的索引(将值变换成二进制后再进行索引) # value,值只能是 1 或 0 # 注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数 # 参数: key,Redis的name start,位起始位置 end,位结束位置
bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值 # 参数: operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或) dest, 新的Redis的name *keys,要查找的Redis的name # 如: bitop("AND", 'new_name', 'n1', 'n2', 'n3') 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: name,Redis的name amount,自增数(必须是整数) # 注:同incrb
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: name,Redis的name amount,自增数(浮点型)
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数: name,Redis的name amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串
Hash 操作,redis 中 Hash 在内存中的存储格式类似字典
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: name,redis的name key,name对应的hash中的key value,name对应的hash中的value # 注: hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数: name,redis的name mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数: name,reids对应的name keys,要获取key集合,如:['k1', 'k2', 'k3'] *args,要获取的key,如:k1,k2,k3 # 如: r.mget('xx', ['k1', 'k2']) 或 print r.hmget('xx', 'k1', 'k2')
hgetall(name)
# 获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
自增name对应的hash中的指定key的值,不存在则创建key=amount 参数:
name,redis中的name
key, hash对应的key
amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter('xx'): # print item
List 操作,redis 中的 List 在在内存中按照一个 name 对应一个 List 来存储,像变量对应一个列表。
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如: # r.lpush('oo', 11,22,33) # 保存顺序为: 33,22,11 # 扩展: # rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多: # rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数: # name,redis的name # index,list的索引位置 # value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多: # rpop(name) 表示从右向左操作
lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 # 参数: # src,要取数据的列表的name # dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素 # 参数: # keys,redis的name的集合 # timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 # 更多: # r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧 # 参数: # src,取出并要移除元素的列表对应的name # dst,要插入元素的列表对应的name # timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要: # 1、获取name对应的所有列表 # 2、循环列表 # 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name): """ 自定义redis列表增量迭代 :param name: redis中的name,即:迭代name对应的列表 :return: yield 返回 列表元素 """ list_count = r.llen(name) for index in xrange(list_count): yield r.lindex(name, index) # 使用 for item in list_iter('pp'): print item
Set 操作,Set 集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素
scard(name)
# 获取name对应的集合中元素个数
sdiff(keys, *args)
# 在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args)
# 获取多一个name对应集合的并集
sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在集合的基础上,为每个元素排序;元素的排序需要根据另外一个值来进行比较,所以对于有序集合,每一个元素有两个值:值和分数,分数是专门来做排序的。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素 # 如: # zadd('zz', 'n1', 1, 'n2', 2) # 或 # zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 # 参数: # name,redis的name # start,有序集合索引起始位置(非分数) # end,有序集合索引结束位置(非分数) # desc,排序规则,默认按照分数从小到大排序 # withscores,是否获取元素的分数,默认只获取元素的值 # score_cast_func,对分数进行数据转换的函数 # 更多: # 从大到小排序 # zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素 # zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) # 从大到小排序 # zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始) # 更多: # zrevrank(name, value),从大到小排序
zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员 # 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大 # 参数: # name,redis的name # min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间 # min,右区间(值) # start,对结果进行分片处理,索引位置 # num,对结果进行分片处理,索引后面的num个元素 # 如: # ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga # r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca'] # 更多: # 从大到小排序 # zrevrangebylex(name, max, min, start=None, num=None)
zrem(name, values)
# 删除name对应的有序集合中值是values的成员 # 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zremrangebylex(name, min, max)
# 根据值返回删除
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
其它 常用操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name # 更多: # KEYS * 匹配数据库中所有 key 。 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
管道
