一、文件下载介绍
这是一个展示图片的网页;

这是直接加载图片资源的网页,看网页的后缀名就知道了;

也能找到直接点击就可以下载的页面,就像PDF文件一样,有的是可以直接下载,而有的是被浏览器加载,然后再右键下载,不同的行为与不同的参数设定有关,下面就来具体展示如何下载一个文件。
掌握:(在设置中设置媒体文件的目录和URL,然后在与templates统计的目录下设置一个media文件夹,用于存放媒体文件)
# 添加流媒体文件 MEDIA_URL = '/media/' MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
设置好后,启动项目,就可以通过访问"http://XXX.XXX.XXX.XXX/media/filename.ext/"在请求媒体文件了。
二、文件下载操作
HTML

route

view function
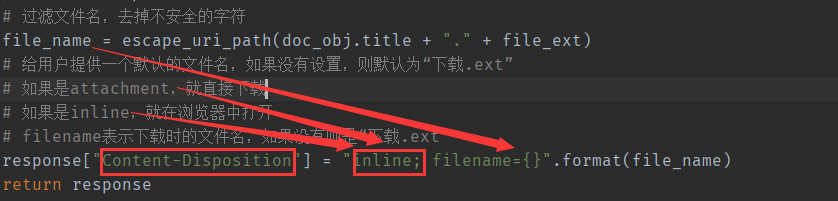
from django.shortcuts import render from .models import Doc from django.http import FileResponse, Http404 from dj32_test.settings import dev import requests import logging from django.utils.encoding import escape_uri_path logger = logging.getLogger("django") # Create your views here. def document(request): docs = Doc.objects.only("title", "desc", "image_url", "file_url", "id").filter(is_delete=False) return render(request, 'doc/docDownload.html', {"docs": docs}) def document_download(request, doc_id): doc_obj = Doc.objects.only("file_url", "title").filter(is_delete=False, id=doc_id).first() # 表明文档是否存在 if doc_obj: # 获取文件路径 file_url = doc_obj.file_url # 拼接成完整的url # BASE_URL为自定义设置,表示网站的域名 file_url = dev.BASE_SITE + file_url try: # 使用requests获取文件请求对象 # FileResponse会自动从response获取文件内容 response = FileResponse(requests.get(file_url, stream=True)) except requests.exceptions.ConnectionError as e: logging.error(e) response.status_code = 'Connection Refused' # 取得文件的后缀名 file_ext = file_url.split(".")[-1] if not file_ext: raise Http404("文件名异常") else: file_ext = file_ext.lower() # 检查文件后缀名,赋予对应的Content-Type if file_ext == "pdf": response["Content-Type"] = "application/pdf" elif file_ext == "doc": response["Content-Type"] = "application/msword" elif file_ext == "ppt" : response["Content-Type"] = "application/vnd.ms-powerpoint" else: raise Http404("文件格式错误") # 过滤文件名,去掉不安全的字符 file_name = escape_uri_path(doc_obj.title + "." + file_ext) # 给用户提供一个默认的文件名,如果没有设置,则默认为“下载.ext” # 如果是attachment,就直接下载 # 如果是inline,就在浏览器中打开 # filename表示下载时的文件名,如果没有则是“下载.ext” response["Content-Disposition"] = "inline; filename={}".format(file_name) return response else: raise Http404("Doc Not Found")
规范:
1、根据文件id到数据库中找到文件的路径,并拼接域名,得到文件的完整url;(有的文件是存放在本地的,有的是使用对象存储服务存储的)
2、使用requests库请求文件资源,获取response对象,传递给FileResponse,生成文件响应对象;
3、获取文件扩展名并检查是否存在,设置相应的Content-Type;
4、准备下载的文件名,去掉不安全的字符;
5、设置文件资源展示方式:直接下载、浏览器展示