数据类型,字符编码
二进制:
定义:二进制数据是用0和1两个数码来表示的数。它的基数为2,进位规则是“逢二进一”,借位规则是“借一当二”.当前的计算机系统使用的基本上是二进制系统,数据在计算机中主要是以补码的形式存储的。计算机中的二进制则是一个非常微小的开关,用“开”来表示1,“关”来表示0。
由于计算机只能识别二进制,那么我们怎么把文字或者数字输出出来呢?这就引出了字符编码.最早的字符编码是ASCII码,前127位表示常用的字符.后面128位是扩展ASCII编码.
如:用二进制表示Nick
字符 十进制 二进制
N 78 1001110
i 105 1101001
c 99 1100011
k 107 1101011
所以Nick的二进制表示就是 01001110 01101001 01100011 01101011
好了.现在用ASCII表示英文和数字是没有问题了.那么问题来了,怎么输出中文呢?所以,中国自己编写了一套编码表GB2312,于1981-5-1实施,共7000多个字符汉字.
但是这套编码的汉字太少了.有些生僻字就无法显示了.于是在1995年,国家发布了GBK1.0兼容GB2312,共存储20000余个汉字,其中包括汉语和日语中的汉字.2000年的时候,国家又发布了GB18030编码表, 是对GBK1.0的扩展.覆盖了中文,日文,朝鲜语和少数民族文字.兼容GB2312和GBK1.0
每个国家都有自己的编码,但是互相不兼容.使用其他十分麻烦.因此unicode应运而生.
Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
UTF-8
可变长的字符编码.英文占用一个字节,汉字占用3个字节.其他生僻字符占用4-6个字符.
我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
当不知道字符编码的时候,可以用一个插件检测.chardet
在terminal中 输入pip3 install chardet 开始下载安装chardet
import chardet
result = chardet.detect(open(‘log.txt’, ‘rb).read())
print(result)
输出结果如下:
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
上面表示:log.txt的字符编码99%的可能是utf-8
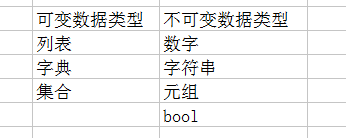
可变,不可变数据类型