默认情况下,redis-py 每次在执行请求时都会创建和断开一次连接操作(连接池申请连接,归还连接池),如果想要在一次请求中执行多个命令,则可以使用 pipline 实现一次请求执行多个命令,并且默认情况下 pipline 是原子性操作。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) r.set('name', 'nick') r.set('age', '18') pipe.execute()
发布和订阅
发布者:服务器
订阅者:Dashboad 和数据处理
发布订阅的 Demo 如下:


#!/usr/bin/env python # -*- coding:utf-8 -*- import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='10.211.55.4') self.chan_sub = 'fm104.5' self.chan_pub = 'fm104.5' def public(self, msg): self.__conn.publish(self.chan_pub, msg) return True def subscribe(self): pub = self.__conn.pubsub() pub.subscribe(self.chan_sub) pub.parse_response() return pub RedisHelper
订阅者:
#!/usr/bin/env python # -*- coding:utf-8 -*- from monitor.RedisHelper import RedisHelper obj = RedisHelper() redis_sub = obj.subscribe() while True: msg = redis_sub.parse_response() print(msg)
发布者:
#!/usr/bin/env python # -*- coding:utf-8 -*- from monitor.RedisHelper import RedisHelper obj = RedisHelper() obj.public('hello')
RabbitMQ
RabbitMQ 是信息传输的中间者。本质上,从生产者(producers)接收消息,转发这些消息给消费者(consumers)。换句话说,能够根据指定的规则进行消息转发,缓冲,和持久化
Windows下安装
下载Erlang,地址:http://www.erlang.org/download/otp_win32_R15B.exe ,双击安装即可(首先装) 下载RabbitMQ,地址:http://www.rabbitmq.com/releases/rabbitmq-server/v3.3.4/rabbitmq-server-3.3.4.exe ,双击安装即可 # python使用RabbitMQ, 使用python的类库 pika 下载pika, 地址: pip install -i pika http://pypi.douban.com/simple/
RabbitMQ之Windows环境启动
# 1、以应用方式启动 # 后台启动 rabbitmq-server -detached # 直接启动,如果你关闭窗口或者需要在改窗口使用其他命令时应用就会停止 Rabbitmq - server 关闭: rabbitmqctl stop # 2、以服务方式启动(安装完之后在任务管理器中服务一栏能看到RabbtiMq) rabbitmq-service install # 安装服务 rabbitmq-service start # 开始服务 Rabbitmq-service stop # 停止服务 Rabbitmq-service enable # 使服务有效 Rabbitmq-service disable # 使服务无效 rabbitmq-service help # 帮助 # 3、Rabbitmq管理插件启动 rabbitmq-plugins enable rabbitmq_management # 启动 rabbitmq-plugins disable rabbitmq_management # 关闭 # 4、Rabbitmq节点管理方式 rabbitmqctl # 查看队列 rabbitmqctl list_queues """ 当rabbitmq-service install之后默认服务是enable的, 如果这时设置服务为disable的话,rabbitmq-service start就会报错。 当rabbitmq-service start正常启动服务之后,使用disable是没有效果的 """
Linux下安装
安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server
注意:service rabbitmq-server start/stop
sudo rabbitmqctl add_user alex 123 # 设置用户为administrator角色 sudo rabbitmqctl set_user_tags alex administrator # 设置权限 sudo rabbitmqctl set_permissions -p "/" alex '.''.''.' # 然后重启rabbiMQ服务 sudo /etc/init.d/rabbitmq-server restart # 然后可以使用刚才的用户远程连接rabbitmq server了。 Linux添加radditmq User并设定权限方可登陆
A,基本操作
Windows
import pika # ######################### 生产者 ######################### # 连接到RabbitMQ服务器,本地测试使用localhost connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 建立了rabbit 协议的通道 # 声明queue channel.queue_declare(queue='hello') # 发送消息到上面声明的hello队列, # 其中exchange表示交换器,能精确指定消息应该发送到哪个队列, # routing_key设置为队列的名称,body就是发送的内容 channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close() sender.py
import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print("received msg...start processing....",body) time.sleep(20) print(" [x] msg process done....",body) channel.basic_consume(callback, queue='hello', no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
rabbitmqctl list_queues 服务端执行命令查看队列及消息
Linux
在windows下编写程序远程连接Liunx RabbitMQ服务
import pika credentials = pika.PlainCredentials('linux_username', 'linux_password') connection = pika.BlockingConnection(pika.ConnectionParameters( 'host_ip_addr', credentials=credentials)) channel = connection.channel() # 建立了rabbit 协议的通道 # 声明queue channel.queue_declare(queue='hello') # n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close() sender.py
import pika import time credentials = pika.PlainCredentials('linux_username', 'linux_password') connection = pika.BlockingConnection(pika.ConnectionParameters( 'host_ip_addr', credentials=credentials)) channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print("received msg...start processing....",body) time.sleep(20) print(" [x] msg process done....",body) channel.basic_consume(callback, queue='hello', no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
B,acknowledgment 消息反馈机制 确认(消息不丢失)
no-ack = False,如果消费者由于某些情况宕了,那 RabbitMQ 会重新将该任务放入队列中。
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑…..
import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print("received msg...start processing....",body) time.sleep(20) print(" [x] msg process done....", body) channel.basic_consume(callback, queue='hello', no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
ch.basic_ack(delivery_tag = method.delivery_tag)
去除no_ack=True参数或者设置为False也可以
消息确认就是当工作者完成任务后,会反馈给rabbitmq。修改worker.py中的回调函数:
def callback(ch, method, properties, body): print("received msg...start processing....",body) time.sleep(20) print(" [x] msg process done....", body) ch.basic_ack(delivery_tag=method.delivery_tag)
C,durable 消息持久化存储(队列,消息不丢失)
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储:
将队列(Queue)与消息(Message)都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果需要对这种小概率事件也要管理起来,那么要用到事务。由于这里仅为RabbitMQ的简单介绍,所以不讲解RabbitMQ相关的事务。
import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 建立了rabbit 协议的通道 # durable=True 声明持久化存储 channel.queue_declare(queue='task_queue', durable=True) channel.basic_publish(exchange='', routing_key='task_queue', body='Hello World!', # 在发送任务的时候,用delivery_mode=2来标记消息为持久化存储 properties=pika.BasicProperties( delivery_mode=2, )) print(" [x] Sent 'Hello World!'") connection.close() sender.py
import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) def callback(ch, method, properties, body): print("received msg...start processing....",body) time.sleep(20) print(" [x] msg process done....", body) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume( callback, queue='task_queue', no_ack=False # 默认为False ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
D,Fair dispatch(公平调度)
上面实例中,虽然每个工作者是依次分配到任务,但是每个任务不一定一样。可能有的任务比较重,执行时间比较久;有的任务比较轻,执行时间比较短。如果能公平调度就最好了,使用basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,即只有工作者完成任务之后,才会再次接收到任务。
import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) def callback(ch, method, properties, body): print("received msg...start processing....",body) time.sleep(20) print(" [x] msg process done....", body) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume( callback, queue='task_queue', no_ack=False # 默认为False ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
E,发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
如果需要将消息广播出去,让每个接收端都能收到,那么就要使用交换机。
交换机的工作原理:消息发送端先将消息发送给交换机,交换机再将消息发送到绑定的消息队列,而后每个接收端都能从各自的消息队列里接收到信息。
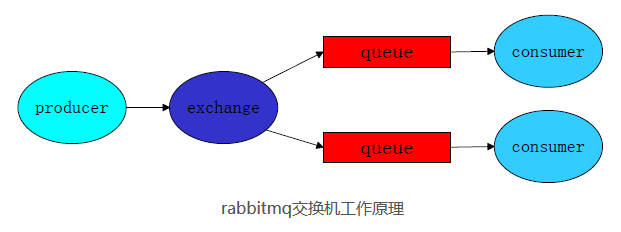
- exchange如果为空,表示是使用匿名的交换机。
- routing_key在使用匿名交换机的时候才需要指定,表示发送到哪个队列的意思。
转发器可分为三种类型,如下
I,fanout
白话来讲,类似于收听广播,具有实时性。
较于之前的sender.py,作了俩个改动
- 定义交换机
- 不是将消息发送到hello队列,而是发送到交换机
import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 定义交换机 channel.exchange_declare(exchange='messages', type='fanout') # 将消息发送到交换机 channel.basic_publish(exchange='messages', routing_key='', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close() sender.py
上示代码中, basic_publish方法的参数exchange被设定为相应交换机,因为是要广播出去,发送到所有队列,所以routing_key就不需要设定了。
rabbitmqctl list_exchanges 命令 来查看交换机信息
较于之前的recevie.py,也主要作了俩处改动
- 定义交换机
- 不使用hello队列了,随机生成一个临时队列,并绑定到交换机上
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel() # 定义交换机 channel.exchange_declare(exchange='messages', type='fanout') # 随机生成队列,并绑定到交换机上 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange='messages', queue=queue_name) def callback(ch, method, properties, body): print(" [x] Received %r" % (body,)) channel.basic_consume(callback, queue=queue_name, no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
上示代码中,queue_declare的参数exclusive=True表示当接收端退出时,销毁临时产生的队列,这样就不会占用资源。
打开另外一个终端,执行send.py,可以观察到receive.py接收到了消息。如果有多个终端执行receive.py,那么每个receive.py都会接收到消息。
II,direct
上述实例中,说明了关于交换机的使用,已经能实现给所有接收端发送消息,但是如果需要自由定制,有的消息发给其中一些接收端,有些消息发送给另外一些接收端,要怎么办呢?这种情况下就要用到路由键了。
路由键的工作原理:每个接收端的消息队列在绑定交换机的时候,可以设定相应的路由键。发送端通过交换机发送信息时,可以指明路由键 ,交换机会根据路由键把消息发送到相应的消息队列,这样接收端就能接收到消息了。
实例的功能: 将info、warning、error三种级别的信息发送到不同的接收端。
较于fanout类型send.py,作了俩处改动:
- 设定交换机的类型(type)为direct。上一篇是设置为fanout,表示广播的意思,会将消息发送到所有接收端,这里设置为direct表示要根据设定的路由键来发送消息。
- 发送信息时设置发送的路由键。
import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 定义交换机,设置类型为direct channel.exchange_declare(exchange='messages', type='direct') # 定义三个路由键 routings = ['info', 'warning', 'error'] # 将消息依次发送到交换机,并设置路由键 for routing in routings: message = '%s message.' % routing channel.basic_publish(exchange='messages', routing_key=routing, body=message) print(message) connection.close() send.py
较于fanout类型receive.py,作了三处改动:
- 设定交换机的类型(type)为direct。
- 增加命令行获取参数功能,参数即为路由键。
- 将队列绑定到交换机上时,设定路由键。
import pika, sys connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 定义交换机,设置类型为direct channel.exchange_declare(exchange='messages', type='direct') # 从命令行获取路由键参数,如果没有,则设置为info routings = sys.argv[1:] if not routings: routings = ['info'] # 生成临时队列,并绑定到交换机上,设置路由键 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue for routing in routings: channel.queue_bind(exchange='messages', queue=queue_name, routing_key=routing) def callback(ch, method, properties, body): print(" [x] Received %r" % (body,)) channel.basic_consume(callback, queue=queue_name, no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
打开两个终端,一个运行代码python receive.py info warning,表示只接收info和warning的消息。另外一个终端运行send.py,可以观察到接收终端只接收到了info和warning的消息。如果打开多个终端运行receive.py,并传入不同的路由键参数,可以观察到更明显的效果。
当接收端正在运行时,可以使用rabbitmqctl list_bindings来查看绑定情况。
III,topic
direct模式以将消息发送到相应的队列,这里的路由键是要完全匹配,比如info消息的只能发到路由键为info的消息队列。
路由键模糊匹配,就是可以使用正则表达式,和常用的正则表示式不同,这里的话“#”表示所有、全部的意思;“*”只匹配到一个词。
本次将不作比较了,通过上述俩种模式,此种模式相对容易理解
要进行路由键模糊匹配,所以交换机的类型要设置为topic,设置为topic,就可以使用#,*的匹配符号了。
import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 定义交换机,设置类型为topic channel.exchange_declare(exchange='messages', type='topic') # 定义路由键 定义了四种类型的消息 routings = ['happy.work', 'happy.life', 'sad.work', 'sad.life'] # 将消息依次发送到交换机,并设定路由键 for routing in routings: message = '%s message.' % routing channel.basic_publish(exchange='messages', routing_key=routing, body=message) print(message) connection.close() send.py
import pika, sys connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel() # 定义交换机,设置类型为topic channel.exchange_declare(exchange='messages', type='topic') # 从命令行获取路由参数,如果没有,则报错退出 routings = sys.argv[1:] if not routings: print('>>', sys.stderr, "Usage: %s [routing_key]..." % (sys.argv[0],)) exit() # 生成临时队列,并绑定到交换机上,设置路由键 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue for routing in routings: channel.queue_bind(exchange='messages', queue=queue_name, routing_key=routing) def callback(ch, method, properties, body): print(" [x] Received %r" % (body,)) channel.basic_consume(callback, queue=queue_name, no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() receive.py
执行流程
# 打开四个终端,一个运行如下,表示任何事情都可以和她说: python receive.py # # 另外一个终端 运行如下,表示可以和她分享开心的事: python receive.py happy.* # 第三个运行如下,表示工作上的事情可以和她分享: python receive.py *.work # 最后一个运行python send.py result
写在此模式最后:
1、发送信息时,如果不设置路由键,那么路由键设置为 * 的接收端是否能接收消息
发送信息时,如果不设置路由键,默认是表示广播出去,理论上所有接收端都可以收到消息,但是笔者试了下,路由键设置为"*"的接收端收不到任何消息。 只有发送消息时,设置路由键为一个词,路由键设置为"*"的接收端才能收到消息。在这里,每个词使用"."符号分开的。
2、发送消息时,如果路由键设置为 ..,那么路由键设置为 #.* 的接收端是否能接收到消息?如果发送消息时,路由键设置为一个词呢
经测试,ok
3、a.*.# 和 a.# 的区别
"a.#"只要字符串开头的一个词是a就可以了,比如a、a.haha、a.haha.haha。而这样的词是不行的,如abs、abc、abc.haha。 "a.*.#"必须要满足a.*的字符串才可以,比如a.、a.haha、a.haha.haha。而这样的词是不行的,如a。
F,远程结果返回(交互式)
前面的例子都有个共同点,就是发送端发送消息出去后没有结果返回。如果只是单纯发送消息,当然没有问题了,但是在实际中,常常会需要接收端将收到的消息进行处理之后,返回给发送端。
处理方法描述:发送端在发送信息前,产生一个接收消息的临时队列,该队列用来接收返回的结果。
DEMO1
假设有一个控制中心和一个计算节点,控制中心会将一个自然数N发送给计算节点,计算节点将N值加1后,返回给控制中心。这里用sender.py模拟控制中心,recevie.py模拟计算节点。
1 import pika 2 3 4 class Center(object): 5 def __init__(self): 6 self.connection = pika.BlockingConnection(pika.ConnectionParameters( 7 host='localhost')) 8 9 self.channel = self.connection.channel() 10 11 # 定义接收返回消息的队列 12 result = self.channel.queue_declare(exclusive=True) 13 self.callback_queue = result.method.queue 14 15 self.channel.basic_consume(self.on_response, 16 no_ack=True, 17 queue=self.callback_queue) 18 19 # 定义接收到返回消息的处理方法 20 def on_response(self, ch, method, props, body): 21 self.response = body 22 23 def request(self, n): 24 self.response = None 25 # 发送计算请求,并声明返回队列 26 self.channel.basic_publish(exchange='', 27 routing_key='compute_queue', 28 properties=pika.BasicProperties( 29 reply_to=self.callback_queue, 30 ), 31 body=str(n)) 32 # 接收返回的数据 33 while self.response is None: 34 self.connection.process_data_events() 35 return int(self.response) 36 37 38 center = Center() 39 40 print(" [x] Requesting increase(30)") 41 response = center.request(30) 42 print(" [.] Got %r" % (response,)) 43 44 sender.py
1 import pika, time 2 3 # 连接rabbitmq服务器 4 connection = pika.BlockingConnection(pika.ConnectionParameters( 5 host='localhost')) 6 channel = connection.channel() 7 8 # 定义队列 9 channel.queue_declare(queue='compute_queue') 10 print(' [*] Waiting for n') 11 12 13 # 将n值加1 14 def increase(n): 15 time.sleep(10) 16 return n + 1 17 18 19 # 定义接收到消息的处理方法 20 def request(ch, method, properties, body): 21 print(" [.] increase(%s)" % (body,)) 22 23 response = increase(int(body)) 24 25 # 将计算结果发送回控制中心 26 ch.basic_publish(exchange='', 27 routing_key=properties.reply_to, 28 body=str(response)) 29 ch.basic_ack(delivery_tag=method.delivery_tag) 30 31 32 channel.basic_qos(prefetch_count=1) 33 channel.basic_consume(request, queue='compute_queue') 34 35 channel.start_consuming() 36 37 receive.py
上例代码定义了接收返回数据的队列和处理方法,并且在发送请求的时候将该队列赋值给reply_to,在计算节点代码中就是通过这个参数来获取返回队列的。
DEMO2
假设有多个计算节点,控制中心开启多个线程,往这些计算节点发送数字,要求计算结果并返回,但是控制中心只开启了一个队列,所有线程都是从这个队列里获取消息,每个线程如何确定收到的消息就是该线程对应的呢?这个就是correlation id的用处了。correlation翻译成中文就是相互关联,也表达了这个意思。
correlation id运行原理:控制中心发送计算请求时设置correlation id,而后计算节点将计算结果,连同接收到的correlation id一起返回,这样控制中心就能通过correlation id来标识请求。其实correlation id也可以理解为请求的唯一标识码。